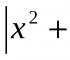Условни изрази CASE. Условни изрази CASE Изразът CASE е условен SQL израз
CASE израз
Функция DECODE
Използват се два метода:
Двата метода, които се използват за реализиране на условна обработка (IF-THEN-ELSE логика) в SQL израз, са изразът CASE и функцията DECODE.
Забележка: CASE изразът съответства на ANSI SQL. Функцията DECODE е специфична за синтаксиса на Oracle.
CASE израз
Опростява условните заявки, като прави оператора IF-THEN-ELSE да работи:
CASE изразите ви позволяват да използвате IF-THEN-ELSE логика в SQL изрази, без да се налага да извиквате процедури.
С просто условен изразСЛУЧАЙ Oracle Server търси първата WHEN ... THEN двойка, за която expr е равна на сравнение_expr и връща return_expr. Ако никоя от двойките WHEN ... THEN не отговаря на това условие и ако клаузата else съществува, Oracle връща else_expr. В противен случай Oracle връща null. Не можете да посочите NULL за всички return_exprs и else_expr.
Expr и сравнение_expr трябва да бъдат от един и същи тип данни, който може да бъде CHAR, VARCHAR2, NCHAR или NVARCHAR2. Всички върнати стойности (return_expr) трябва да бъдат от един и същи тип данни.
В този синтаксис Oracle сравнява входния израз (e) с всеки израз за сравнение e1, e2, ..., en.
Ако входният израз е равен на всеки израз за сравнение, изразът CASE връща съответния израз на резултата (r).
Ако входният израз e не съвпада с израз за сравнение, изразът CASE връща израза в клаузата ELSE, ако клаузата ELSE съществува, в противен случай връща нулева стойност.
Oracle използва оценка на късо съединение за простия израз CASE. Това означава, че Oracle оценява всеки израз за сравнение (e1, e2, .. en) само преди да сравнява един от тях с входния израз (e). Oracle не оценява всички изрази за сравнение, преди да сравнява някой от тях с израза (e). В резултат на това Oracle никога не оценява израз за сравнение, ако предишен е равен на входния израз (e).
Прост пример за израз на CASE
Ще използваме таблицата с продукти в демонстрацията.
Следващата заявка използва израза CASE за изчисляване на отстъпката за всяка продуктова категория, т.е. CPU 5%, видеокарта 10% и други категории продукти 8%
ИЗБЕРЕТЕ CASE category_id КОГА 1 ТОГА КРЪГ (list_price * 0.05,2) - CPU КОГА 2 ТОГА КРЪГ (List_price * 0,1,2) - Видео карта ИНШИ КРЪГЛИ (list_price * 0.08,2) - други категории END отстъпка ОТ ПОДРЕДЕНИ ПО |
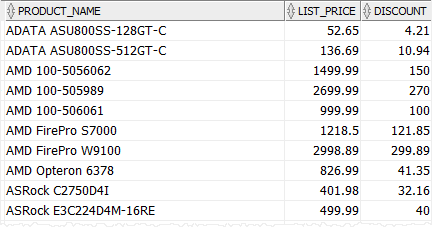
Имайте предвид, че използвахме функцията ROUND (), за да закръглим отстъпката до два знака след десетичната запетая.
Търсен израз CASE
Търсеният от Oracle израз CASE оценява списък с булеви изрази, за да определи резултата.
Търсеният израз CASE има следния синтаксис:
СЛУЧАЙ КОГА e1 ТОГАВА r1 , COUNT (DISTINCT DepartmentID) [Брой уникални отдели], COUNT (DISTINCT PositionID) [Брой уникални позиции], COUNT (BonusPercent) [Брой служители с% бонус], MAX (BonusPercent) [Maximum Bonus Percentage], MIN ( BonusPercent) [Минимален процент бонус], SUM (Заплата / 100 * BonusPercent) [Сума от всички бонуси], AVG (Заплата / 100 * BonusPercent) [Средна бонус], AVG (Заплата) [Средна заплата] ОТ Служители Нека да разгледаме как е възникнала всяка възвръщаема стойност, а за една да си припомним конструкциите на основния синтаксис на оператора SELECT. Първо, защото не посочихме КЪДЕ условията в заявката, тогава сумите ще бъдат изчислени за подробните данни, получени от заявката: ИЗБЕРЕТЕ * ОТ Служители Тези. за всички редове на таблицата Служители. За по-голяма яснота ще изберем само полетата и изразите, които се използват в обобщените функции: SELECT SELECTID, PositionID, BonusPercent, Заплата / 100 * BonusPercent, Заплата ОТ служители
Това са първоначалните данни (подробни редове), чрез които ще се изчисляват общите суми на обобщената заявка. Сега нека да разгледаме всяка обобщена стойност:
Нека обобщим някои от резултатите:
Съответно, когато се посочва допълнително условие с обобщени функции в клаузата WHERE, ще се изчисляват само сумите за редовете, които отговарят на условието. Тези. изчисляването на обобщените стойности се извършва за общия набор, който се получава с помощта на конструкцията SELECT. Например, нека направим същото, но само в контекста на ИТ отдела: ИЗБЕРЕТЕ БРОЙ (*) [Общ брой служители], БРОЙ (DISTINCT DepartmentID) [Брой уникални отдели], COUNT (DISTINCT PositionID) [Брой уникални позиции], COUNT (BonusPercent) [Брой служители с% бонус], MAX (BonusPercent) [Максимален процент бонус], MIN (BonusPercent) [Минимален процент бонус], SUM (Заплата / 100 * BonusPercent) [Сума от всички бонуси], AVG (Заплата / 100 * BonusPercent) [Среден размер на бонуса], AVG Заплата) [Средна заплата] ОТ служители, КЪДЕ DepartmentID = 3 - Помислете само за ИТ отдел SELECT SELECTID, PositionID, BonusPercent, Salary / 100 * BonusPercent, Salary ОТ Служители WHERE DepartmentID = 3 - включва само ИТ отдел
Продължавай. Ако агрегираната функция връща NULL (например, всички служители нямат стойност на Заплата), или в избора не е включен нито един запис, а в отчета за такъв случай трябва да покажем 0, тогава ISNULL функция може да обгърне обобщения израз: ИЗБЕРЕТЕ СУМА (Заплата), AVG (Заплата), - обработете общата сума, като използвате ISNULL ISNULL (SUM (Заплата), 0), ISNULL (AVG (Заплата), 0) ОТ служители WHERE DepartmentID = 10 - несъществуващ отдел е специално посочени тук, за да се предотврати връщането на запитванията на заявката
Вярвам, че е много важно да се разбере целта на всяка агрегирана функция и как те я изчисляват, защото в SQL, това е основният инструмент за изчисляване на суми. В този случай разгледахме как всяка агрегирана функция се държи независимо, т.е. той беше приложен към стойностите на целия набор от записи, получени от командата SELECT. След това ще разгледаме как същите тези функции се използват за изчисляване на общи суми с помощта на клаузата GROUP BY. GROUP BY - групиране на данниПреди това вече сме изчислили общи суми за определен отдел, приблизително както следва:SELECT COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (Salary) SalaryAmount FROM Служители WHERE DepartmentID = 3 - данни само за ИТ отдел А сега си представете, че ни помолиха да получим еднакви числа в контекста на всеки отдел. Разбира се, можем да запретнем ръкави и да изпълним една и съща заявка за всеки отдел. И така, веднага щом кажем, отколкото направим, пишем 4 заявки: ИЗБЕРЕТЕ "Административна" информация, COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (Salary) SalaryAmount FROM Служители WHERE DepartmentID = 1 - данни за администриране SELECT "Accounting" Информация, COUNT (DISTINCT PositionID) PositionCount, COUNT (* ) EmplCount, SUM (Заплата) SalaryAmount FROM Служители WHERE DepartmentID = 2 - Счетоводни данни ИЗБЕРЕТЕ "IT" информация, COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (Заплата) SalaryAmount ОТ Служители WHERE DepartmentID = 3 - данни за ИТ отдел ИЗБЕРЕТЕ „Друга“ информация, COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (Salary) SalaryAmount ОТ служители, КЪДЕ DepartmentID Е НУЛНА - и не забравяйте данни за фрийлансъри В резултат получаваме 4 набора от данни:
Моля, имайте предвид, че можем да използваме полета, посочени като константи - "Администриране", "Счетоводство", ... Като цяло извлекохме всички числа, които бяха поискани от нас, комбинираме всичко в Excel и го даваме на директора. Репортажът хареса доклада и той казва: „и добавете друга графа с информация за средната заплата“. И както винаги, това трябва да се направи много спешно. Хм, какво да правя ?! Освен това, нека си представим, че нашите отдели не са 3, а 15. Точно това е клаузата GROUP BY за такива случаи: ИЗБЕРЕТЕ ИДЕНТИФИКАТОР, БРОЙ (ИЗЯЗВАТЕЛНА ИДЕНТИФИКАЦИЯ) PositionCount, COUNT (*) EmplCount, SUM (Salary) SalaryAmount, AVG (Salary) SalaryAvg - плюс изпълняваме желанията на директора ОТ Служители ГРУПИРАНЕ ПО DepartmentID
Получихме едни и същи данни, но сега използваме само една заявка! Засега не обръщайте внимание на факта, че нашите отдели се показват под формата на цифри, тогава ще се научим как да показваме всичко красиво. В клаузата GROUP BY можете да посочите няколко полета "GROUP BY field1, field2, ..., fieldN", в този случай групирането ще се извърши по групи, които формират стойностите на тези полета "field1, field2, .. ., полеN ". Например, нека групираме данните по отдели и позиции: ИЗБЕРЕТЕ ID на отдел, позиция на ИД, БРОЙ (*) EmplCount, SUM (заплата) SalaryAmount ОТ служителите ИЗБЕРЕТЕ БРОЙ (*) EmplCount, SUM (Заплата) SalaryAmount ОТ служители, КЪДЕ DepartmentID Е НУЛНА И PositionID Е НУЛНА SELECT COUNT (*) EmplCount, SUM (Заплата) SalaryAmount ОТ Служители WHERE DepartmentID = 1 И PositionID = 2 - ... SELECT COUNT (*) EmplCount, SUM (Заплата) SalaryAmount FROM Служители WHERE DepartmentID = 3 И PositionID = 4 И тогава всички тези резултати се комбинират и ни се дават като един набор:
От основната, заслужава да се отбележи, че в случай на групиране (GROUP BY), в списъка с колони в блока SELECT:
И демонстрация на всичко казано: ИЗБЕРЕТЕ "String константа" Const1, - константа под формата на низ 1 Const2, - константа под формата на число - израз, използващ полетата, участващи в групата CONCAT ("No. No.", DepartmentID) ConstAndGroupField, CONCAT ("Department No. ", DepartmentID,", No. No. ", PositionID) ConstAndGroupFields, DepartmentID, - поле от списъка с полета, участващи в групирането - PositionID, - полето, участващо в групирането, не е необходимо да дублирате тук COUNT ( *) EmplCount, - брой редове във всяка група - останалите полета могат да се използват само с обобщени функции: COUNT, SUM, MIN, MAX, ... SUM (Заплата) SalaryAmount, MIN (ID) MINID ОТ Служители ГРУПА ПО DepartmentID , PositionID - групиране по полета DepartmentID, PositionID Също така си струва да се отбележи, че групирането може да се извършва не само по полета, но и чрез изрази. Например, нека групираме данните по служители по години на раждане: ИЗБЕРЕТЕ КОНКАТ ("Година на раждане -", ГОД (рожден ден)) YearOfBirthday, COUNT (*) EmplCount ОТ Служители ГРУПА ПО ГОДИНА (Рожден ден) Нека разгледаме пример с по-сложен израз. Например, нека вземем градацията на служителите по година на раждане: ИЗБЕРЕТЕ СЛУЧАЙ КОГА ГОДИНА (Рожден ден)> = 2000 ТОГАВА "от 2000" КОГА ГОДИНА (Рожден ден)> = 1990 ТОГАВА "1999-1990" КОГА ГОДИНА (Рожден ден)> = 1980 ТОГА "1989-1980" КОГА ГОДИНА (Рожден ден)> = 1970 ТОГАВА "1979-1970", КОГАТО рожденият ден НЕ Е НУЛЕН, ТОЙ "преди 1970" ИНШО "не е посочено" END RangeName, COUNT (*) EmplCount ОТ Служители ГРУПА ПО СЛУЧАЙ КОГА ГОДИНА (Рожден ден)> = 2000 THEN "от 2000" КОГА ГОДИНА (Рожден ден)> = 1990 ТОГАВА "1999-1990" КОГАТО ГОДИНА (Рожден ден)> = 1980 ТОГАВА "1989-1980" КОГА ГОДИНА (Рожден ден)> = 1970 ТОГАВА "1979-1970" КОГА РОЖДЕНИЯТ НЕ Е НУЛ ТОГА "преди 1970" ELSE "не е посочено" END
Тези. в този случай групирането се извършва според израза CASE, изчислен преди това за всеки служител: ИЗБЕРЕТЕ ИДЕНТИКА, СЛУЧАЙ КОГА ГОДИНА (Рожден ден)> = 2000 ТОГАВА "от 2000" КОГА ГОДИНА (Рожден ден)> = 1990 ТОГАВА "1999-1990" КОГА ГОДИНА (Рожден ден)> = 1980 ТОГА "1989-1980" КОГА ГОДИНА (Рожден ден) > = 1970 ТОГАВА "1979-1970", КОГАТО рожденият ден НЕ Е НИЩО "преди 1970 г." ИНАЧЕ "не е посочено" КРАЙ ОТ служителите
И разбира се, можете да комбинирате изрази с полета в блока GROUP BY: ИЗБЕРЕТЕ DepartmentID, CONCAT ("Година на раждане -", YEAR (Birthday)) YearOfBirthday, COUNT (*) EmplCount FROM Служители GROUP BY YEAR (Birthday), DepartmentID - поръчката може да не съвпада с реда на тяхното използване в SELECT ORDER Чрез блок DepartmentID, YearOfBirthday - накрая можем да приложим сортирането към резултата Да се върнем към първоначалната ни задача. Както вече знаем, директорът много хареса доклада и той ни помоли да го правим ежеседмично, за да може да следи промените в компанията. За да не прекъсваме всеки път в Excel числовата стойност на отдела по неговото име, ще използваме знанията, които вече имаме, и ще подобрим нашата заявка: ИЗБЕРЕТЕ СЛУЧАЙ DepartmentID КОГА 1 ТОГАВА "Администриране" КОГАТО 2 ТОГАВА "Счетоводство" КОГАТО 3 ТОГАВА "ИНАЧЕ" Друго "КРАЙ Информация, БРОЙ (ИЗЯЗВАТА PositionID) PositionCount, COUNT (*) EmplCount, SUM (Заплата) SalaryAmount, AVG (Plata ) SalaryAvg - плюс изпълняваме желанията на директора ОТ Служители ГРУПИРАЙТЕ ПО ОТДЕЛ ПОРЪЧКА ПО ИНФОРМАЦИЯ - добавете сортиране по колона Информация за повече удобство Но нищо, с времето ще се научим да правим всичко красиво, така че нашата извадка да не зависи от появата на нови данни в базата данни, а да е динамична. Ще тичам малко напред, за да покажа какви искания се опитваме да измислим: SELECT ISNULL (dep.Name, "Other") DepName, COUNT (DISTINCT emp.PositionID) PositionCount, COUNT (*) EmplCount, SUM (emp.Salary) SalaryAmount, AVG (emp.Salary) SalaryAvg - плюс изпълнете желанията на директор FROM Служители emp НАЛЯВО ПРИСЪЕДИНЯВАНЕ Отделите Dep ON emp.DepartmentID = dep.ID ГРУПА ПО emp.DepartmentID, dep.Name ПОРЪЧКА ПО DepName Като цяло, не се притеснявайте - всички започнаха просто. Засега просто трябва да разберете същността на клаузата GROUP BY. И накрая, нека видим как можете да създавате обобщени отчети, използвайки GROUP BY. Например, нека покажем обобщена таблица в контекста на отделите, така че общата заплата, получена от служителите по длъжност: ИЗБЕРЕТЕ DepartmentID, СУММА (СЛУЧАЙ, КОГАТО PositionID = 1 ТОГАВА Заплата END) [Счетоводители], SUM (CASE WHEN PositionID = 2 THEN Заплата END) [Директори], SUM (CASE WHEN PositionID = 3 THEN Заплата END) [Програмисти], SUM ( СЛУЧАЙ, КОГА PositionID = 4 THEN Заплата END) [Старши програмисти], SUM (Заплата) [Общо в отдел] ОТ служителите ГРУПА ПО отдел Можете, разбира се, да бъдете пренаписани с помощта на IIF: SELECT SELECTID, SUM (IIF (PositionID = 1, Заплата, NULL)) [Счетоводител], SUM (IIF (PositionID = 2, Заплата, NULL)) [Директори], SUM (IIF (PositionID = 3, Заплата, NULL)) [Програмисти], SUM (IIF (PositionID = 4, Заплата, NULL)) [Старши програмисти], SUM (Заплата) [Отдел общо] FROM Служители ГРУПИРАНЕ ПО DepartmentID Но в случай на IIF ще трябва изрично да посочим NULL, което се връща, ако условието не е изпълнено. В подобни случаи предпочитам да използвам CASE без ELSE блок, отколкото да пиша отново NULL. Но това със сигурност е въпрос на вкус, за който не се спори. И нека запомним, че NULL стойностите не се вземат предвид при агрегиращите функции. За да консолидирате, направете независим анализ на данните, получени от разширената заявка: SELECT SELECTID, CASE WHEN PositionID = 1 THEN Заплата END [Счетоводител], CASE WHEN PositionID = 2 THEN Заплата END [Директори], CASE WHEN PositionID = 3 THEN Заплата END [Програмисти], CASE WHEN PositionID = 4 THEN Заплата END [Старши програмисти ], Заплата [Отдел общо] ОТ служители
И нека също така помним, че ако вместо NULL искаме да видим нули, тогава можем да обработим стойността, върната от агрегатната функция. Например: SELECT SELECTID, ISNULL (SUM (IIF (PositionID = 1, Заплата, NULL)), 0) [Счетоводител], ISNULL (SUM (IIF (PositionID = 2, Заплата, NULL)), 0) [Директори], ISNULL (SUM (IIF (PositionID = 3, Заплата, NULL)), 0) [Програмисти], ISNULL (SUM (IIF (PositionID = 4, Заплата, NULL)), 0) [Старши програмисти], ISNULL (SUM (Заплата), 0 ) [Отдел общо] ОТ СЛУЖИТЕЛИ ГРУПА ПО ИД
GROUP BY, въпреки съвкупните функции, е един от основните инструменти, използвани за получаване на обобщени данни от базата данни, тъй като обикновено данните се използват в тази форма, тъй като обикновено се изисква да предоставяме обобщени отчети, а не подробни данни (листове). И разбира се, всичко се върти около познаването на основния дизайн, защото преди да обобщите (обобщите) нещо, първо трябва да го изберете правилно, като използвате „SELECT ... WHERE ...“. Тук практиката има важно място, следователно, ако си поставите за цел да разберете езика SQL, не да го научите, а да го разберете - практикувайте, практикувайте и практикувайте, преминавайки през най-различни опции, за които можете да се сетите. В началния етап, ако не сте сигурни в коректността на получените обобщени данни, направете подробна извадка, включително всички стойности, за които се извършва агрегирането. И проверете ръчността на изчисленията ръчно, като използвате тези подробни данни. В този случай използването на Excel може да бъде много полезно. Да приемем, че стигнахте до този моментДа кажем, че сте счетоводител С. С. Сидоров, който реши да се научи как да пише заявки SELECT.Да кажем, че вече сте приключили с четенето на този урок до този момент и вече сте уверени, че използвате всички горепосочени основни конструкции, т.е. можеш:
