Bedingte Ausdrücke CASE. CASE-Bedingungsausdrücke CASE-Ausdruck ist eine bedingte Anweisung der SQL-Sprache
CASE-Ausdruck
DECODE-Funktion
Es werden zwei Methoden verwendet:
Die beiden Methoden, die verwendet werden, um die bedingte Verarbeitung (IF-THEN-ELSE-Logik) in einer SQL-Anweisung zu implementieren, sind der CASE-Ausdruck und die DECODE-Funktion.
Hinweis: Der CASE-Ausdruck entspricht ANSI SQL. Die DECODE-Funktion ist spezifisch für die Oracle-Syntax.
CASE-Ausdruck
Vereinfacht bedingte Abfragen, indem die IF-THEN-ELSE-Anweisung funktioniert:
Mit CASE-Ausdrücken können Sie die IF-THEN-ELSE-Logik in SQL-Anweisungen verwenden, ohne Prozeduren aufrufen zu müssen.
In einfach bedingter Ausdruck CASE Oracle Server sucht nach dem ersten WHEN ... THEN-Paar, für das expr gleich Comparison_expr ist und return_expr zurückgibt. Wenn keines der WHEN ... THEN-Paare diese Bedingung erfüllt und die else-Klausel existiert, gibt Oracle else_expr zurück. Andernfalls gibt Oracle null zurück. Sie können NULL nicht für alle return_exprs und else_expr angeben.
Ausdr und Vergleichsausdruck müssen denselben Datentyp haben, der CHAR, VARCHAR2, NCHAR oder NVARCHAR2 sein kann. Alle Rückgabewerte (return_expr) müssen vom gleichen Datentyp sein.
In dieser Syntax vergleicht Oracle den Eingabeausdruck (e) mit jedem Vergleichsausdruck e1, e2, ..., en.
Wenn der Eingabeausdruck einem Vergleichsausdruck entspricht, gibt der CASE-Ausdruck den entsprechenden Ergebnisausdruck (r) zurück.
Wenn der Eingabeausdruck e keinem Vergleichsausdruck entspricht, gibt der CASE-Ausdruck den Ausdruck in der ELSE-Klausel zurück, wenn die ELSE-Klausel vorhanden ist, andernfalls gibt er einen Nullwert zurück.
Oracle verwendet die Kurzschlussauswertung für den einfachen CASE-Ausdruck. Das bedeutet, dass Oracle jeden Vergleichsausdruck (e1, e2, .. en) erst auswertet, bevor einer von ihnen mit dem Eingabeausdruck (e) verglichen wird. Oracle wertet nicht alle Vergleichsausdrücke aus, bevor einer von ihnen mit dem Ausdruck (e) verglichen wird. Daher wertet Oracle niemals einen Vergleichsausdruck aus, wenn ein vorheriger gleich dem Eingabeausdruck (e) ist.
Beispiel für einen einfachen CASE-Ausdruck
Wir werden die Produkttabelle in der für die Demonstration verwenden.
Die folgende Abfrage verwendet den CASE-Ausdruck, um den Rabatt für jede Produktkategorie zu berechnen, d. h. CPU 5 %, Grafikkarte 10 % und andere Produktkategorien 8 %
AUSWÄHLEN CASE-Kategorie_ID WANN 1 DANN RUNDE (list_price * 0.05,2) - CPU WANN 2 THEN ROUND (Listenpreis * 0.1,2) - Grafikkarte ELSE ROUND (list_price * 0.08,2) - andere Kategorien ENDE Rabatt VON SORTIEREN NACH |
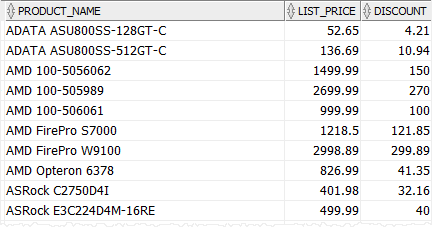
Beachten Sie, dass wir die Funktion ROUND() verwendet haben, um den Rabatt auf zwei Dezimalstellen zu runden.
Gesuchter CASE-Ausdruck
Der von Oracle durchsuchte CASE-Ausdruck wertet eine Liste von booleschen Ausdrücken aus, um das Ergebnis zu bestimmen.
Die gesuchte CASE-Anweisung hat die folgende Syntax:
FALL WENN e1DANN r1 , COUNT (DISTINCT DepartmentID) [Anzahl eindeutiger Abteilungen], COUNT (DISTINCT PositionID) [Anzahl eindeutiger Positionen], COUNT (BonusPercent) [Anzahl Mitarbeiter mit % Bonus], MAX (BonusPercent) [Maximaler Bonusprozentsatz], MIN ( BonusPercent) [Mindestbonusprozentsatz], SUM (Gehalt / 100 * BonusPercent) [Summe aller Boni], AVG (Gehalt / 100 * BonusProzent) [Durchschnittsbonus], AVG (Gehalt) [Durchschnittsgehalt] VON Mitarbeitern Werfen wir einen Blick darauf, wie die einzelnen Rückgabewerte entstanden sind, und erinnern wir uns auf einmal an die Konstruktionen der grundlegenden Syntax der SELECT-Anweisung. Erstens, weil Wenn wir in der Abfrage keine WHERE-Bedingungen angegeben haben, werden die Summen für die detaillierten Daten berechnet, die durch die Abfrage erhalten werden: AUSWÄHLEN * VON Mitarbeitern Jene. für alle Zeilen der Employees-Tabelle. Aus Gründen der Übersichtlichkeit wählen wir nur die Felder und Ausdrücke aus, die in Aggregatfunktionen verwendet werden: SELECT DepartmentID, PositionID, BonusPercent, Gehalt / 100 * BonusPercent, Gehalt VON Mitarbeitern
Dies sind die Anfangsdaten (detaillierte Zeilen), anhand derer die Summen der aggregierten Abfrage berechnet werden. Schauen wir uns nun jeden aggregierten Wert an:
Fassen wir einige der Ergebnisse zusammen:
Dementsprechend werden beim Setzen einer zusätzlichen Bedingung mit Aggregatfunktionen in der WHERE-Klausel nur Summen für Zeilen berechnet, die die Bedingung erfüllen. Jene. die Berechnung der Aggregatwerte erfolgt für den Gesamtsatz, der mit der SELECT-Konstruktion erhalten wird. Machen wir zum Beispiel alles gleich, aber nur im Kontext der IT-Abteilung: SELECT COUNT (*) [Gesamtanzahl der Mitarbeiter], COUNT (DISTINCT DepartmentID) [Anzahl der eindeutigen Abteilungen], COUNT (DISTINCT PositionID) [Anzahl der eindeutigen Positionen], COUNT (BonusPercent) [Anzahl der Mitarbeiter mit % Bonus] , MAX (BonusPercent) [Maximaler Bonusprozentsatz], MIN (BonusPercent) [Mindestbonusprozentsatz], SUM (Gehalt / 100 * BonusPercent) [Summe aller Boni], AVG (Gehalt / 100 * BonusPercent) [Durchschnittliche Bonusgröße], AVG ( Gehalt) [Durchschnittsgehalt] FROM Employees WHERE DepartmentID = 3 - Nur IT-Abteilung berücksichtigen SELECT DepartmentID, PositionID, BonusPercent, Salary / 100 * BonusPercent, Salary FROM Employees WHERE DepartmentID = 3 - nur IT-Abteilung einschließen
Weitergehen. Wenn die Aggregatfunktion NULL zurückgibt (z. B. haben nicht alle Mitarbeiter den Gehaltswert angegeben) oder kein einziger Datensatz in die Auswahl aufgenommen wurde und im Bericht in einem solchen Fall 0 angezeigt werden muss, dann Die ISNULL-Funktion kann den Aggregatausdruck umschließen: SELECT SUM (Gehalt), AVG (Gehalt), - verarbeiten Sie die Summe mit ISNULL ISNULL (SUM (Gehalt), 0), ISNULL (AVG (Gehalt), 0) FROM Employees WHERE DepartmentID = 10 - eine nicht vorhandene Abteilung ist speziell hier angegeben, um zu verhindern, dass die Abfrage Datensätze zurückgibt
Ich glaube, dass es sehr wichtig ist, den Zweck jeder Aggregatfunktion und ihre Berechnung zu verstehen, denn in SQL ist es das Hauptwerkzeug zur Berechnung von Summen. In diesem Fall haben wir untersucht, wie sich jede Aggregatfunktion unabhängig verhält, d.h. es wurde auf die Werte des gesamten Recordsets angewendet, die durch den SELECT-Befehl erhalten wurden. Als Nächstes sehen wir uns an, wie diese Funktionen verwendet werden, um Gruppensummen mit der GROUP BY-Klausel zu berechnen. GROUP BY - Gruppieren von DatenZuvor haben wir die Summen für eine bestimmte Abteilung bereits grob wie folgt berechnet:SELECT COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (Salary) SalaryAmount FROM Employees WHERE DepartmentID = 3 - Daten nur für IT-Abteilung Stellen Sie sich nun vor, wir würden gebeten, für jede Abteilung die gleichen Zahlen zu erhalten. Natürlich können wir die Ärmel hochkrempeln und für jede Abteilung den gleichen Wunsch erfüllen. Gesagt, getan, schreiben wir 4 Anfragen: SELECT "Administration" Info, COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (Salary) SalaryAmount FROM Employees WHERE DepartmentID = 1 - Daten zur Administration SELECT "Accounting" Info, COUNT (DISTINCT PositionID) PositionCount, COUNT ( * ) EmplCount, SUM (Salary) SalaryAmount FROM Employees WHERE DepartmentID = 2 - Buchhaltungsdaten SELECT "IT" Info, COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (Salary) SalaryAmount FROM Employees WHERE DepartmentID = 3 - Daten zu IT-Abteilung SELECT "Andere" Info, COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (Salary) SalaryAmount FROM Employees WHERE DepartmentID IS NULL - und Daten über Freelancer nicht vergessen Als Ergebnis erhalten wir 4 Datensätze:
Bitte beachten Sie, dass wir als Konstanten angegebene Felder verwenden können - "Verwaltung", "Buchhaltung", ... Im Allgemeinen haben wir alle Zahlen extrahiert, die von uns gefragt wurden, wir kombinieren alles in Excel und geben es dem Direktor weiter. Dem Direktor gefiel der Bericht, und er sagt: "Und füge eine weitere Spalte mit Angaben zum Durchschnittsgehalt hinzu." Und das muss wie immer sehr dringend getan werden. Hm, was tun?! Stellen wir uns außerdem vor, unsere Abteilungen sind nicht 3, sondern 15. Genau das ist die GROUP BY-Klausel für solche Fälle: SELECT DepartmentID, COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (Salary) SalaryAmount, AVG (Salary) SalaryAvg - plus wir erfüllen die Wünsche des Direktors FROM Employees GROUP BY DepartmentID
Wir haben alle die gleichen Daten, aber jetzt mit nur einer Anfrage! Achten Sie vorerst nicht darauf, dass unsere Abteilungen in Form von Zahlen angezeigt werden, dann lernen wir, wie man alles schön anzeigt. In der GROUP BY-Klausel können Sie mehrere Felder angeben "GROUP BY field1, field2, ..., fieldN", in diesem Fall erfolgt die Gruppierung nach Gruppen, die die Werte dieser Felder "field1, field2, .. ., FeldN". Lassen Sie uns die Daten beispielsweise nach Abteilungen und Positionen gruppieren: SELECT DepartmentID, PositionID, COUNT (*) EmplCount, SUM (Salary) SalaryAmount FROM Employees GROUP BY DepartmentID, PositionID SELECT COUNT (*) EmplCount, SUM (Salary) SalaryAmount FROM Employees WHERE DepartmentID IS NULL AND PositionID IS NULL SELECT COUNT (*) EmplCount, SUM (Salary) SalaryAmount FROM Employees WHERE DepartmentID = 1 AND PositionID = 2 - ... SELECT COUNT (*) EmplCount, SUM (Salary) SalaryAmount FROM Employees WHERE DepartmentID = 3 AND PositionID = 4 Und dann werden all diese Ergebnisse miteinander kombiniert und uns als ein Set übergeben:
Aus der Hauptsache ist zu beachten, dass im Falle einer Gruppierung (GROUP BY) in der Liste der Spalten im SELECT-Block:
Und eine Demonstration von allem, was gesagt wurde: SELECT "String-Konstante" Const1, - Konstante in Form von String 1 Const2, - Konstante in Form einer Zahl - Ausdruck über die an der Gruppe beteiligten Felder CONCAT ("Department No.", DepartmentID) ConstAndGroupField, CONCAT ("Department No.", DepartmentID , ", Position No.", PositionID) ConstAndGroupFields, DepartmentID, - Feld aus der Liste der an der Gruppierung teilnehmenden Felder - PositionID, - das an der Gruppierung teilnehmende Feld, hier muss nicht dupliziert werden COUNT ( *) EmplCount, - Anzahl der Zeilen in jeder Gruppe - die restlichen Felder können nur mit Aggregatfunktionen verwendet werden: COUNT, SUM, MIN, MAX,… SUM (Salary) SalaryAmount, MIN (ID) MinID FROM Employees GROUP BY DepartmentID , PositionID - Gruppierung nach Feldern DepartmentID, PositionID Es ist auch erwähnenswert, dass die Gruppierung nicht nur nach Feldern, sondern auch nach Ausdrücken erfolgen kann. Gruppieren wir die Daten beispielsweise nach Mitarbeitern, nach Geburtsjahr: KONKAT AUSWÄHLEN ("Geburtsjahr -", JAHR (Geburtstag)) YearOfBirthday, COUNT (*) EmplCount FROM Employees GRUPPE NACH JAHR (Geburtstag) Betrachten wir ein Beispiel mit einem komplexeren Ausdruck. Nehmen wir zum Beispiel die Abstufung der Mitarbeiter nach Geburtsjahr: FALL WÄHLEN WHEN JAHR (Geburtstag)> = 2000 DANN "von 2000" WHEN JAHR (Geburtstag)> = 1990 THEN "1999-1990" WHEN JAHR (Geburtstag)> = 1980 THEN "1989-1980" WHEN JAHR (Geburtstag)> = 1970 DANN "1979-1970" WENN Geburtstag NICHT NULL IST DANN "vor 1970" ELSE "nicht angegeben" END Bereichsname, ANZAHL (*) EmplCount FROM Employees GROUP BY CASE WHEN YEAR (Geburtstag)> = 2000 THEN "from 2000" WHEN YEAR (Geburtstag)> = 1990 DANN "1999-1990" WENN JAHR (Geburtstag)> = 1980 DANN "1989-1980" WENN JAHR (Geburtstag)> = 1970 DANN "1979-1970" WENN Geburtstag NICHT NULL IST DANN "vor 1970" ELSE "nicht angegeben" END
Jene. in diesem Fall erfolgt die Gruppierung nach dem zuvor für jeden Mitarbeiter berechneten CASE-Ausdruck: ID, CASE AUSWÄHLEN WHEN JAHR (Geburtstag)> = 2000 DANN "ab 2000" WHEN JAHR (Geburtstag)> = 1990 THEN "1999-1990" WHEN JAHR (Geburtstag)> = 1980 THEN "1989-1980" WHEN JAHR (Geburtstag) > = 1970 DANN "1979-1970" WENN Geburtstag NICHT NULL IST DANN "vor 1970" ELSE "keine Angabe" END FROM Mitarbeiter
Und natürlich können Sie Ausdrücke mit Feldern im GROUP BY-Block kombinieren: SELECT DepartmentID, CONCAT ("Geburtsjahr -", YEAR (Birthday)) YearOfBirthday, COUNT (*) EmplCount FROM Employees GROUP BY YEAR (Geburtstag), DepartmentID - die Reihenfolge stimmt möglicherweise nicht mit der Reihenfolge ihrer Verwendung in der SELECT ORDER überein BY DepartmentID-Block, YearOfBirthday - endlich können wir das Ergebnis sortieren Kehren wir zu unserer ursprünglichen Aufgabe zurück. Wie wir bereits wissen, hat dem Direktor der Bericht sehr gut gefallen und er hat uns gebeten, ihn wöchentlich zu machen, damit er die Veränderungen im Unternehmen verfolgen kann. Um nicht jedes Mal in Excel den Zahlenwert der Abteilung durch seinen Namen zu unterbrechen, werden wir das bereits vorhandene Wissen nutzen und unsere Abfrage verbessern: SELECT CASE DepartmentID WHEN 1 DANN "Administration" WHEN 2 DANN "Accounting" WHEN 3 THEN "ES" ELSE "Other" END Info, COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (Salary) SalaryAmount, AVG (Salary ) SalaryAvg - plus wir erfüllen die Wünsche des Direktors FROM Mitarbeiter GRUPPE NACH Abteilungs-ID BESTELLEN NACH Info - Sortierung nach der Info-Spalte für mehr Komfort hinzufügen Aber nichts, im Laufe der Zeit werden wir lernen, alles schön zu machen, sodass unsere Auswahl nicht vom Erscheinen neuer Daten in der Datenbank abhängt, sondern dynamisch ist. Ich werde ein wenig vorausgehen, um zu zeigen, welche Art von Anfragen wir versuchen zu erreichen: SELECT ISNULL (abh.Name, "Andere") AbhName, COUNT (DISTINCT emp.PositionID) PositionCount, COUNT (*) EmplCount, SUM (em.Salary) SalaryAmount, AVG (em.Salary) SalaryAvg - plus die Wünsche der Direktor FROM Mitarbeiter emp LEFT JOIN Abteilungen dep ON emp.DepartmentID = dep.ID GROUP BY em.DepartmentID, dep.Name ORDER BY DepName Im Allgemeinen keine Sorge – alle haben einfach angefangen. Im Moment müssen Sie nur den Kern der GROUP BY-Klausel verstehen. Sehen wir uns abschließend an, wie Sie mit GROUP BY zusammenfassende Berichte erstellen können. Lassen Sie uns beispielsweise eine Pivot-Tabelle im Kontext von Abteilungen anzeigen, damit das Gesamtgehalt der Mitarbeiter nach Position berechnet wird: SELECT DepartmentID, SUM (CASE WHEN PositionID = 1 THEN Salary END) [Buchhalter], SUM (CASE WHEN PositionID = 2 THEN Salary END) [Directors], SUM (CASE WHEN PositionID = 3 THEN Salary END) [Programmierer], SUM ( CASE WHEN PositionID = 4 THEN Salary END) [Senior Programmers], SUM (Gehalt) [Department Total] FROM Employees GROUP BY DepartmentID Sie können natürlich mit IIF umgeschrieben werden: SELECT DepartmentID, SUM (IIF (PositionID = 1, Gehalt, NULL)) [Buchhalter], SUM (IIF (PositionID = 2, Gehalt, NULL)) [Direktoren], SUM (IIF (PositionID = 3, Gehalt, NULL)) [Programmierer], SUM (IIF (PositionID = 4, Gehalt, NULL)) [Senior Programmierer], SUM (Gehalt) [Abteilung Gesamt] FROM Mitarbeiter GRUPPE NACH Abteilungs-ID Im Fall von IIF müssen wir jedoch explizit NULL angeben, was zurückgegeben wird, wenn die Bedingung nicht erfüllt ist. In ähnlichen Fällen verwende ich lieber CASE ohne einen ELSE-Block, als noch einmal NULL zu schreiben. Aber das ist sicherlich Geschmackssache, worüber nicht gestritten wird. Und denken wir daran, dass NULL-Werte in Aggregationsfunktionen nicht berücksichtigt werden. Führen Sie zur Konsolidierung eine unabhängige Analyse der durch die erweiterte Anfrage erhaltenen Daten durch: SELECT DepartmentID, CASE WHEN PositionID = 1 THEN Salary END [Buchhalter], CASE WHEN PositionID = 2 THEN Salary END [Directors], CASE WHEN PositionID = 3 THEN Salary END [Programmierer], CASE WHEN PositionID = 4 THEN Salary END [Senior Programmers ], Gehalt [Abteilung Gesamt] VON Mitarbeitern