Да, но те не взеха предвид, че все още не можете да изграждате заявки от няколко таблици, а само от една, т.е. не знаете как да направите нещо подобно: SELECT emp. *, - връщане на всички полета на таблицата на служителите dep.Name DepartmentName, - добавяне на полето Name от таблицата Departments pos.Name PositionName към тези полета - и също добавяне на полето Name от таблицата Positions FROM Служители emp LEFT JOIN Отделения dep ON emp.DepartmentID = dep.ID LEFT JOIN Позиции pos ON emp.PositionID = pos.ID И така, как можете да се възползвате от настоящите си знания и да получите още по-продуктивни резултати?! Ще използваме силата на колективния ум - отиваме при програмистите, които работят за вас, т.е. на Андреев А.А., Петров П.П. или Николаев Н.Н., и помолете някой от тях да ви напише изглед (ВИЖДА или просто „Изглед“, за да ви разберат дори по-бързо), който освен основните полета от таблицата Служители ще върне и полета с „Наименование на отдела“ и „Заглавие на длъжността“, които липсват сега за седмичния отчет, който сте качили от Иванов II Защото обяснихте всичко правилно, след което ИТ специалистите веднага разбраха какво искат от тях и създадоха, специално за вас, изглед, наречен ViewEfficieesInfo. Представяме ви, че не виждате следващата команда, защото ИТ специалистите го правят: CREATE VIEW ViewEfficieesInfo AS SELECT emp. *, - връща всички полета на таблицата на служителите dep.Name DepartmentName, - добавя полето Name от Departments pos.Name PositionName таблица към тези полета - и също така добавя полето Name от таблицата Positions FROM Служители emp LEFT JOIN Отделите dep ON emp.DepartmentID = dep.ID LEFT JOIN Позиции pos ON emp.PositionID = pos.ID Тези. за вас всичко това, макар и страшно и неразбираемо, текстът остава извън екрана, а ИТ специалистите ви дават само името на изгледа „ViewEfficieesInfo“, който връща всички горепосочени данни (т.е. това, което сте поискали от тях). Вече можете да работите с този изглед като с обикновена таблица: ИЗБЕРЕТЕ * ОТ ViewEfficieesInfo ИЗБЕРЕТЕ ИМЕ на отдела, COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (Salary) SalaryAmount, AVG (Salary) SalaryAvg FROM ViewEfficieesInfo emp GROUP BY DepartmentID, DepartmentName ORDER BY DepartmentName Тези. за вас в този случай, сякаш нищо не се е променило, продължавате да работите с една таблица по същия начин (но по-правилно е да кажете с изгледа ViewEfficieesInfo), която връща всички данни, от които се нуждаете. Благодарение на помощта на ИТ специалисти, подробностите за копаенето на DepartmentName и PositionName остават в черна кутия за вас. Тези. изгледът ви изглежда по същия начин като обикновена таблица, помислете за разширена версия на таблицата на служителите. Например, нека също така формираме изявление, за да можете да се уверите, че всичко наистина е както казах (че цялата извадка идва от един изглед): ИЗБЕРЕТЕ ИДЕНТИФИКАТОР, Име, Заплата ОТ ViewEeeeeesInfo КЪДЕ Заплатата НЕ Е НУЛА И ЗАЛАТА> 0 ПОРЪЧКА ПО ИМЕ Използването на изгледи в някои случаи прави възможно значително разширяване на границите на потребители, които знаят как да пишат основни SELECT заявки. В този случай изгледът е плоска таблица с всички данни, от които потребителят се нуждае (за тези, които разбират OLAP, това може да се сравни с приближение на OLAP куб с факти и размери). Изрезка от Уикипедия.Въпреки че SQL беше замислен като инструмент за крайния потребител, в крайна сметка той стана толкова сложен, че се превърна в инструмент на програмист. Както можете да видите, скъпи потребители, езикът SQL първоначално е бил замислен като инструмент за вас. И така, всичко е във вашите ръце и желание, не пускайте. HAVING - налагане на условие за избор на групирани данниВсъщност, ако разбирате какво е групиране, тогава няма нищо сложно с HAVING. HAVING е донякъде подобен на WHERE, само ако условието WHERE се прилага към подробни данни, тогава условието HAVING се прилага към вече групираните данни. Поради тази причина в условията на блока HAVING можем да използваме или изрази с полета, включени в групирането, или изрази, затворени в агрегирани функции.Нека разгледаме пример: ИЗБЕРЕТЕ ИД на отдел, сума (заплата) Заплата сума от служители ГРУПА ПО отдел, имаща сума (заплата)> 3000
Тези. Това искане ни върна групираните данни само за онези отдели, за които общата заплата на всички служители надвишава 3000, т.е. "SUM (Заплата)> 3000".
Тези. тук на първо място се извършва групирането и се изчисляват данните за всички отдели: ИЗБЕРЕТЕ ID на отдел, сума (заплата) SalaryAmount FROM служители ГРУПИРАНЕ ПО IDID - 1. получаване на групирани данни за всички отдели И вече условието, посочено в блока HAVING, се прилага към тези данни: SELECT SELECTID, SUM (Заплата) SalaryAmount FROM Employees GROUP BY DepartmentID - 1. получаване на групирани данни за всички отдели HAVING SUM (Заплата)> 3000 - 2. условие за филтриране на групирани данни В условието HAVING можете също да изградите сложни условия, като използвате операторите AND, OR и NOT: ИЗБЕРЕТЕ ИД на отдел, сума (заплата) Заплата сума от служители ГРУПА ПО ИД на отдел, имаща сума (заплата)> 3000 И БРОЙ (*)<2 -- и число людей меньше 2-х
Както можете да видите тук, агрегатната функция (вижте "COUNT (*)") може да бъде посочена само в блока HAVING. Съответно можем да покажем само номера на отдела, който отговаря на условието HAVING: ИЗБЕРЕТЕ DepartmentID ОТ служителите ГРУПИРАНЕ ПО DepartmentID СЪС СУММА (Заплата)> 3000 И БРОЙ (*)<2 -- и число людей меньше 2-х Пример за използване на условието HAVING в поле, включено в GROUP BY: SELECT SELECTID, SUM (Заплата) SalaryAmount FROM Служители GROUP BY DepartmentID - 1. направете групирането HAVING DepartmentID = 3 - 2. филтрирайте резултата от групирането Това е само пример, тъй като в този случай би било по-логично да се провери чрез условие WHERE: ИЗБЕРЕТЕ DepartmentID, SUM (Заплата) SalaryAmount FROM Служители WHERE DepartmentID = 3 - 1. филтриране на подробни данни GROUP BY DepartmentID - 2. направете групиране само по избрани записи Тези. първо, филтрирайте служителите по отдел 3 и едва след това направете изчисление. Забележка.Всъщност, въпреки че двете заявки изглеждат различно, оптимизаторът на СУБД може да ги изпълнява по същия начин. Мисля, че тук може да приключи историята за ИМАЩИ условия. Нека обобщимНека обобщим данните, получени във втората и третата част и да разгледаме конкретното местоположение на всяка структура, която сме изследвали, и да посочим реда на тяхното изпълнение:
Разбира се, можете също да приложите клаузите DISTINCT и TOP, които сте научили в част втора, към групирани данни. Тези предложения в този случай се отнасят до крайния резултат: ИЗБЕРЕТЕ ТОП 1 - 6. ще приложи последната СУМА (Заплата) SalaryAmount FROM Служители ГРУПА ПО ОТДЕЛ ИМА СУМА (Заплата)> 3000 ПОРЪЧКА ПО ОТДЕЛ - 5. сортиране на резултата Анализирайте как тези резултати са получени сами. ЗаключениеОсновната цел, която си поставих в тази част, е да ви разкрия същността на съвкупните функции и групировки.Ако основният дизайн ни позволяваше да получим необходимите подробни данни, тогава прилагането на обобщени функции и групирания към тези подробни данни ни даде възможност да получим обобщени данни за тях. Така че, както виждате, тук всичко е важно, т.к. едното се основава на другото - без познаване на основната структура няма да можем, например, да изберем правилно данните, за които трябва да изчислим сумите. Тук умишлено се опитвам да покажа само основните неща, за да задържа вниманието на начинаещия върху най-важните конструкции и да не ги претоварвам с ненужна информация. Солидното разбиране на основните структури (за което ще продължа да говоря в следващите части) ще ви даде възможност да решите почти всеки проблем с извличането на данни от RDB. Основните конструкции на оператора SELECT са приложими в една и съща форма в почти всички СУБД (разликите се крият главно в детайлите, например в изпълнението на функции - за работа със низове, време и т.н.). Впоследствие солидното познаване на базата ще ви даде възможност лесно да научите различни разширения на езика SQL сами, като например:
Ако правите първите си стъпки в SQL, тогава се фокусирайте преди всичко върху изучаването на основните конструкции, тъй като ако притежавате базата, всичко останало ще бъде много по-лесно за вас да разберете и освен това сами. На първо място, трябва да разберете задълбочено възможностите на езика SQL, т.е. какъв вид операция обикновено позволява да се извърши върху данни. Предаването на информация на начинаещи в обемна форма е друга от причините, поради които ще покажа само най-важните (железни) структури. Успех в изучаването и разбирането на езика SQL. Част четвърта -