Und denken wir auch daran, dass wir, wenn wir anstelle von NULL Nullen sehen möchten, den von der Aggregatfunktion zurückgegebenen Wert verarbeiten können. Zum Beispiel: SELECT DepartmentID, ISNULL (SUM (IIF (PositionID = 1, Gehalt, NULL)), 0) [Buchhalter], ISNULL (SUM (IIF (PositionID = 2, Gehalt, NULL)), 0) [Directors], ISNULL (SUM (IIF (PositionID = 3, Gehalt, NULL)), 0) [Programmierer], ISNULL (SUM (IIF (PositionID = 4, Gehalt, NULL)), 0) [Senior Programmierer], ISNULL (SUM (Gehalt), 0 ) [Abteilung Gesamt] FROM Mitarbeiter GRUPPE NACH Abteilungs-ID
GROUP BY in spärlicher Form mit Aggregatfunktionen, eines der wichtigsten Werkzeuge, um zusammenfassende Daten aus der Datenbank zu erhalten, da die Daten normalerweise in dieser Form verwendet werden, weil wir sind in der Regel verpflichtet, zusammenfassende Berichte statt detaillierte Daten (Blätter) bereitzustellen. Und natürlich dreht sich alles darum, das Grunddesign zu kennen, denn bevor Sie etwas zusammenfassen (aggregieren), müssen Sie es zuerst mit "SELECT ... WHERE ..." richtig auswählen. Üben hat hier also einen wichtigen Platz, wenn Sie sich zum Ziel setzen, die SQL-Sprache zu verstehen, nicht zu lernen, sondern zu verstehen - üben, üben und üben, die unterschiedlichsten Möglichkeiten durchgehen, die Ihnen einfallen. Wenn Sie sich in der Anfangsphase über die Richtigkeit der erhaltenen aggregierten Daten nicht sicher sind, erstellen Sie eine detaillierte Stichprobe, einschließlich aller Werte, für die die Aggregation durchgeführt wird. Und überprüfen Sie die Richtigkeit der Berechnungen manuell anhand dieser detaillierten Daten. In diesem Fall kann die Verwendung von Excel sehr hilfreich sein. Sagen wir, du bist an diesem Punkt angekommenNehmen wir an, Sie sind Buchhalter S. S. Sidorov, der beschlossen hat, SELECT-Abfragen zu schreiben.Nehmen wir an, Sie haben dieses Tutorial bis zu diesem Punkt bereits zu Ende gelesen und wenden bereits alle oben genannten Grundkonstruktionen souverän an, d. du kannst:
Ja, aber sie haben nicht berücksichtigt, dass Sie immer noch keine Abfragen aus mehreren Tabellen erstellen können, sondern nur aus einer, d.h. Du weißt nicht, wie man so etwas macht: SELECT Emp. *, - alle Felder der Tabelle Employees dep.Name DepartmentName zurückgeben, - das Feld Name aus der Tabelle Departments pos.Name PositionName zu diesen Feldern hinzufügen - und auch das Feld Name aus der Tabelle Positions FROM Employees Emp LEFT JOIN . hinzufügen Abteilungen dep ON emp.DepartmentID = dep.ID LEFT JOIN Positionen pos ON emp.PositionID = pos.ID Wie können Sie also Ihr aktuelles Wissen nutzen und gleichzeitig noch produktivere Ergebnisse erzielen?! Nutzen wir die Kraft des kollektiven Geistes - wir gehen zu den Programmierern, die für Sie arbeiten, d.h. an Andreev A.A., Petrov P.P. oder Nikolayev N.N., und bitten Sie jemanden, eine Ansicht für Sie zu schreiben (VIEW oder einfach "View", damit sie Sie sogar schneller verstehen), die zusätzlich zu den Hauptfeldern aus der Tabelle Employees auch Felder mit zurückgibt „Der Name der Abteilung“ und „Der Name der Stelle“, die Ihnen jetzt für den Wochenbericht, den Ivanov II. Ihnen hochgeladen hat, so fehlen. Weil Sie haben alles richtig erklärt, dann haben die IT-Spezialisten sofort verstanden, was sie von ihnen wollten und haben speziell für Sie eine Ansicht namens ViewEmployeesInfo erstellt. Wir stellen dar, dass Sie den nächsten Befehl nicht sehen, weil IT-Spezialisten machen es: CREATE VIEW ViewEmployeesInfo AS SELECT Emp. *, - alle Felder der Tabelle Employees dep.Name DepartmentName zurückgeben, - das Feld Name aus der Tabelle Departments pos.Name PositionName zu diesen Feldern hinzufügen - und auch das Feld Name aus der Tabelle Positions FROM Mitarbeiter em LEFT JOIN Abteilungen dep ON emp.DepartmentID = dep.ID LEFT JOIN Positionen pos ON emp.PositionID = pos.ID Jene. für Sie bleibt all dies zwar gruselig und unverständlich, Text bleibt aus dem Bildschirm, und IT-Spezialisten nennen Ihnen nur den Namen der Ansicht "ViewEmployeesInfo", die alle oben genannten Daten zurückgibt (dh wonach Sie gefragt haben). Sie können nun mit dieser Ansicht wie mit einer regulären Tabelle arbeiten: AUSWÄHLEN * VON ViewEmployeesInfo SELECT DepartmentName, COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (Salary) SalaryAmount, AVG (Salary) SalaryAvg FROM ViewEmployeesInfo emp GROUP BY DepartmentID, DepartmentName ORDER BY DepartmentName Jene. für Sie arbeiten Sie in diesem Fall, als ob sich nichts geändert hätte, weiter mit einer Tabelle (richtiger wäre es aber mit der Ansicht ViewEmployeesInfo), die alle benötigten Daten zurückliefert. Dank der Hilfe von IT-Spezialisten bleiben die Details des Mining von DepartmentName und PositionName für Sie in einer Blackbox. Jene. die Ansicht sieht für Sie genauso aus wie eine normale Tabelle, betrachten Sie sie als erweiterte Version der Tabelle Employees. Lassen Sie uns zum Beispiel eine Aussage als Beispiel bilden, damit Sie sicherstellen, dass wirklich alles so ist, wie ich es sagte (dass das gesamte Beispiel aus einer Sicht stammt): WÄHLEN Sie ID, Name, Gehalt AUS ViewEmployeesInfo WO Gehalt NICHT NULL IST UND Gehalt> 0 BESTELLEN NACH Name Die Verwendung von Views ermöglicht es in einigen Fällen, die Grenzen der Benutzer, die grundlegende SELECT-Abfragen schreiben können, erheblich zu erweitern. In diesem Fall ist die Ansicht eine flache Tabelle mit allen Daten, die der Benutzer benötigt (für diejenigen, die OLAP verstehen, kann dies mit einer Annäherung an einen OLAP-Würfel mit Fakten und Dimensionen verglichen werden). Ausschnitt aus Wikipedia. Obwohl SQL als Werkzeug für den Endbenutzer gedacht war, wurde es schließlich so komplex, dass es zu einem Programmierwerkzeug wurde. Wie Sie sehen, liebe Benutzer, wurde die Sprache SQL ursprünglich als Werkzeug für Sie konzipiert. Also, alles liegt in Ihren Händen und Verlangen, lassen Sie Ihre Hände nicht los. HAVING - Auferlegen einer Auswahlbedingung für gruppierte DatenWenn Sie verstehen, was eine Gruppierung ist, dann ist mit HAVING nichts Kompliziertes. HAVING ähnelt WHERE, nur wenn die WHERE-Bedingung auf detaillierte Daten angewendet wird, wird die HAVING-Bedingung auf die bereits gruppierten Daten angewendet. Aus diesem Grund können wir in den Bedingungen des HAVING-Blocks entweder Ausdrücke verwenden, deren Felder in der Gruppierung enthalten sind, oder Ausdrücke, die in Aggregatfunktionen eingeschlossen sind.Betrachten wir ein Beispiel: SELECT DepartmentID, SUM (Gehalt) SalaryAmount FROM Employees GRUPPE NACH Abteilungs-ID HAVING SUM (Gehalt)> 3000
Jene. Diese Anfrage hat uns nur die gruppierten Daten für die Abteilungen zurückgegeben, für die das Gesamtgehalt aller Mitarbeiter 3000 überschreitet, d.h. "SUMME (Gehalt) > 3000".