Какво ще бъде обсъдено в тази частВ тази част ще се запознаем:
CASE израз - условен израз на SQLТози оператор ви позволява да проверите условията и да върнете един или друг резултат, в зависимост от изпълнението на конкретно условие.Декларацията CASE има 2 форми: Да вземем пример за първата форма CASE: ИЗБЕРЕТЕ ИД, Име, Заплата, СЛУЧАЙ КОГА Заплата> = 3000 ТОГАВА "RFP> = 3000" КОГА Заплата> = 2000 ТОГА "2000<= ЗП < 3000"
ELSE "ЗП < 2000"
END SalaryTypeWithELSE,
CASE
WHEN Salary>= 3000 THEN "заплата> = 3000" WHEN Заплата> = 2000 THEN "2000<= ЗП < 3000"
END SalaryTypeWithoutELSE
FROM Employees
Ако не е изпълнено нито едно от условията WHEN, тогава се връща стойността, посочена след думата ELSE (което в този случай означава „ELSE RETURN ...“). Ако не е посочен блок ELSE и не са изпълнени условия WHEN, тогава се връща NULL. И в първата, и във втората форма блокът ELSE отива в самия край на структурата CASE, т.е. в края на краищата КОГА условия. Да вземем пример за втората форма CASE: Да предположим, че за новата година те решиха да възнаградят всички служители и поискаха да изчислят размера на бонусите по следната схема:
За тази задача използваме заявка с израз CASE: ИЗБЕРЕТЕ ИД, Име, Заплата, DepartmentID, - за по-голяма яснота показваме процента като ред CASE DepartmentID - проверената стойност КОГАТО 2 ТОГАВА "10%" - 10% от заплатата, която да издава на счетоводители КОГА 3 ТОГАВА "15%" - 15% от заплатата, за да я дадете на ИТ служителите ДРУГО "5%" - на всички останали 5% END NewYearBonusPercent, - нека изградим израз, използвайки CASE, за да видим размера на бонуса Заплата / 100 * CASE DepartmentID КОГАТО 2 THEN 10 - 10% от заплатата за издаване на счетоводители, КОГАТО 3 ТОГАВА 15 - 15% от заплатата за издаване на ИТ служители ДРУГО 5 - всички останали по 5% всяка КРАЙ Бонус сума от служители Съответно, стойността на блока ELSE се връща, ако DepartmentID не съвпада с никоя стойност WHEN. Ако няма блок ELSE, тогава ще бъде върната NULL, ако DepartmentID не съвпада с никоя стойност WHEN. Вторият формуляр CASE е лесен за представяне с помощта на първия формуляр: ИЗБЕРЕТЕ ИД, Име, Заплата, DepartmentID, CASE WHEN DepartmentID = 2 THEN "10%" - 10% от заплатата, която се издава на счетоводители WHEN DepartmentID = 3 THEN "15%" - 15% от заплатата, която трябва да се издаде на IT служители ELSE "5%" - всички останали 5% END NewYearBonusPercent, - изградете израз, използвайки CASE, за да видите размера на бонуса Заплата / 100 * CASE WHEN DepartmentID = 2 ТОГАВА 10 - 10% от заплатата, която да издавате на счетоводители WHEN DepartmentID = 3 ТОГАВА 15 - 15% от заплатата за издаване на ИТ служители ИНАЧЕ 5 - всички останали по 5% всеки КРАЙ Бонус Сума от служители Така че втората форма е просто опростена нотация за онези случаи, когато трябва да направим сравнение на равенството на една и съща тестова стойност с всяка стойност / израз WHEN. Забележка.Първата и втората форми на CASE са включени в езиковия стандарт SQL, така че най-вероятно те трябва да бъдат приложими в много СУБД. С MS SQL версия 2012 се появи опростен IIF формуляр за нотация. Може да се използва за опростяване на CASE оператор, когато се върнат само 2 стойности. Дизайнът на IIF е както следва: IIF (условие, true_value, false_value) Тези. всъщност това е обвивка за следната конструкция на CASE: CASE WHEN условие THEN true_value ИНАЧЕ false_value END Да видим пример: ИЗБЕРЕТЕ ИД, Име, Заплата, IIF (Заплата> = 2500, "Заплата> = 2500", "Заплата< 2500") DemoIIF, CASE WHEN Salary>= 2500 THEN "RFP> = 2500" ELSE "RFP< 2500" END DemoCASE FROM Employees CASE, IIF конструкциите могат да бъдат вложени една в друга. Нека разгледаме абстрактен пример: ИЗБЕРЕТЕ ИД, Име, Заплата, СЛУЧАЙ, КОГАТО DepartmentID В (1,2) ТОГАВА "A", КОГА Departmentid = 3 THEN CASE PositionID - вложен СЛУЧАЙ, КОГА 3 ТОГАВА "B-1", КОГАТО 4 THEN "B-2" КРАЙ ИНАЧ "END Demo1, IIF (DepartmentID IN (1,2)," A ", IIF (DepartmentID = 3, CASID PositionID WHEN 3 THEN" B-1 "WHEN 4 THEN" B-2 "END," C ")) Demo2 ОТ служители Тъй като конструкциите CASE и IIF са изрази, които връщат резултат, можем да ги използваме не само в блока SELECT, но и в други блокове, които позволяват използването на изрази, например в клаузите WHERE или ORDER BY. Например, нека ни бъде дадена задачата да създадем списък за раздаване на заплата, както следва:
Нека се опитаме да разрешим този проблем, като добавим израз CASE към блока ORDER BY: ИЗБЕРЕТЕ ИД, Име, Заплата ОТ СЛУЖИТЕЛИ ПОРЪЧКА ПО СЛУЧАЙ, КОГАТО Заплата> = 2500 ТОГАВА 1 ДРУГО 0 КРАЙ, - първо издайте заплата на тези, които са под 2500 Име - допълнително сортирайте списъка по реда на пълното име И абстрактен пример за използване на CASE в клауза WHERE: ИЗБЕРЕТЕ ИД, Име, Заплата ОТ Служители КЪДЕ СЛУЧАЙ КОГА Заплата> = 2500 ТОГАВА 1 ДРУГО 0 КРАЙ = 1 - всички записи, чийто израз е 1 Можете да опитате сами да повторите последните 2 примера с функцията IIF. И накрая, нека си припомним отново за NULL стойностите: ИЗБЕРЕТЕ ИД, Име, Заплата, DepartmentID, CASE WHEN DepartmentID = 2 THEN "10%" - 10% от заплатата, която да се издава на счетоводители WHEN DepartmentID = 3 THEN "15%" - да се издаде 15% от заплатата на ИТ служителите WHEN DepartmentID Е НУЛНО ТОГАВА "-" - ние не даваме бонуси на фрийлансъри (ние използваме IS NULL) ИНАЧЕ "5%" - всички останали имат по 5% всеки END NewYearBonusPercent1, - но не можете да проверите за NULL, не забравяйте какво беше казано за NULL във втората част на CASE DepartmentID - - проверена стойност WHEN 2 THEN "10%" WHEN 3 THEN "15%" WHEN NULL THEN "-" - !!! в този случай използването на втория формуляр CASE не е подходящо ДРУГО "5%" КРАЙ NewYearBonusPercent2 ОТ Служители ИЗБЕРЕТЕ ИД, Име, Заплата, DepartmentID, CASE ISNULL (DepartmentID, -1) - използвайте заместващия в случай NULL с -1 WHEN 2 THEN "10%" WHEN 3 THEN "15%" WHEN -1 THEN "-" - ако сме сигурни, че няма отдел с идентификатор, равен на (-1) и няма да има ELSE "5%" END NewYearBonusPercent3 FROM Служители Като цяло полетът на въображението в този случай не е ограничен. Например, нека видим как функцията ISNULL може да бъде моделирана с помощта на CASE и IIF: ИЗБЕРЕТЕ ИД, Име, Фамилия, ISNULL (Фамилия, "Неопределено") DemoISNULL, СЛУЧАЙ, КОГАТО LastName е NULL ТОГАВА "Неопределено" ELSE LastName END DemoCASE, IIF (LastName IS NULL, "Неопределено", LastName) DemoIIF ОТ Служители Конструкцията CASE е много мощна SQL функция, която ви позволява да наложите допълнителна логика за изчисляване на стойностите на набора от резултати. В тази част притежанието на CASE-конструкцията все още ще бъде полезно за нас, следователно в тази част, на първо място, е обърнато внимание на нея. Обобщени функцииТук ще разгледаме само основните и най-често използваните агрегирани функции:
Обобщените функции ни позволяват да изчислим общата стойност за набор от редове, получени с помощта на оператора SELECT. Нека разгледаме всяка функция с пример: ИЗБЕРЕТЕ БРОЙ (*) [Общ брой служители], БРОЙ (DISTINCT DepartmentID) [Брой уникални отдели], COUNT (DISTINCT PositionID) [Брой уникални позиции], COUNT (BonusPercent) [Брой служители с% бонус], MAX (BonusPercent) [Максимален бонус процент], MIN (BonusPercent) [Минимален бонус процент], SUM (Заплата / 100 * BonusPercent) [Сума от всички бонуси], AVG (Заплата / 100 * BonusPercent) [Среден размер на бонуса], AVG ( Заплата) [Средна заплата] ОТ служители Нека да разгледаме как е възникнала всяка възвръщаема стойност, а за една да си припомним конструкциите на основния синтаксис на оператора SELECT. Първо, защото не посочихме КЪДЕ условията в заявката, тогава сумите ще бъдат изчислени за подробните данни, получени от заявката: ИЗБЕРЕТЕ * ОТ Служители Тези. за всички редове на таблицата Служители. За по-голяма яснота ще изберем само полетата и изразите, които се използват в обобщените функции: SELECT SELECTID, PositionID, BonusPercent, Заплата / 100 * BonusPercent, Заплата ОТ служители
Това са първоначалните данни (подробни редове), чрез които ще се изчисляват общите суми на обобщената заявка. Сега нека да разгледаме всяка обобщена стойност:
Нека обобщим някои от резултатите:
Съответно, когато се посочва допълнително условие с обобщени функции в клаузата WHERE, ще се изчисляват само сумите за редовете, които отговарят на условието. Тези. изчисляването на обобщените стойности се извършва за общия набор, който се получава с помощта на конструкцията SELECT. Например, нека направим същото, но само в контекста на ИТ отдела: ИЗБЕРЕТЕ БРОЙ (*) [Общ брой служители], БРОЙ (DISTINCT DepartmentID) [Брой уникални отдели], COUNT (DISTINCT PositionID) [Брой уникални позиции], COUNT (BonusPercent) [Брой служители с% бонус], MAX (BonusPercent) [Максимален процент бонус], MIN (BonusPercent) [Минимален процент бонус], SUM (Заплата / 100 * BonusPercent) [Сума от всички бонуси], AVG (Заплата / 100 * BonusPercent) [Среден размер на бонуса], AVG Заплата) [Средна заплата] ОТ служители, КЪДЕ DepartmentID = 3 - Помислете само за ИТ отдел SELECT SELECTID, PositionID, BonusPercent, Salary / 100 * BonusPercent, Salary ОТ Служители WHERE DepartmentID = 3 - включва само ИТ отдел
Продължавай. Ако агрегираната функция връща NULL (например, всички служители нямат стойност на Заплата), или в избора не е включен нито един запис, а в отчета за такъв случай трябва да покажем 0, тогава ISNULL функция може да обгърне обобщения израз: ИЗБЕРЕТЕ СУМА (Заплата), AVG (Заплата), - обработете общата сума, като използвате ISNULL ISNULL (SUM (Заплата), 0), ISNULL (AVG (Заплата), 0) ОТ служители WHERE DepartmentID = 10 - несъществуващ отдел е специално посочени тук, за да се предотврати връщането на запитванията на заявката
Вярвам, че е много важно да се разбере целта на всяка агрегирана функция и как те я изчисляват, защото в SQL, това е основният инструмент за изчисляване на суми. В този случай разгледахме как всяка агрегирана функция се държи независимо, т.е. той беше приложен към стойностите на целия набор от записи, получени от командата SELECT. След това ще разгледаме как същите тези функции се използват за изчисляване на общи суми с помощта на клаузата GROUP BY. GROUP BY - групиране на данниПреди това вече сме изчислили общи суми за определен отдел, приблизително както следва:SELECT COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (Salary) SalaryAmount FROM Служители WHERE DepartmentID = 3 - данни само за ИТ отдел А сега си представете, че ни помолиха да получим еднакви числа в контекста на всеки отдел. Разбира се, можем да запретнем ръкави и да изпълним една и съща заявка за всеки отдел. И така, веднага щом кажем, отколкото направим, пишем 4 заявки: ИЗБЕРЕТЕ "Административна" информация, COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (Salary) SalaryAmount FROM Служители WHERE DepartmentID = 1 - данни за администриране SELECT "Accounting" Информация, COUNT (DISTINCT PositionID) PositionCount, COUNT (* ) EmplCount, SUM (Заплата) SalaryAmount FROM Служители WHERE DepartmentID = 2 - Счетоводни данни ИЗБЕРЕТЕ "IT" информация, COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (Заплата) SalaryAmount ОТ Служители WHERE DepartmentID = 3 - данни за ИТ отдел ИЗБЕРЕТЕ „Друга“ информация, COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (Salary) SalaryAmount ОТ служители, КЪДЕ DepartmentID Е НУЛНА - и не забравяйте данни за фрийлансъри В резултат получаваме 4 набора от данни:
Моля, имайте предвид, че можем да използваме полета, посочени като константи - "Администриране", "Счетоводство", ... Като цяло извлекохме всички числа, които бяха поискани от нас, комбинираме всичко в Excel и го даваме на директора. Репортажът хареса доклада и той казва: „и добавете друга графа с информация за средната заплата“. И както винаги, това трябва да се направи много спешно. Хм, какво да правя ?! Освен това, нека си представим, че нашите отдели не са 3, а 15. Точно това е клаузата GROUP BY за такива случаи: ИЗБЕРЕТЕ ИДЕНТИФИКАТОР, БРОЙ (ИЗЯЗВАТЕЛНА ИДЕНТИФИКАЦИЯ) PositionCount, COUNT (*) EmplCount, SUM (Salary) SalaryAmount, AVG (Salary) SalaryAvg - плюс изпълняваме желанията на директора ОТ Служители ГРУПИРАНЕ ПО DepartmentID
Получихме едни и същи данни, но сега използваме само една заявка! Засега не обръщайте внимание на факта, че нашите отдели се показват под формата на цифри, тогава ще се научим как да показваме всичко красиво. В клаузата GROUP BY можете да посочите няколко полета "GROUP BY field1, field2, ..., fieldN", в този случай групирането ще се извърши по групи, които формират стойностите на тези полета "field1, field2, .. ., полеN ". Например, нека групираме данните по отдели и позиции: ИЗБЕРЕТЕ ID на отдел, позиция на ИД, БРОЙ (*) EmplCount, SUM (заплата) SalaryAmount ОТ служителите ИЗБЕРЕТЕ БРОЙ (*) EmplCount, SUM (Заплата) SalaryAmount ОТ служители, КЪДЕ DepartmentID Е НУЛНА И PositionID Е НУЛНА SELECT COUNT (*) EmplCount, SUM (Заплата) SalaryAmount ОТ Служители WHERE DepartmentID = 1 И PositionID = 2 - ... SELECT COUNT (*) EmplCount, SUM (Заплата) SalaryAmount FROM Служители WHERE DepartmentID = 3 И PositionID = 4 И тогава всички тези резултати се комбинират и ни се дават като един набор:
От основната, заслужава да се отбележи, че в случай на групиране (GROUP BY), в списъка с колони в блока SELECT:
И демонстрация на всичко казано: ИЗБЕРЕТЕ "String константа" Const1, - константа под формата на низ 1 Const2, - константа под формата на число - израз, използващ полетата, участващи в групата CONCAT ("No. No.", DepartmentID) ConstAndGroupField, CONCAT ("Department No. ", DepartmentID,", No. No. ", PositionID) ConstAndGroupFields, DepartmentID, - поле от списъка с полета, участващи в групирането - PositionID, - полето, участващо в групирането, не е необходимо да дублирате тук COUNT ( *) EmplCount, - брой редове във всяка група - останалите полета могат да се използват само с обобщени функции: COUNT, SUM, MIN, MAX, ... SUM (Заплата) SalaryAmount, MIN (ID) MINID ОТ Служители ГРУПА ПО DepartmentID , PositionID - групиране по полета DepartmentID, PositionID Също така си струва да се отбележи, че групирането може да се извършва не само по полета, но и чрез изрази. Например, нека групираме данните по служители по години на раждане: ИЗБЕРЕТЕ КОНКАТ ("Година на раждане -", ГОД (рожден ден)) YearOfBirthday, COUNT (*) EmplCount ОТ Служители ГРУПА ПО ГОДИНА (Рожден ден) Нека разгледаме пример с по-сложен израз. Например, нека вземем градацията на служителите по година на раждане: ИЗБЕРЕТЕ СЛУЧАЙ КОГА ГОДИНА (Рожден ден)> = 2000 ТОГАВА "от 2000" КОГА ГОДИНА (Рожден ден)> = 1990 ТОГАВА "1999-1990" КОГА ГОДИНА (Рожден ден)> = 1980 ТОГА "1989-1980" КОГА ГОДИНА (Рожден ден)> = 1970 ТОГАВА "1979-1970", КОГАТО рожденият ден НЕ Е НУЛЕН, ТОЙ "преди 1970" ИНШО "не е посочено" END RangeName, COUNT (*) EmplCount ОТ Служители ГРУПА ПО СЛУЧАЙ КОГА ГОДИНА (Рожден ден)> = 2000 THEN "от 2000" КОГА ГОДИНА (Рожден ден)> = 1990 ТОГАВА "1999-1990" КОГАТО ГОДИНА (Рожден ден)> = 1980 ТОГАВА "1989-1980" КОГА ГОДИНА (Рожден ден)> = 1970 ТОГАВА "1979-1970" КОГА РОЖДЕНИЯТ НЕ Е НУЛ ТОГА "преди 1970" ELSE "не е посочено" END
Тези. в този случай групирането се извършва според израза CASE, изчислен преди това за всеки служител: ИЗБЕРЕТЕ ИДЕНТИКА, СЛУЧАЙ КОГА ГОДИНА (Рожден ден)> = 2000 ТОГАВА "от 2000" КОГА ГОДИНА (Рожден ден)> = 1990 ТОГАВА "1999-1990" КОГА ГОДИНА (Рожден ден)> = 1980 ТОГА "1989-1980" КОГА ГОДИНА (Рожден ден) > = 1970 ТОГАВА "1979-1970", КОГАТО рожденият ден НЕ Е НИЩО "преди 1970 г." ИНАЧЕ "не е посочено" КРАЙ ОТ служителите
И разбира се, можете да комбинирате изрази с полета в блока GROUP BY: ИЗБЕРЕТЕ DepartmentID, CONCAT ("Година на раждане -", YEAR (Birthday)) YearOfBirthday, COUNT (*) EmplCount FROM Служители GROUP BY YEAR (Birthday), DepartmentID - поръчката може да не съвпада с реда на тяхното използване в SELECT ORDER Чрез блок DepartmentID, YearOfBirthday - накрая можем да приложим сортирането към резултата Да се върнем към първоначалната ни задача. Както вече знаем, директорът много хареса доклада и той ни помоли да го правим ежеседмично, за да може да следи промените в компанията. За да не прекъсваме всеки път в Excel числовата стойност на отдела по неговото име, ще използваме знанията, които вече имаме, и ще подобрим нашата заявка: ИЗБЕРЕТЕ СЛУЧАЙ DepartmentID КОГА 1 ТОГАВА "Администриране" КОГАТО 2 ТОГАВА "Счетоводство" КОГАТО 3 ТОГАВА "ИНАЧЕ" Друго "КРАЙ Информация, БРОЙ (ИЗЯЗВАТА PositionID) PositionCount, COUNT (*) EmplCount, SUM (Заплата) SalaryAmount, AVG (Plata ) SalaryAvg - плюс изпълняваме желанията на директора ОТ Служители ГРУПИРАЙТЕ ПО ОТДЕЛ ПОРЪЧКА ПО ИНФОРМАЦИЯ - добавете сортиране по колона Информация за повече удобство Но нищо, с времето ще се научим да правим всичко красиво, така че нашата извадка да не зависи от появата на нови данни в базата данни, а да е динамична. Ще тичам малко напред, за да покажа какви