Jene. hier erfolgt zunächst die Gruppierung und die Daten für alle Abteilungen werden berechnet: SELECT DepartmentID, SUM (Salary) SalaryAmount FROM Employees GROUP BY DepartmentID - 1. Gruppierte Daten für alle Abteilungen abrufen Und schon wird auf diese Daten die im HAVING-Block angegebene Bedingung angewendet: SELECT DepartmentID, SUM (Salary) SalaryAmount FROM Employees GROUP BY DepartmentID - 1. Gruppierte Daten für alle Abteilungen abrufen HAVING SUM (Salary)> 3000 - 2.Bedingung zum Filtern von gruppierten Daten In der HAVING-Bedingung können Sie auch komplexe Bedingungen mit den Operatoren AND, OR und NOT erstellen: SELECT DepartmentID, SUM (Gehalt) SalaryAmount FROM Employees GRUPPE NACH Abteilungs-ID HABEN SUMME (Gehalt)> 3000 UND ZÄHLEN (*)<2 -- и число людей меньше 2-х
Wie Sie hier sehen, kann die Aggregatfunktion (siehe "COUNT (*)") nur im HAVING-Block angegeben werden. Dementsprechend können wir nur die Nummer der Abteilung anzeigen, die der Bedingung HAVING entspricht: WÄHLEN SIE Abteilungs-ID FROM Mitarbeiter GRUPPE NACH Abteilungs-ID HABEN SUMME (Gehalt)> 3000 UND ZÄHL (*)<2 -- и число людей меньше 2-х Ein Beispiel für die Verwendung der HAVING-Bedingung für ein Feld, das in der GROUP BY enthalten ist: SELECT DepartmentID, SUM (Salary) SalaryAmount FROM Employees GROUP BY DepartmentID - 1. die Gruppierung HAVING DepartmentID = 3 machen - 2. das Gruppierungsergebnis filtern Dies ist nur ein Beispiel, da In diesem Fall wäre es logischer, eine WHERE-Bedingung zu überprüfen: SELECT DepartmentID, SUM (Salary) SalaryAmount FROM Employees WHERE DepartmentID = 3 - 1. Detaillierte Daten filtern GROUP BY DepartmentID - 2. Gruppierung nur nach ausgewählten Datensätzen vornehmen Jene. Filtern Sie zuerst die Mitarbeiter nach Abteilung 3 und führen Sie erst dann eine Berechnung durch. Notiz. Obwohl die beiden Abfragen unterschiedlich aussehen, kann der DBMS-Optimierer sie auf die gleiche Weise ausführen. Ich denke, hier kann die Geschichte über das HABEN von Bedingungen enden. Fassen wir zusammenFassen wir die im zweiten und dritten Teil erhaltenen Daten zusammen und betrachten wir den spezifischen Standort jeder von uns untersuchten Struktur und geben wir die Reihenfolge ihrer Implementierung an:
Natürlich können Sie die Klauseln DISTINCT und TOP, die Sie in Teil 2 gelernt haben, auch auf gruppierte Daten anwenden. Diese Vorschläge gelten in diesem Fall für das Endergebnis: SELECT TOP 1 - 6. wird die letzte SUMME (Gehalt) anwenden SalaryAmount FROM Employees GRUPPE NACH Abteilungs-ID HAVING SUM (Gehalt)> 3000 BESTELLEN NACH Abteilungs-ID - 5.sortieren Sie das Ergebnis Analysieren Sie selbst, wie diese Ergebnisse erzielt wurden. AbschlussDas Hauptziel, das ich in diesem Teil festgelegt habe, besteht darin, Ihnen die Essenz von Aggregatfunktionen und Gruppierungen aufzuzeigen.Wenn das grundlegende Design es uns ermöglichte, die erforderlichen Detaildaten zu erhalten, dann gab uns die Anwendung von Aggregatfunktionen und Gruppierungen auf diese Detaildaten die Möglichkeit, zusammenfassende Daten darüber zu erhalten. Also, wie Sie sehen, ist hier alles wichtig, tk. das eine baut auf dem anderen auf - ohne Kenntnis der Grundstruktur werden wir zum Beispiel die Daten, für die wir die Summen berechnen müssen, nicht richtig auswählen können. Hier versuche ich bewusst nur die Basics zu zeigen, um die Aufmerksamkeit des Anfängers auf die wichtigsten Strukturen zu lenken und diese nicht mit unnötigen Informationen zu überfrachten. Ein solides Verständnis der grundlegenden Strukturen (über die ich in den folgenden Teilen weiter sprechen werde) gibt Ihnen die Möglichkeit, fast jedes Problem beim Abrufen von Daten aus einer RDB zu lösen. Die Grundkonstruktionen der SELECT-Anweisung sind in fast allen DBMS in gleicher Form anwendbar (die Unterschiede liegen hauptsächlich in den Details, zB in der Implementierung von Funktionen - für das Arbeiten mit Strings, Zeit etc.). Anschließend haben Sie durch solide Grundkenntnisse die Möglichkeit, verschiedene Erweiterungen der SQL-Sprache auf einfache Weise selbstständig zu erlernen, wie zum Beispiel:
Wenn Sie Ihre ersten Schritte in SQL machen, dann konzentrieren Sie sich zunächst auf das Studium grundlegender Konstrukte, da Wenn Sie die Basis besitzen, wird alles andere für Sie viel einfacher zu verstehen sein, und außerdem auf eigene Faust. Zuallererst müssen Sie die Fähigkeiten der SQL-Sprache gründlich verstehen, d.h. welche Art von Operation es im Allgemeinen erlaubt, mit Daten durchzuführen. Anfängern Informationen in voluminöser Form zu vermitteln ist ein weiterer Grund, warum ich nur die wichtigsten (Eisen-)Strukturen zeige. Viel Glück beim Lernen und Verstehen der SQL-Sprache. Teil vier -
Was wird in diesem Teil besprochenIn diesem Teil lernen wir:
CASE-Ausdruck - Bedingte SQL-AnweisungMit diesem Operator können Sie die Bedingungen überprüfen und je nach Erfüllung einer bestimmten Bedingung das eine oder andere Ergebnis zurückgeben.Die CASE-Anweisung hat 2 Formen: Nehmen wir ein Beispiel für das erste CASE-Formular: WÄHLEN Sie ID, Name, Gehalt, FALL WHEN Gehalt> = 3000 DANN "RFP> = 3000" WHEN Gehalt> = 2000 DANN "2000<= ЗП < 3000"
ELSE "ЗП < 2000"
END SalaryTypeWithELSE,
CASE
WHEN Salary>= 3000 DANN "Gehalt> = 3000" WANN Gehalt> = 2000 DANN "2000<= ЗП < 3000"
END SalaryTypeWithoutELSE
FROM Employees
Wenn keine der WHEN-Bedingungen erfüllt ist, wird der nach dem Wort ELSE angegebene Wert zurückgegeben (was in diesem Fall "ELSE RETURN ..." bedeutet). Wenn kein ELSE-Block angegeben ist und keine WHEN-Bedingungen erfüllt sind, wird NULL zurückgegeben. Sowohl in der ersten als auch in der zweiten Form steht der ELSE-Block ganz am Ende der CASE-Struktur, d.h. nach allen WANN-Bedingungen. Nehmen wir ein Beispiel für das zweite CASE-Formular: Nehmen wir an, für das neue Jahr haben sie beschlossen, alle Mitarbeiter zu belohnen, und baten darum, die Höhe der Boni nach dem folgenden Schema zu berechnen:
Für diese Aufgabe verwenden wir eine Abfrage mit einem CASE-Ausdruck: SELECT ID, Name, Salary, DepartmentID, - aus Gründen der Übersichtlichkeit werden wir den Prozentsatz als Zeile anzeigen CASE DepartmentID - der geprüfte Wert WHEN 2 DANN "10%" - 10% des Gehalts für Buchhalter WHEN 3 THEN "15%" " - 15% vom Gehalt, um es an IT-Mitarbeiter zu geben ELSE "5%" - an alle anderen 5% END NewYearBonusPercent, - Lassen Sie uns mit CASE einen Ausdruck erstellen, um die Höhe des Bonusgehalts / 100 * CASE DepartmentID WHEN 2 THEN . zu sehen 10 - 10 % des auszugebenden Gehalts Für Buchhalter WANN 3 DANN 15 - 15 % des auszugebenden Gehalts IT-Mitarbeiter SONST 5 - alle anderen je 5 % ENDE Bonusbetrag FROM Mitarbeiter Dementsprechend wird der Wert des ELSE-Blocks zurückgegeben, wenn die DepartmentID mit keinem WHEN-Wert übereinstimmt. Wenn kein ELSE-Block vorhanden ist, wird NULL zurückgegeben, wenn DepartmentID keinem WHEN-Wert entspricht. Die zweite CASE-Form lässt sich mit der ersten Form einfach darstellen: SELECT ID, Name, Salary, DepartmentID, CASE WHEN DepartmentID = 2 THEN "10%" - 10% des Gehalts für Buchhalter WHEN DepartmentID = 3 THEN "15%" - 15% des Gehalts für IT-Mitarbeiter ELSE " 5% "- alle anderen 5% END NewYearBonusPercent, - Erstellen Sie einen Ausdruck mit CASE, um den Bonusbetrag anzuzeigen Gehalt / 100 * CASE WHEN DepartmentID = 2 THEN 10 - 10% des Gehalts für Buchhalter WHEN DepartmentID = 3 DANN 15 - 15% des Gehalts für IT-Mitarbeiter ELSE 5 - alle anderen jeweils 5% ENDE Bonusbetrag FROM Mitarbeiter Die zweite Form ist also nur eine vereinfachte Notation für die Fälle, in denen wir einen Gleichheitsvergleich desselben Testwerts mit jedem WHEN-Wert / -Ausdruck durchführen müssen. Notiz. Die erste und zweite Form von CASE sind im SQL-Sprachstandard enthalten, daher sollten sie höchstwahrscheinlich in vielen DBMS anwendbar sein. Mit MS SQL Version 2012 ist eine