искания се опитваме да измислим: SELECT ISNULL (dep.Name, "Other") DepName, COUNT (DISTINCT emp.PositionID) PositionCount, COUNT (*) EmplCount, SUM (emp.Salary) SalaryAmount, AVG (emp.Salary) SalaryAvg - плюс изпълнете желанията на директор FROM Служители emp НАЛЯВО ПРИСЪЕДИНЯВАНЕ Отделите Dep ON emp.DepartmentID = dep.ID ГРУПА ПО emp.DepartmentID, dep.Name ПОРЪЧКА ПО DepName Като цяло, не се притеснявайте - всички започнаха просто. Засега просто трябва да разберете същността на клаузата GROUP BY. И накрая, нека видим как можете да създавате обобщени отчети, използвайки GROUP BY. Например, нека покажем обобщена таблица в контекста на отделите, така че общата заплата, получена от служителите по длъжност: ИЗБЕРЕТЕ DepartmentID, СУММА (СЛУЧАЙ, КОГАТО PositionID = 1 ТОГАВА Заплата END) [Счетоводители], SUM (CASE WHEN PositionID = 2 THEN Заплата END) [Директори], SUM (CASE WHEN PositionID = 3 THEN Заплата END) [Програмисти], SUM ( СЛУЧАЙ, КОГА PositionID = 4 THEN Заплата END) [Старши програмисти], SUM (Заплата) [Общо в отдел] ОТ служителите ГРУПА ПО отдел Можете, разбира се, да бъдете пренаписани с помощта на IIF: SELECT SELECTID, SUM (IIF (PositionID = 1, Заплата, NULL)) [Счетоводител], SUM (IIF (PositionID = 2, Заплата, NULL)) [Директори], SUM (IIF (PositionID = 3, Заплата, NULL)) [Програмисти], SUM (IIF (PositionID = 4, Заплата, NULL)) [Старши програмисти], SUM (Заплата) [Отдел общо] FROM Служители ГРУПИРАНЕ ПО DepartmentID Но в случай на IIF ще трябва изрично да посочим NULL, което се връща, ако условието не е изпълнено. В подобни случаи предпочитам да използвам CASE без ELSE блок, отколкото да пиша отново NULL. Но това със сигурност е въпрос на вкус, за който не се спори. И нека запомним, че NULL стойностите не се вземат предвид при агрегиращите функции. За да консолидирате, направете независим анализ на данните, получени от разширената заявка: SELECT SELECTID, CASE WHEN PositionID = 1 THEN Заплата END [Счетоводител], CASE WHEN PositionID = 2 THEN Заплата END [Директори], CASE WHEN PositionID = 3 THEN Заплата END [Програмисти], CASE WHEN PositionID = 4 THEN Заплата END [Старши програмисти ], Заплата [Отдел общо] ОТ служители
И нека също така помним, че ако вместо NULL искаме да видим нули, тогава можем да обработим стойността, върната от агрегатната функция. Например: SELECT SELECTID, ISNULL (SUM (IIF (PositionID = 1, Заплата, NULL)), 0) [Счетоводител], ISNULL (SUM (IIF (PositionID = 2, Заплата, NULL)), 0) [Директори], ISNULL (SUM (IIF (PositionID = 3, Заплата, NULL)), 0) [Програмисти], ISNULL (SUM (IIF (PositionID = 4, Заплата, NULL)), 0) [Старши програмисти], ISNULL (SUM (Заплата), 0 ) [Отдел общо] ОТ СЛУЖИТЕЛИ ГРУПА ПО ИД
GROUP BY, въпреки съвкупните функции, е един от основните инструменти, използвани за получаване на обобщени данни от базата данни, тъй като обикновено данните се използват в тази форма, тъй като обикновено се изисква да предоставяме обобщени отчети, а не подробни данни (листове). И разбира се, всичко се върти около познаването на основния дизайн, защото преди да обобщите (обобщите) нещо, първо трябва да го изберете правилно, като използвате „SELECT ... WHERE ...“. Тук практиката има важно място, следователно, ако си поставите за цел да разберете езика SQL, не да го научите, а да го разберете - практикувайте, практикувайте и практикувайте, преминавайки през най-различни опции, за които можете да се сетите. В началния етап, ако не сте сигурни в коректността на получените обобщени данни, направете подробна извадка, включително всички стойности, за които се извършва агрегирането. И проверете ръчността на изчисленията ръчно, като използвате тези подробни данни. В този случай използването на Excel може да бъде много полезно. Да приемем, че стигнахте до този моментДа кажем, че сте счетоводител С. С. Сидоров, който реши да се научи как да пише заявки SELECT.Да кажем, че вече сте приключили с четенето на този урок до този момент и вече сте уверени, че използвате всички горепосочени основни конструкции, т.е. можеш:
Да, но те не взеха предвид, че все още не можете да изграждате заявки от няколко таблици, а само от една, т.е. не знаете как да направите нещо подобно: SELECT emp. *, - връщане на всички полета на таблицата на служителите dep.Name DepartmentName, - добавяне на полето Name от таблицата Departments pos.Name PositionName към тези полета - и също добавяне на полето Name от таблицата Positions FROM Служители emp LEFT JOIN Отделения dep ON emp.DepartmentID = dep.ID LEFT JOIN Позиции pos ON emp.PositionID = pos.ID И така, как можете да се възползвате от настоящите си знания и да получите още по-продуктивни резултати?! Ще използваме силата на колективния ум - отиваме при програмистите, които работят за вас, т.е. на Андреев А.А., Петров П.П. или Николаев Н.Н., и помолете някой от тях да ви напише изглед (ВИЖДА или просто „Изглед“, за да ви разберат дори по-бързо), който освен основните полета от таблицата Служители ще върне и полета с „Наименование на отдела“ и „Заглавие на длъжността“, които липсват сега за седмичния отчет, който сте качили от Иванов II Защото обяснихте всичко правилно, след което ИТ специалистите веднага разбраха какво искат от тях и създадоха, специално за вас, изглед, наречен ViewEfficieesInfo. Представяме ви, че не виждате следващата команда, защото ИТ специалистите го правят: CREATE VIEW ViewEfficieesInfo AS SELECT emp. *, - връща всички полета на таблицата на служителите dep.Name DepartmentName, - добавя полето Name от Departments pos.Name PositionName таблица към тези полета - и също така добавя полето Name от таблицата Positions FROM Служители emp LEFT JOIN Отделите dep ON emp.DepartmentID = dep.ID LEFT JOIN Позиции pos ON emp.PositionID = pos.ID Тези. за вас всичко това, макар и страшно и неразбираемо, текстът остава извън екрана, а ИТ специалистите ви дават само името на изгледа „ViewEfficieesInfo“, който връща всички горепосочени данни (т.е. това, което сте поискали от тях). Вече можете да работите с този изглед като с обикновена таблица: ИЗБЕРЕТЕ * ОТ ViewEfficieesInfo ИЗБЕРЕТЕ ИМЕ на отдела, COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (Salary) SalaryAmount, AVG (Salary) SalaryAvg FROM ViewEfficieesInfo emp GROUP BY DepartmentID, DepartmentName ORDER BY DepartmentName Тези. за вас в този случай, сякаш нищо не се е променило, продължавате да работите с една таблица по същия начин (но по-правилно е да кажете с изгледа ViewEfficieesInfo), която връща всички данни, от които се нуждаете. Благодарение на помощта на ИТ специалисти, подробностите за копаенето на DepartmentName и PositionName остават в черна кутия за вас. Тези. изгледът ви изглежда по същия начин като обикновена таблица, помислете за разширена версия на таблицата на служителите. Например, нека също така формираме изявление, за да можете да се уверите, че всичко наистина е както казах (че цялата извадка идва от един изглед): ИЗБЕРЕТЕ ИДЕНТИФИКАТОР, Име, Заплата ОТ ViewEeeeeesInfo КЪДЕ Заплатата НЕ Е НУЛА И ЗАЛАТА> 0 ПОРЪЧКА ПО ИМЕ Използването на изгледи в някои случаи прави възможно значително разширяване на границите на потребители, които знаят как да пишат основни SELECT заявки. В този случай изгледът е плоска таблица с всички данни, от които потребителят се нуждае (за тези, които разбират OLAP, това може да се сравни с приближение на OLAP куб с факти и размери). Изрезка от Уикипедия.Въпреки че SQL беше замислен като инструмент за крайния потребител, в крайна сметка той стана толкова сложен, че се превърна в инструмент на програмист. Както можете да видите, скъпи потребители, езикът SQL първоначално е бил замислен като инструмент за вас. И така, всичко е във вашите ръце и желание, не пускайте. HAVING - налагане на условие за избор на групирани данниВсъщност, ако разбирате какво е групиране, тогава няма нищо сложно с HAVING. HAVING е донякъде подобен на WHERE, само ако условието WHERE се прилага към подробни данни, тогава условието HAVING се прилага към вече групираните данни. Поради тази причина в условията на блока HAVING можем да използваме или изрази с полета, включени в групирането, или изрази, затворени в агрегирани функции.Нека разгледаме пример: ИЗБЕРЕТЕ ИД на отдел, сума (заплата) Заплата сума от служители ГРУПА ПО отдел, имаща сума (заплата)> 3000
Тези. Това искане ни върна групираните данни само за онези отдели, за които общата заплата на всички служители надвишава 3000, т.е. "SUM (Заплата)> 3000".