vereinfachte IIF-Notationsform erschienen. Es kann verwendet werden, um eine CASE-Anweisung zu vereinfachen, wenn nur 2 Werte zurückgegeben werden. Das IIF-Design sieht wie folgt aus: IIF (Bedingung, wahrer_Wert, falscher_Wert) Jene. Tatsächlich ist es ein Wrapper für die folgende CASE-Konstruktion: CASE WHEN Bedingung THEN true_value ELSE false_value END Sehen wir uns ein Beispiel an: SELECT ID, Name, Gehalt, IIF (Gehalt> = 2500, "Gehalt> = 2500", "Gehalt< 2500") DemoIIF, CASE WHEN Salary>= 2500 DANN "RFP> = 2500" ELSE "RFP< 2500" END DemoCASE FROM Employees CASE-, IIF-Konstrukte können ineinander verschachtelt werden. Betrachten wir ein abstraktes Beispiel: SELECT ID, Name, Salary, CASE WHEN DepartmentID IN (1,2) THEN "A" WHEN DepartmentID = 3 THEN CASE PositionID - verschachtelt CASE WHEN 3 THEN "B-1" WHEN 4 THEN "B-2" END ELSE " C "END Demo1, IIF (DepartmentID IN (1,2)," A ", IIF (DepartmentID = 3, CASE PositionID WHEN 3 THEN" B-1 "WHEN 4 THEN" B-2 "END," C ")) Demo2 VON Mitarbeitern Da die Konstrukte CASE und IIF Ausdrücke sind, die ein Ergebnis zurückgeben, können wir sie nicht nur im SELECT-Block verwenden, sondern auch in anderen Blöcken, die die Verwendung von Ausdrücken ermöglichen, beispielsweise in den Klauseln WHERE oder ORDER BY. Stellen wir uns zum Beispiel die Aufgabe vor, eine Liste für die Gehaltsverteilung zu erstellen, wie folgt:
Versuchen wir, dieses Problem zu lösen, indem wir dem ORDER BY-Block einen CASE-Ausdruck hinzufügen: ID, Name, Gehalt VON Mitarbeitern AUSWÄHLEN NACH FALL BESTELLEN WHEN Gehalt> = 2500 DANN 1 ELSE 0 END, - zuerst ein Gehalt an diejenigen ausgeben, die weniger als 2500 haben Name - die Liste weiter nach dem vollständigen Namen sortieren Und ein abstraktes Beispiel für die Verwendung von CASE in einer WHERE-Klausel: SELECT ID, Name, Gehalt FROM Mitarbeiter WHERE CASE WHEN Gehalt> = 2500 THEN 1 ELSE 0 END = 1 - alle Datensätze, deren Ausdruck 1 ist Sie können versuchen, die letzten 2 Beispiele mit der IIF-Funktion selbst zu wiederholen. Und schließlich erinnern wir uns noch einmal an NULL-Werte: SELECT ID, Name, Salary, DepartmentID, CASE WHEN DepartmentID = 2 THEN "10%" - 10% des Gehalts für Buchhalter WHEN DepartmentID = 3 DANN "15%" - 15% des Gehalts an IT-Mitarbeiter WHEN DepartmentID IS NULL THEN "-" - wir geben keine Boni an Freiberufler (wir verwenden IS NULL) ELSE "5%" - alle anderen haben jeweils 5% END NewYearBonusPercent1, - aber Sie können nicht auf NULL prüfen, denken Sie daran, was über NULL gesagt wurde im zweiten Teil der CASE DepartmentID - - geprüfter Wert WHEN 2 DANN "10%" WHEN 3 DANN "15%" WHEN NULL THEN "-" - !!! in diesem Fall ist die Verwendung des zweiten CASE-Formulars nicht geeignet ELSE "5%" END NewYearBonusPercent2 FROM Employees SELECT ID, Name, Salary, DepartmentID, CASE ISNULL (DepartmentID, -1) - verwenden Sie die Ersetzung bei NULL durch -1 WHEN 2 THEN "10%" WHEN 3 THEN "15%" WHEN -1 THEN "-" - wenn wir sicher sind, dass es keine Abteilung mit der ID gleich (-1) gibt und es nicht ELSE "5%" geben wird END NewYearBonusPercent3 FROM Employees Im Allgemeinen ist der Fantasie in diesem Fall keine Grenzen gesetzt. Sehen wir uns zum Beispiel an, wie die ISNULL-Funktion mit CASE und IIF modelliert werden kann: SELECT ID, Name, LastName, ISNULL (LastName, "Unspecified") DemoISNULL, CASE WHEN LastName IS NULL THEN "Unspecified" ELSE LastName END DemoCASE, IIF (LastName IS NULL, "Unspecified", LastName) DemoIIF FROM Employees Das CASE-Konstrukt ist eine sehr leistungsstarke SQL-Funktion, mit der Sie zusätzliche Logik zur Berechnung der Werte der Ergebnismenge auferlegen können. In diesem Teil wird uns der Besitz der CASE-Konstruktion noch nützlich sein, daher wird in diesem Teil zunächst darauf geachtet. AggregatfunktionenHier werden nur die grundlegenden und am häufigsten verwendeten Aggregatfunktionen behandelt:
Mit Aggregatfunktionen können wir den Gesamtwert für eine Reihe von Zeilen berechnen, die mit der SELECT-Anweisung erhalten wurden. Schauen wir uns jede Funktion mit einem Beispiel an: SELECT COUNT (*) [Gesamtanzahl der Mitarbeiter], COUNT (DISTINCT DepartmentID) [Anzahl der eindeutigen Abteilungen], COUNT (DISTINCT PositionID) [Anzahl der eindeutigen Positionen], COUNT (BonusPercent) [Anzahl der Mitarbeiter mit % Bonus] , MAX (BonusPercent) [Maximaler Bonusprozentsatz], MIN (BonusPercent) [Mindestbonusprozentsatz], SUM (Gehalt / 100 * BonusPercent) [Summe aller Boni], AVG (Gehalt / 100 * BonusPercent) [Durchschnittliche Bonusgröße], AVG ( Gehalt) [Durchschnittsgehalt] VON Mitarbeitern Werfen wir einen Blick darauf, wie die einzelnen Rückgabewerte entstanden sind, und erinnern wir uns auf einmal an die Konstruktionen der grundlegenden Syntax der SELECT-Anweisung. Erstens, weil Wenn wir in der Abfrage keine WHERE-Bedingungen angegeben haben, werden die Summen für die detaillierten Daten berechnet, die durch die Abfrage erhalten werden: AUSWÄHLEN * VON Mitarbeitern Jene. für alle Zeilen der Employees-Tabelle. Aus Gründen der Übersichtlichkeit wählen wir nur die Felder und Ausdrücke aus, die in Aggregatfunktionen verwendet werden: SELECT DepartmentID, PositionID, BonusPercent, Gehalt / 100 * BonusPercent, Gehalt VON Mitarbeitern
Dies sind die Anfangsdaten (detaillierte Zeilen), anhand derer die Summen der aggregierten Abfrage berechnet werden. Schauen wir uns nun jeden aggregierten Wert an:
Fassen wir einige der Ergebnisse zusammen:
Dementsprechend werden beim Setzen einer zusätzlichen Bedingung mit Aggregatfunktionen in der WHERE-Klausel nur Summen für Zeilen berechnet, die die Bedingung erfüllen. Jene. die Berechnung der Aggregatwerte erfolgt für den Gesamtsatz, der mit der SELECT-Konstruktion erhalten wird. Machen wir zum Beispiel alles gleich, aber nur im Kontext der IT-Abteilung: SELECT COUNT (*) [Gesamtanzahl der Mitarbeiter], COUNT (DISTINCT DepartmentID) [Anzahl der eindeutigen Abteilungen], COUNT (DISTINCT PositionID) [Anzahl der eindeutigen Positionen], COUNT (BonusPercent) [Anzahl der Mitarbeiter mit % Bonus] , MAX (BonusPercent) [Maximaler Bonusprozentsatz], MIN (BonusPercent) [Mindestbonusprozentsatz], SUM (Gehalt / 100 * BonusPercent) [Summe aller Boni], AVG (Gehalt / 100 * BonusPercent) [Durchschnittliche Bonusgröße], AVG ( Gehalt) [Durchschnittsgehalt] FROM Employees WHERE DepartmentID = 3 - Nur IT-Abteilung berücksichtigen SELECT DepartmentID, PositionID, BonusPercent, Salary / 100 * BonusPercent, Salary FROM Employees WHERE DepartmentID = 3 - nur IT-Abteilung einschließen
Weitergehen. Wenn die Aggregatfunktion NULL zurückgibt (z. B. haben nicht alle Mitarbeiter den Gehaltswert angegeben) oder kein einziger Datensatz in die Auswahl aufgenommen wurde und im Bericht in einem solchen Fall 0 angezeigt werden muss, dann Die ISNULL-Funktion kann den Aggregatausdruck umschließen: SELECT SUM (Gehalt), AVG (Gehalt), - verarbeiten Sie die Summe mit ISNULL ISNULL (SUM (Gehalt), 0), ISNULL (AVG (Gehalt), 0) FROM Employees WHERE DepartmentID = 10 - eine nicht vorhandene Abteilung ist speziell hier angegeben, um zu verhindern, dass die Abfrage Datensätze zurückgibt
Ich glaube, dass es sehr wichtig ist, den Zweck jeder Aggregatfunktion und ihre Berechnung zu verstehen, denn in SQL ist es das Hauptwerkzeug zur Berechnung von Summen. In diesem Fall haben wir untersucht, wie sich jede Aggregatfunktion unabhängig verhält, d.h. es wurde auf die Werte des gesamten Recordsets angewendet, die durch den SELECT-Befehl erhalten wurden. Als Nächstes sehen wir uns an, wie diese Funktionen verwendet werden, um Gruppensummen mit der GROUP BY-Klausel zu berechnen. GROUP BY - Gruppieren von DatenZuvor haben wir die Summen für eine bestimmte Abteilung bereits grob wie folgt berechnet:SELECT COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (Salary) SalaryAmount FROM Employees WHERE DepartmentID = 3 - Daten nur für IT-Abteilung Stellen Sie sich nun vor, wir würden gebeten, für jede Abteilung die gleichen Zahlen zu erhalten. Natürlich können wir die Ärmel hochkrempeln und für jede Abteilung den gleichen Wunsch erfüllen. Gesagt, getan, schreiben wir 4 Anfragen: SELECT "Administration" Info, COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (Salary) SalaryAmount FROM Employees WHERE DepartmentID = 1 - Daten zur Administration SELECT "Accounting" Info, COUNT (DISTINCT PositionID) PositionCount, COUNT ( * ) EmplCount, SUM (Salary) SalaryAmount FROM Employees WHERE DepartmentID = 2 - Buchhaltungsdaten SELECT "IT" Info, COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (Salary) SalaryAmount FROM Employees WHERE DepartmentID = 3 - Daten zu IT-Abteilung SELECT "Andere" Info, COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (Salary) SalaryAmount FROM Employees WHERE DepartmentID IS NULL - und Daten über Freelancer nicht vergessen Als Ergebnis erhalten wir 4 Datensätze:
Bitte beachten Sie, dass wir als Konstanten angegebene Felder verwenden können - "Verwaltung", "Buchhaltung", ... Im Allgemeinen haben wir alle Zahlen extrahiert, die von uns gefragt wurden, wir kombinieren alles in Excel und geben es dem Direktor weiter. Dem Direktor gefiel der Bericht, und er sagt: "Und füge eine weitere Spalte mit Angaben zum Durchschnittsgehalt hinzu." Und das muss wie immer sehr dringend getan werden. Hm, was tun?! Stellen wir uns außerdem vor, unsere Abteilungen sind nicht 3, sondern 15. Genau das ist die GROUP BY-Klausel für solche Fälle: SELECT DepartmentID, COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (Salary) SalaryAmount, AVG (Salary) SalaryAvg - plus wir erfüllen die Wünsche des Direktors FROM Employees GROUP BY DepartmentID
Wir haben alle die gleichen Daten, aber jetzt mit nur einer Anfrage! Achten Sie vorerst nicht darauf, dass unsere Abteilungen in Form von Zahlen angezeigt werden, dann lernen wir, wie man alles schön anzeigt. In der GROUP BY-Klausel können Sie mehrere Felder angeben "GROUP BY field1, field2, ..., fieldN", in diesem Fall erfolgt die Gruppierung nach Gruppen, die die Werte dieser Felder "field1, field2, .. ., FeldN". Lassen Sie uns die Daten beispielsweise nach Abteilungen und Positionen gruppieren: SELECT DepartmentID, PositionID, COUNT (*) EmplCount, SUM (Salary) SalaryAmount FROM Employees GROUP BY DepartmentID, PositionID SELECT COUNT (*) EmplCount, SUM (Salary) SalaryAmount FROM Employees WHERE DepartmentID IS NULL AND PositionID IS NULL SELECT COUNT (*) EmplCount, SUM (Salary) SalaryAmount FROM Employees WHERE DepartmentID = 1 AND PositionID = 2 - ... SELECT COUNT (*) EmplCount, SUM (Salary) SalaryAmount FROM Employees WHERE DepartmentID = 3 AND PositionID = 4 Und dann werden all diese Ergebnisse miteinander kombiniert und uns als ein Set übergeben:
Aus der Hauptsache ist zu beachten, dass im Falle einer Gruppierung (GROUP BY) in der Liste der Spalten im SELECT-Block:
Und eine Demonstration von allem, was gesagt wurde: SELECT "String-Konstante" Const1, - Konstante in Form von String 1 Const2, - Konstante in Form einer Zahl - Ausdruck über die an der Gruppe beteiligten Felder CONCAT ("Department No.", DepartmentID) ConstAndGroupField, CONCAT ("Department No.", DepartmentID , ", Position No.", PositionID) ConstAndGroupFields, DepartmentID, - Feld aus der Liste der an der Gruppierung teilnehmenden Felder - PositionID, - das an der Gruppierung teilnehmende Feld, hier muss nicht dupliziert werden COUNT ( *) EmplCount, - Anzahl der Zeilen in jeder Gruppe - die restlichen Felder können nur mit Aggregatfunktionen verwendet werden: COUNT, SUM, MIN, MAX,… SUM (Salary) SalaryAmount, MIN (ID) MinID FROM Employees GROUP BY DepartmentID , PositionID - Gruppierung nach Feldern DepartmentID, PositionID Es ist auch erwähnenswert, dass die Gruppierung nicht nur nach Feldern, sondern auch nach Ausdrücken erfolgen kann. Gruppieren wir die Daten beispielsweise nach Mitarbeitern, nach Geburtsjahr: KONKAT AUSWÄHLEN ("Geburtsjahr -", JAHR (Geburtstag)) YearOfBirthday, COUNT (*) EmplCount FROM Employees GRUPPE NACH JAHR (Geburtstag) Betrachten wir ein Beispiel mit einem komplexeren Ausdruck. Nehmen wir zum Beispiel die Abstufung der Mitarbeiter nach Geburtsjahr: FALL WÄHLEN WHEN JAHR (Geburtstag)> = 2000 DANN "von 2000" WHEN JAHR (Geburtstag)> = 1990 THEN "1999-1990" WHEN JAHR (Geburtstag)> = 1980 THEN "1989-1980" WHEN JAHR (Geburtstag)> = 1970 DANN "1979-1970" WENN Geburtstag NICHT NULL IST DANN "vor 1970" ELSE "nicht angegeben" END Bereichsname, ANZAHL (*) EmplCount FROM Employees GROUP BY CASE WHEN YEAR (Geburtstag)> = 2000 THEN "from 2000" WHEN YEAR (Geburtstag)> = 1990 DANN "1999-1990" WENN JAHR (Geburtstag)> = 1980 DANN "1989-1980" WENN JAHR (Geburtstag)> = 1970 DANN "1979-1970" WENN Geburtstag NICHT NULL IST DANN "vor 1970" ELSE "nicht angegeben" END
Jene. in diesem Fall erfolgt die Gruppierung nach dem zuvor für jeden Mitarbeiter berechneten CASE-Ausdruck: ID, CASE AUSWÄHLEN WHEN JAHR (Geburtstag)> = 2000 DANN "ab 2000" WHEN JAHR (Geburtstag)> = 1990 THEN "1999-1990" WHEN JAHR (Geburtstag)> = 1980 THEN "1989-1980" WHEN JAHR (Geburtstag) > = 1970 DANN "1979-1970" WENN Geburtstag NICHT NULL IST DANN "vor 1970" ELSE "keine Angabe" END FROM Mitarbeiter
Und natürlich können Sie Ausdrücke mit Feldern im GROUP BY-Block kombinieren: SELECT DepartmentID, CONCAT ("Geburtsjahr -", YEAR (Birthday)) YearOfBirthday, COUNT (*) EmplCount FROM Employees GROUP BY YEAR (Geburtstag), DepartmentID - die Reihenfolge stimmt möglicherweise nicht mit der Reihenfolge ihrer Verwendung in der SELECT ORDER überein BY DepartmentID-Block, YearOfBirthday - endlich können wir das Ergebnis sortieren Kehren wir zu unserer ursprünglichen Aufgabe zurück. Wie wir bereits wissen, hat dem Direktor der Bericht sehr gut gefallen und er hat uns gebeten, ihn wöchentlich zu machen, damit er die Veränderungen im Unternehmen verfolgen kann. Um nicht jedes Mal in Excel den Zahlenwert der Abteilung durch seinen Namen zu unterbrechen, werden wir das bereits vorhandene Wissen nutzen und unsere Abfrage verbessern: SELECT CASE DepartmentID WHEN 1 DANN "Administration" WHEN 2 DANN "Accounting" WHEN 3 THEN "ES" ELSE "Other" END Info, COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (Salary) SalaryAmount, AVG (Salary ) SalaryAvg - plus wir erfüllen die Wünsche des Direktors FROM Mitarbeiter GRUPPE NACH Abteilungs-ID BESTELLEN NACH Info - Sortierung nach der Info-Spalte für mehr Komfort hinzufügen Aber nichts, im Laufe der Zeit werden wir lernen, alles schön zu machen, sodass unsere Auswahl nicht vom Erscheinen neuer Daten in der Datenbank abhängt, sondern dynamisch ist. Ich werde ein wenig vorausgehen, um zu zeigen, welche Art von Anfragen wir versuchen zu erreichen: SELECT ISNULL (abh.Name, "Andere") AbhName, COUNT (DISTINCT emp.PositionID) PositionCount, COUNT (*) EmplCount, SUM (em.Salary) SalaryAmount, AVG (em.Salary) SalaryAvg - plus die Wünsche der Direktor FROM Mitarbeiter emp LEFT JOIN Abteilungen dep ON emp.DepartmentID = dep.ID GROUP BY em.DepartmentID, dep.Name ORDER BY DepName Im Allgemeinen keine Sorge – alle haben einfach angefangen. Im Moment müssen Sie nur den Kern der GROUP BY-Klausel verstehen. Sehen wir uns abschließend an, wie Sie mit GROUP BY zusammenfassende Berichte erstellen können. Lassen Sie uns beispielsweise eine Pivot-Tabelle im Kontext von Abteilungen anzeigen, damit das Gesamtgehalt der Mitarbeiter nach Position berechnet wird: SELECT DepartmentID, SUM (CASE WHEN PositionID = 1 THEN Salary END) [Buchhalter], SUM (CASE WHEN PositionID = 2 THEN Salary END) [Directors], SUM (CASE WHEN PositionID = 3 THEN Salary END) [Programmierer], SUM ( CASE WHEN PositionID = 4 THEN Salary END) [Senior Programmers], SUM (Gehalt) [Department Total] FROM Employees GROUP BY DepartmentID Sie können natürlich mit IIF umgeschrieben werden: SELECT DepartmentID, SUM (IIF (PositionID = 1, Gehalt, NULL)) [Buchhalter], SUM (IIF (PositionID = 2, Gehalt, NULL)) [Direktoren], SUM (IIF (PositionID = 3, Gehalt, NULL)) [Programmierer], SUM (IIF (PositionID = 4, Gehalt, NULL)) [Senior Programmierer], SUM (Gehalt) [Abteilung Gesamt] FROM Mitarbeiter GRUPPE NACH Abteilungs-ID Im Fall von IIF müssen wir jedoch explizit NULL angeben, was zurückgegeben wird, wenn die Bedingung nicht erfüllt ist. In ähnlichen Fällen verwende ich lieber CASE ohne einen ELSE-Block, als noch einmal NULL zu schreiben. Aber das ist sicherlich Geschmackssache, worüber nicht gestritten wird. Und denken wir daran, dass NULL-Werte in Aggregationsfunktionen nicht berücksichtigt werden. Führen Sie zur Konsolidierung eine unabhängige Analyse der durch die erweiterte Anfrage erhaltenen Daten durch: SELECT DepartmentID, CASE WHEN PositionID = 1 THEN Salary END [Buchhalter], CASE WHEN PositionID = 2 THEN Salary END [Directors], CASE WHEN PositionID = 3 THEN Salary END [Programmierer], CASE WHEN PositionID = 4 THEN Salary END [Senior Programmers ], Gehalt [Abteilung Gesamt] VON Mitarbeitern