Тези. тук на първо място се извършва групирането и се изчисляват данните за всички отдели: ИЗБЕРЕТЕ ID на отдел, сума (заплата) SalaryAmount FROM служители ГРУПИРАНЕ ПО IDID - 1. получаване на групирани данни за всички отдели И вече условието, посочено в блока HAVING, се прилага към тези данни: SELECT SELECTID, SUM (Заплата) SalaryAmount FROM Employees GROUP BY DepartmentID - 1. получаване на групирани данни за всички отдели HAVING SUM (Заплата)> 3000 - 2. условие за филтриране на групирани данни В условието HAVING можете също да изградите сложни условия, като използвате операторите AND, OR и NOT: ИЗБЕРЕТЕ ИД на отдел, сума (заплата) Заплата сума от служители ГРУПА ПО ИД на отдел, имаща сума (заплата)> 3000 И БРОЙ (*)<2 -- и число людей меньше 2-х
Както можете да видите тук, агрегатната функция (вижте "COUNT (*)") може да бъде посочена само в блока HAVING. Съответно можем да покажем само номера на отдела, който отговаря на условието HAVING: ИЗБЕРЕТЕ DepartmentID ОТ служителите ГРУПИРАНЕ ПО DepartmentID СЪС СУММА (Заплата)> 3000 И БРОЙ (*)<2 -- и число людей меньше 2-х Пример за използване на условието HAVING в поле, включено в GROUP BY: SELECT SELECTID, SUM (Заплата) SalaryAmount FROM Служители GROUP BY DepartmentID - 1. направете групирането HAVING DepartmentID = 3 - 2. филтрирайте резултата от групирането Това е само пример, тъй като в този случай би било по-логично да се провери чрез условие WHERE: ИЗБЕРЕТЕ DepartmentID, SUM (Заплата) SalaryAmount FROM Служители WHERE DepartmentID = 3 - 1. филтриране на подробни данни GROUP BY DepartmentID - 2. направете групиране само по избрани записи Тези. първо, филтрирайте служителите по отдел 3 и едва след това направете изчисление. Забележка.Всъщност, въпреки че двете заявки изглеждат различно, оптимизаторът на СУБД може да ги изпълнява по същия начин. Мисля, че тук може да приключи историята за ИМАЩИ условия. Нека обобщимНека обобщим данните, получени във втората и третата част и да разгледаме конкретното местоположение на всяка структура, която сме изследвали, и да посочим реда на тяхното изпълнение:
Разбира се, можете също да приложите клаузите DISTINCT и TOP, които сте научили в част втора, към групирани данни. Тези предложения в този случай се отнасят до крайния резултат: ИЗБЕРЕТЕ ТОП 1 - 6. ще приложи последната СУМА (Заплата) SalaryAmount FROM Служители ГРУПА ПО ОТДЕЛ ИМА СУМА (Заплата)> 3000 ПОРЪЧКА ПО ОТДЕЛ - 5. сортиране на резултата Анализирайте как тези резултати са получени сами. ЗаключениеОсновната цел, която си поставих в тази част, е да ви разкрия същността на съвкупните функции и групировки.Ако основният дизайн ни позволяваше да получим необходимите подробни данни, тогава прилагането на обобщени функции и групирания към тези подробни данни ни даде възможност да получим обобщени данни за тях. Така че, както виждате, тук всичко е важно, т.к. едното се основава на другото - без познаване на основната структура няма да можем, например, да изберем правилно данните, за които трябва да изчислим сумите. Тук умишлено се опитвам да покажа само основните неща, за да задържа вниманието на начинаещия върху най-важните конструкции и да не ги претоварвам с ненужна информация. Солидното разбиране на основните структури (за което ще продължа да говоря в следващите части) ще ви даде възможност да решите почти всеки проблем с извличането на данни от RDB. Основните конструкции на оператора SELECT са приложими в една и съща форма в почти всички СУБД (разликите се крият главно в детайлите, например в изпълнението на функции - за работа със низове, време и т.н.). Впоследствие солидното познаване на базата ще ви даде възможност лесно да научите различни разширения на езика SQL сами, като например:
Ако правите първите си стъпки в SQL, тогава се фокусирайте преди всичко върху изучаването на основните конструкции, тъй като ако притежавате базата, всичко останало ще бъде много по-лесно за вас да разберете и освен това сами. На първо място, трябва да разберете задълбочено възможностите на езика SQL, т.е. какъв вид операция обикновено позволява да се извърши върху данни. Предаването на информация на начинаещи в обемна форма е друга от причините, поради които ще покажа само най-важните (железни) структури. Успех в изучаването и разбирането на езика SQL. Част четвърта - Екип CASE ви позволява да избирате за единна множество командни последователности... Тази конструкция присъства в SQL стандарта от 1992 г., въпреки че не се поддържа в Oracle SQL до Oracle8i и в PL / SQL до Oracle9i Release 1. Започвайки с тази версия, се поддържат следните разновидности на CASE команди:
NULL или UNKNOWN?В статията за оператора IF може да сте научили, че резултатът от булев израз може да бъде TRUE, FALSE или NULL. В PL / SQL това е вярно, но в по-широкия контекст на релационната теория се счита за неправилно да се говори за връщане на NULL от булев израз. Релационната теория казва, че сравненията с NULL са такива: 2 < NULL дава логическия резултат UNKNOWN, а UNKNOWN не е NULL. Не трябва обаче да се притеснявате твърде много за използването на PL / SQL на NULL за UNKNOWN. Трябва обаче да знаете, че третата стойност в 3-стойната логика е НЕИЗВЕСТНА. И се надявам, че никога (както направих!) Не попаднахте в грешен термин, когато обсъждате 3-стойностна логика с експерти в областта на релационната теория. В допълнение към командите CASE, PL / SQL също поддържа изрази CASE. Този израз е много подобен на командата CASE, той ви позволява да изберете един или повече изрази за оценка. Резултатът от CASE израз е една стойност, докато резултатът от CASE команда е изпълнението на последователност от PL / SQL команди. Прости CASE командиЕдна проста команда CASE ви позволява да изберете една от няколко последователности от PL / SQL команди, които да се изпълняват въз основа на резултата от оценката на израз. Пише се по следния начин: CASE израз WHEN резултат_1 THEN команда_1 WHEN резултат_2 THEN команда_2 ... ELSE command_else END CASE; Клонът ELSE тук не е задължителен. Когато изпълнява такава команда, PL / SQL първо оценява израза и след това сравнява резултата с result_1. Ако те съвпадат, командите_1 се изпълняват. В противен случай се проверява стойността result_2 и т.н. Ето пример за проста команда CASE, в която бонусът се изчислява в зависимост от стойността на променливата staff_type: СЛУЧАЙ тип_работник_КОГАТО "S" ТОГА награда_заплатен_бонус (служител_ид); КОГА "H" ТОГА награда_часов_бонус (идентификатор на служител); КОГА "C" ТОГА награда_комисионна_бонус (служител_ид); ELSE RAISE invalid_employee_type; КРАЙНО СЛУЧАЙ; В този пример има изрична клауза ELSE, но като цяло тя не се изисква. Без клауза ELSE, компилаторът PL / SQL имплицитно замества следния код: ИНШЕ ВДИГАНЕ CASE_NOT_FOUND; С други думи, ако пропуснете ключовата дума ELSE и ако нито един от резултатите в клаузите WHEN не съвпада с резултата от израза в командата CASE, PL / SQL поражда изключение CASE_NOT_FOUND. Това е разликата между тази команда и IF. Когато в командата IF липсва ключовата дума ELSE, нищо не се случва, ако условието не е изпълнено, докато в командата CASE подобна ситуация води до грешка. Ще бъде интересно да видим как да приложим логиката за изчисляване на бонуса, описана в началото на главата, използвайки проста команда CASE. На пръв поглед това изглежда невъзможно, но пристъпвайки творчески към бизнеса, стигаме до следното решение: СЛУЧАЙНА ИСТИНА, КОГАТО заплата> = 10000 И заплата<=20000 THEN give_bonus(employee_id, 1500); WHEN salary >20 000 И заплата<= 40000 THEN give_bonus(employee_id, 1000); WHEN salary >40000 ТОГА give_bonus (служител_id, 500); ELSE give_bonus (идентификатор на служител, 0); КРАЙНО СЛУЧАЙ; Важното тук е, че елементите на израз и резултат могат да бъдат скаларни стойности или изрази, чиито резултати са скаларни стойности. Връщайки се към командата IF ... THEN ... ELSIF, която реализира същата логика, ще видите, че секцията ELSE е дефинирана в командата CASE, докато ключовата дума ELSE липсва в командата IF - THEN - ELSIF. Причината за добавяне на ELSE е проста: ако нито едно