Und denken wir auch daran, dass wir, wenn wir anstelle von NULL Nullen sehen möchten, den von der Aggregatfunktion zurückgegebenen Wert verarbeiten können. Zum Beispiel: SELECT DepartmentID, ISNULL (SUM (IIF (PositionID = 1, Gehalt, NULL)), 0) [Buchhalter], ISNULL (SUM (IIF (PositionID = 2, Gehalt, NULL)), 0) [Directors], ISNULL (SUM (IIF (PositionID = 3, Gehalt, NULL)), 0) [Programmierer], ISNULL (SUM (IIF (PositionID = 4, Gehalt, NULL)), 0) [Senior Programmierer], ISNULL (SUM (Gehalt), 0 ) [Abteilung Gesamt] FROM Mitarbeiter GRUPPE NACH Abteilungs-ID
GROUP BY in spärlicher Form mit Aggregatfunktionen, eines der wichtigsten Werkzeuge, um zusammenfassende Daten aus der Datenbank zu erhalten, da die Daten normalerweise in dieser Form verwendet werden, weil wir sind in der Regel verpflichtet, zusammenfassende Berichte statt detaillierte Daten (Blätter) bereitzustellen. Und natürlich dreht sich alles darum, das Grunddesign zu kennen, denn bevor Sie etwas zusammenfassen (aggregieren), müssen Sie es zuerst mit "SELECT ... WHERE ..." richtig auswählen. Üben hat hier also einen wichtigen Platz, wenn Sie sich zum Ziel setzen, die SQL-Sprache zu verstehen, nicht zu lernen, sondern zu verstehen - üben, üben und üben, die unterschiedlichsten Möglichkeiten durchgehen, die Ihnen einfallen. Wenn Sie sich in der Anfangsphase über die Richtigkeit der erhaltenen aggregierten Daten nicht sicher sind, erstellen Sie eine detaillierte Stichprobe, einschließlich aller Werte, für die die Aggregation durchgeführt wird. Und überprüfen Sie die Richtigkeit der Berechnungen manuell anhand dieser detaillierten Daten. In diesem Fall kann die Verwendung von Excel sehr hilfreich sein. Sagen wir, du bist an diesem Punkt angekommenNehmen wir an, Sie sind Buchhalter S. S. Sidorov, der beschlossen hat, SELECT-Abfragen zu schreiben.Nehmen wir an, Sie haben dieses Tutorial bis zu diesem Punkt bereits zu Ende gelesen und wenden bereits alle oben genannten Grundkonstruktionen souverän an, d. du kannst:
Ja, aber sie haben nicht berücksichtigt, dass Sie immer noch keine Abfragen aus mehreren Tabellen erstellen können, sondern nur aus einer, d.h. Du weißt nicht, wie man so etwas macht: SELECT Emp. *, - alle Felder der Tabelle Employees dep.Name DepartmentName zurückgeben, - das Feld Name aus der Tabelle Departments pos.Name PositionName zu diesen Feldern hinzufügen - und auch das Feld Name aus der Tabelle Positions FROM Employees Emp LEFT JOIN . hinzufügen Abteilungen dep ON emp.DepartmentID = dep.ID LEFT JOIN Positionen pos ON emp.PositionID = pos.ID Wie können Sie also Ihr aktuelles Wissen nutzen und gleichzeitig noch produktivere Ergebnisse erzielen?! Nutzen wir die Kraft des kollektiven Geistes - wir gehen zu den Programmierern, die für Sie arbeiten, d.h. an Andreev A.A., Petrov P.P. oder Nikolayev N.N., und bitten Sie jemanden, eine Ansicht für Sie zu schreiben (VIEW oder einfach "View", damit sie Sie sogar schneller verstehen), die zusätzlich zu den Hauptfeldern aus der Tabelle Employees auch Felder mit zurückgibt „Der Name der Abteilung“ und „Der Name der Stelle“, die Ihnen jetzt für den Wochenbericht, den Ivanov II. Ihnen hochgeladen hat, so fehlen. Weil Sie haben alles richtig erklärt, dann haben die IT-Spezialisten sofort verstanden, was sie von ihnen wollten und haben speziell für Sie eine Ansicht namens ViewEmployeesInfo erstellt. Wir stellen dar, dass Sie den nächsten Befehl nicht sehen, weil IT-Spezialisten machen es: CREATE VIEW ViewEmployeesInfo AS SELECT Emp. *, - alle Felder der Tabelle Employees dep.Name DepartmentName zurückgeben, - das Feld Name aus der Tabelle Departments pos.Name PositionName zu diesen Feldern hinzufügen - und auch das Feld Name aus der Tabelle Positions FROM Mitarbeiter em LEFT JOIN Abteilungen dep ON emp.DepartmentID = dep.ID LEFT JOIN Positionen pos ON emp.PositionID = pos.ID Jene. für Sie bleibt all dies zwar gruselig und unverständlich, Text bleibt aus dem Bildschirm, und IT-Spezialisten nennen Ihnen nur den Namen der Ansicht "ViewEmployeesInfo", die alle oben genannten Daten zurückgibt (dh wonach Sie gefragt haben). Sie können nun mit dieser Ansicht wie mit einer regulären Tabelle arbeiten: AUSWÄHLEN * VON ViewEmployeesInfo SELECT DepartmentName, COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (Salary) SalaryAmount, AVG (Salary) SalaryAvg FROM ViewEmployeesInfo emp GROUP BY DepartmentID, DepartmentName ORDER BY DepartmentName Jene. für Sie arbeiten Sie in diesem Fall, als ob sich nichts geändert hätte, weiter mit einer Tabelle (richtiger wäre es aber mit der Ansicht ViewEmployeesInfo), die alle benötigten Daten zurückliefert. Dank der Hilfe von IT-Spezialisten bleiben die Details des Mining von DepartmentName und PositionName für Sie in einer Blackbox. Jene. die Ansicht sieht für Sie genauso aus wie eine normale Tabelle, betrachten Sie sie als erweiterte Version der Tabelle Employees. Lassen Sie uns zum Beispiel eine Aussage als Beispiel bilden, damit Sie sicherstellen, dass wirklich alles so ist, wie ich es sagte (dass das gesamte Beispiel aus einer Sicht stammt): WÄHLEN Sie ID, Name, Gehalt AUS ViewEmployeesInfo WO Gehalt NICHT NULL IST UND Gehalt> 0 BESTELLEN NACH Name Die Verwendung von Views ermöglicht es in einigen Fällen, die Grenzen der Benutzer, die grundlegende SELECT-Abfragen schreiben können, erheblich zu erweitern. In diesem Fall ist die Ansicht eine flache Tabelle mit allen Daten, die der Benutzer benötigt (für diejenigen, die OLAP verstehen, kann dies mit einer Annäherung an einen OLAP-Würfel mit Fakten und Dimensionen verglichen werden). Ausschnitt aus Wikipedia. Obwohl SQL als Werkzeug für den Endbenutzer gedacht war, wurde es schließlich so komplex, dass es zu einem Programmierwerkzeug wurde. Wie Sie sehen, liebe Benutzer, wurde die Sprache SQL ursprünglich als Werkzeug für Sie konzipiert. Also, alles liegt in Ihren Händen und Verlangen, lassen Sie Ihre Hände nicht los. HAVING - Auferlegen einer Auswahlbedingung für gruppierte DatenWenn Sie verstehen, was eine Gruppierung ist, dann ist mit HAVING nichts Kompliziertes. HAVING ähnelt WHERE, nur wenn die WHERE-Bedingung auf detaillierte Daten angewendet wird, wird die HAVING-Bedingung auf die bereits gruppierten Daten angewendet. Aus diesem Grund können wir in den Bedingungen des HAVING-Blocks entweder Ausdrücke verwenden, deren Felder in der Gruppierung enthalten sind, oder Ausdrücke, die in Aggregatfunktionen eingeschlossen sind.Betrachten wir ein Beispiel: SELECT DepartmentID, SUM (Gehalt) SalaryAmount FROM Employees GRUPPE NACH Abteilungs-ID HAVING SUM (Gehalt)> 3000
Jene. Diese Anfrage hat uns nur die gruppierten Daten für die Abteilungen zurückgegeben, für die das Gesamtgehalt aller Mitarbeiter 3000 überschreitet, d.h. "SUMME (Gehalt) > 3000".