от условията за бонус не е изпълнено, командата IF не прави нищо и бонусът е нула. В този случай командата CASE генерира грешка, така че ситуацията с нулева премия трябва да бъде програмирана изрично. За да предотвратите CASE_NOT_FOUND грешки, уверете се, че е изпълнено поне едно от условията за всяка стойност на тествания израз. Горната команда CASE TRUE може да звучи като трик за някои, но всъщност просто изпълнява командата CASE search, за което ще говорим в следващия раздел. Команда CASE за търсенеКомандата за търсене CASE изследва списък с булеви изрази; при намиране на израз, равен на TRUE, той изпълнява поредица от свързани команди. По същество командата за търсене CASE е аналогична на командата CASE TRUE, пример за която е показан в предишния раздел. Командата CASE search има следната нотация: CASE WHEN израз_1 THEN команда_1 WHEN израз_2 THEN команда_2 ... ELSE command_else END CASE; Той е идеален за прилагане на логиката на начисляване на бонуси: СЛУЧАЙ, КОГАТО заплата> = 10000 И заплата<=20000 THEN give_bonus(employee_id, 1500); WHEN salary >20 000 И заплата<= 40000 THEN give_bonus(employee_id, 1000); WHEN salary >40000 ТОГА give_bonus (служител_id, 500); ELSE give_bonus (идентификатор на служител, 0); КРАЙНО СЛУЧАЙ; Командата за търсене CASE, подобно на проста команда, спазва следните правила:
Помислете за друго изпълнение на логиката за изчисляване на бонуса, което използва факта, че КОГАТО условията се проверяват в реда, в който са написани. Отделните изрази са по-прости, но можем ли да кажем, че значението на цялата команда е станало по-ясно? СЛУЧАЙ КОГА заплата> 40000 ТОГА give_bonus (служител_id, 500); КОГАТА заплата> 20000 ТОГАВА give_bonus (служител_id, 1000); КОГА заплата> = 10000 ТОГА give_bonus (служител_id, 1500); ELSE give_bonus (идентификатор на служител, 0); КРАЙНО СЛУЧАЙ; Ако определен служител има заплата от 20 000, тогава първите две условия са НЕВЯРНИ, а третото е ИСТИНСКО, така че служителят ще получи бонус от 1500 долара. Ако заплатата е 21 000, тогава резултатът от второто условие ще бъде ИСТИНСКИ, а бонусът ще бъде 1000 долара. Изпълнението на командата CASE ще приключи във втория клон WHEN и третото условие дори няма да бъде проверено. Дали този подход трябва да се използва при писане на CASE команди е спорен въпрос. Независимо от това, имайте предвид, че е възможно да се напише такава команда и се изисква специално внимание при отстраняване на грешки и редактиране на програми, в които резултатът зависи от реда на изразите. Логиката, която зависи от подреждането на хомогенни КОГА клонове, е потенциален източник на грешки, произтичащи от пренареждането им. Като пример, разгледайте следната команда за търсене CASE, в която при заплата от 20 000 тестът за състоянието в двете клаузи WHEN изчислява на TRUE: СЛУЧАЙ КОГА заплата МЕЖДУ 10000 И 20000 ТОГА давам give_bonus (служител_id, 1500); КОГА заплата МЕЖДУ 20000 И 40000 ТОГАВА give_bonus (служител_id, 1000); ... Представете си, че поддържащият тази програма флиппантно пренарежда клаузите WHEN, за да ги подреди в низходящ ред на заплатите. Не отхвърляйте тази възможност! Програмистите често са склонни да "ощипват" красиво работещия код въз основа на някаква вътрешна поръчка. Команда CASE с пренаредени клаузи WHEN изглежда така: СЛУЧАЙ КОГА заплата МЕЖДУ 20000 И 40000 ТОГАВА give_bonus (служител_id, 1000); КОГА заплата МЕЖДУ 10000 И 20000 ТОГА давам_бонус (служител_ид, 1500); ... На пръв поглед всичко е правилно, нали? За съжаление, поради припокриването на две WHEN клонове, в програмата се появява коварна грешка. Сега служител със заплата от 20 000 ще получи бонус от 1000 вместо очакваните 1500. Може да е желателно в някои ситуации да се припокрива между КОГА клонове, но все пак трябва да се избягва, когато е възможно. Винаги помнете, че редът на клонове е важен, и ограничете желанието да промените вече работещия код - „не поправяйте това, което не е счупено“. Тъй като условията WHEN са тествани в ред, можете леко да подобрите ефективността на кода си, като поставите клоновете с най-вероятните условия в горната част на списъка. Освен това, ако имате клон със „скъпи“ изрази (например, изискващи значително CPU време и памет), можете да ги поставите в края, за да сведете до минимум шансовете те да бъдат тествани. Вижте раздела за вложени IF команди за подробности. Командите за търсене CASE се използват, когато командите, които трябва да бъдат изпълнени, се дефинират от набор от логически изрази. Простата команда CASE се използва, когато се взема решение въз основа на резултата от един израз.
Вложени команди CASEКомандите CASE, като командите IF, могат да бъдат вложени. Например, вложената команда CASE се появява в следното (доста объркващо) изпълнение на бонус логиката: CASE WHEN заплата> = 10000 THEN CASE WHEN заплата<= 20000 THEN give_bonus(employee_id, 1500); WHEN salary >40000 ТОГА give_bonus (служител_id, 500); КОГА заплата> 20000 ТОГА give_bonus (служител_id, 1000); КРАЙНО СЛУЧАЙ; КОГА заплата< 10000 THEN give_bonus(employee_id,0); END CASE; В командата CASE може да се използва всяка команда, така че вътрешната команда CASE лесно се заменя с командата IF. По същия начин всяка команда може да бъде вложена в оператор IF, включително CASE. CASE изразиCASE изразите изпълняват същата задача като командите CASE, но не за изпълними команди, а за изрази. Един прост израз CASE избира един от няколко израза за оценка въз основа на определена скаларна стойност. Изразът за търсене CASE оценява изразите в списъка последователно, докато един от тях изчисли TRUE и след това връща резултата от свързания израз. Синтаксисът за тези два вкуса на изразите CASE е: Simple_Case_expression: = CASE израз WHEN result_1 THEN result_expression_1 WHEN result_2 THEN result_expression_2 ... ELSE result_expression_else END; Search_Case_expression: = CASE WHEN израз_1 THEN резултат_expression_1 WHEN израз_2 THEN резултат_expression_2 ... ELSE резултат_expression_else END; Изразът CASE връща една стойност - резултата от израза, избран за оценка. Всяка клауза WHEN трябва да бъде свързана с един израз на резултата (но не и команда). В края на израз CASE няма точка и запетая или END CASE. Изразът CASE завършва с ключовата дума END. По-долу е пример за прост CASE израз, използван заедно с процедурата PUT_LINE на пакета DBMS_OUTPUT за показване на стойността на булева променлива. ОБЯВЕТЕ boolean_true BOOLEAN: = TRUE; boolean_false BOOLEAN: = FALSE; boolean_null BOOLEAN; ФУНКЦИЯ boolean_to_varchar2 (флаг В BOOLEAN) ВРЪЩАНЕ VARCHAR2 Е НАЧАЛО ВРЪЩАНЕ СЛУЧАЙ флаг, КОГА ИСТИННО ТОГАВА "ИСТИННО", КОГАТО НЕВЯРНО ТОГАВА "Невярно" ИНАЧЕ "НУЛНО" КРАЙ; КРАЙ; BEGIN DBMS_OUTPUT.PUT_LINE (boolean_to_varchar2 (boolean_true)); DBMS_OUTPUT.PUT_LINE (boolean_to_varchar2 (boolean_false)); DBMS_OUTPUT.PUT_LINE (boolean_to_varchar2 (boolean_null)); КРАЙ; За да приложите логиката за изчисляване на бонуси, можете да използвате израза за търсене CASE, който връща стойността на бонуса за дадена заплата: ДЕКЛАРИРАЙТЕ НОМЕР на заплатата: = 20000; служител_ID НОМЕР: = 36325; ПРОЦЕДУРА give_bonus (emp_id НА НОМЕР, bonus_amt НА НОМЕР) Е НАЧАЛО DBMS_OUTPUT.PUT_LINE (emp_id); DBMS_OUTPUT.PUT_LINE (bonus_amt); КРАЙ; НАЧАЛО give_bonus (служител_id, СЛУЧАЙ КОГА заплата> = 10000 И заплата<= 20000 THEN 1500 WHEN salary >20 000 И заплата<= 40000 THEN 1000 WHEN salary >40 000 ТОГАВА 500 ИНАЧЕ 0 КРАЙ); КРАЙ; Изразът CASE може да се използва навсякъде, където могат да се използват изрази от всякакъв друг тип. Следващият пример използва израз CASE, за да изчисли премията, умножи го по 10 и присвои резултата на променлива, показана от DBMS_OUTPUT: ДЕКЛАРИРАЙТЕ НОМЕР на заплатата: = 20000; служител_ID НОМЕР: = 36325; бонус_сума НОМЕР; НАЧАЛО бонус_сума: = СЛУЧАЙ КОГАТО заплата> = 10000 И заплата<= 20000 THEN 1500 WHEN salary >20 000 И заплата<= 40000 THEN 1000 WHEN salary >40000 ТОГАВА 500 ИНАЧЕ 0 КРАЙ * 10; DBMS_OUTPUT.PUT_LINE (сума_бонус); КРАЙ; За разлика от командата CASE, ако не е изпълнено клауза WHEN, изразът CASE не извежда грешка, а просто връща NULL. Популярен
Ново в сайта
|