Jene. hier erfolgt zunächst die Gruppierung und die Daten für alle Abteilungen werden berechnet: SELECT DepartmentID, SUM (Salary) SalaryAmount FROM Employees GROUP BY DepartmentID - 1. Gruppierte Daten für alle Abteilungen abrufen Und schon wird auf diese Daten die im HAVING-Block angegebene Bedingung angewendet: SELECT DepartmentID, SUM (Salary) SalaryAmount FROM Employees GROUP BY DepartmentID - 1. Gruppierte Daten für alle Abteilungen abrufen HAVING SUM (Salary)> 3000 - 2.Bedingung zum Filtern von gruppierten Daten In der HAVING-Bedingung können Sie auch komplexe Bedingungen mit den Operatoren AND, OR und NOT erstellen: SELECT DepartmentID, SUM (Gehalt) SalaryAmount FROM Employees GRUPPE NACH Abteilungs-ID HABEN SUMME (Gehalt)> 3000 UND ZÄHLEN (*)<2 -- и число людей меньше 2-х
Wie Sie hier sehen, kann die Aggregatfunktion (siehe "COUNT (*)") nur im HAVING-Block angegeben werden. Dementsprechend können wir nur die Nummer der Abteilung anzeigen, die der Bedingung HAVING entspricht: WÄHLEN SIE Abteilungs-ID FROM Mitarbeiter GRUPPE NACH Abteilungs-ID HABEN SUMME (Gehalt)> 3000 UND ZÄHL (*)<2 -- и число людей меньше 2-х Ein Beispiel für die Verwendung der HAVING-Bedingung für ein Feld, das in der GROUP BY enthalten ist: SELECT DepartmentID, SUM (Salary) SalaryAmount FROM Employees GROUP BY DepartmentID - 1. die Gruppierung HAVING DepartmentID = 3 machen - 2. das Gruppierungsergebnis filtern Dies ist nur ein Beispiel, da In diesem Fall wäre es logischer, eine WHERE-Bedingung zu überprüfen: SELECT DepartmentID, SUM (Salary) SalaryAmount FROM Employees WHERE DepartmentID = 3 - 1. Detaillierte Daten filtern GROUP BY DepartmentID - 2. Gruppierung nur nach ausgewählten Datensätzen vornehmen Jene. Filtern Sie zuerst die Mitarbeiter nach Abteilung 3 und führen Sie erst dann eine Berechnung durch. Notiz. Obwohl die beiden Abfragen unterschiedlich aussehen, kann der DBMS-Optimierer sie auf die gleiche Weise ausführen. Ich denke, hier kann die Geschichte über das HABEN von Bedingungen enden. Fassen wir zusammenFassen wir die im zweiten und dritten Teil erhaltenen Daten zusammen und betrachten wir den spezifischen Standort jeder von uns untersuchten Struktur und geben wir die Reihenfolge ihrer Implementierung an:
Natürlich können Sie die Klauseln DISTINCT und TOP, die Sie in Teil 2 gelernt haben, auch auf gruppierte Daten anwenden. Diese Vorschläge gelten in diesem Fall für das Endergebnis: SELECT TOP 1 - 6. wird die letzte SUMME (Gehalt) anwenden SalaryAmount FROM Employees GRUPPE NACH Abteilungs-ID HAVING SUM (Gehalt)> 3000 BESTELLEN NACH Abteilungs-ID - 5.sortieren Sie das Ergebnis Analysieren Sie selbst, wie diese Ergebnisse erzielt wurden. AbschlussDas Hauptziel, das ich in diesem Teil festgelegt habe, besteht darin, Ihnen die Essenz von Aggregatfunktionen und Gruppierungen aufzuzeigen.Wenn das grundlegende Design es uns ermöglichte, die erforderlichen Detaildaten zu erhalten, dann gab uns die Anwendung von Aggregatfunktionen und Gruppierungen auf diese Detaildaten die Möglichkeit, zusammenfassende Daten darüber zu erhalten. Also, wie Sie sehen, ist hier alles wichtig, tk. das eine baut auf dem anderen auf - ohne Kenntnis der Grundstruktur werden wir zum Beispiel die Daten, für die wir die Summen berechnen müssen, nicht richtig auswählen können. Hier versuche ich bewusst nur die Basics zu zeigen, um die Aufmerksamkeit des Anfängers auf die wichtigsten Strukturen zu lenken und diese nicht mit unnötigen Informationen zu überfrachten. Ein solides Verständnis der grundlegenden Strukturen (über die ich in den folgenden Teilen weiter sprechen werde) gibt Ihnen die Möglichkeit, fast jedes Problem beim Abrufen von Daten aus einer RDB zu lösen. Die Grundkonstruktionen der SELECT-Anweisung sind in fast allen DBMS in gleicher Form anwendbar (die Unterschiede liegen hauptsächlich in den Details, zB in der Implementierung von Funktionen - für das Arbeiten mit Strings, Zeit etc.). Anschließend haben Sie durch solide Grundkenntnisse die Möglichkeit, verschiedene Erweiterungen der SQL-Sprache auf einfache Weise selbstständig zu erlernen, wie zum Beispiel:
Wenn Sie Ihre ersten Schritte in SQL machen, dann konzentrieren Sie sich zunächst auf das Studium grundlegender Konstrukte, da Wenn Sie die Basis besitzen, wird alles andere für Sie viel einfacher zu verstehen sein, und außerdem auf eigene Faust. Zuallererst müssen Sie die Fähigkeiten der SQL-Sprache gründlich verstehen, d.h. welche Art von Operation es im Allgemeinen erlaubt, mit Daten durchzuführen. Anfängern Informationen in voluminöser Form zu vermitteln ist ein weiterer Grund, warum ich nur die wichtigsten (Eisen-)Strukturen zeige. Viel Glück beim Lernen und Verstehen der SQL-Sprache. Teil vier - Befehl CASE ermöglicht Ihnen die Auswahl für einer von mehrere Befehlsfolgen... Dieses Konstrukt ist im SQL-Standard seit 1992 vorhanden, obwohl es in Oracle SQL bis Oracle8i und in PL / SQL bis Oracle9i Release 1 nicht unterstützt wurde. Ab dieser Version werden die folgenden Varianten von CASE-Befehlen unterstützt:
NULL oder UNBEKANNT?Im Artikel über die IF-Anweisung haben Sie vielleicht erfahren, dass das Ergebnis eines booleschen Ausdrucks TRUE, FALSE oder NULL sein kann. In PL / SQL ist dies richtig, aber im breiteren Kontext der relationalen Theorie wird es als falsch angesehen, von der Rückgabe von NULL aus einem booleschen Ausdruck zu sprechen. Die relationale Theorie besagt, dass Vergleiche mit NULL wie folgt aussehen: 2 < NULL liefert das logische Ergebnis UNKNOWN und UNKNOWN ist nicht NULL. Machen Sie sich jedoch keine allzu großen Sorgen über die Verwendung von NULL für UNKNOWN durch PL / SQL. Beachten Sie jedoch, dass der dritte Wert in der 3-wertigen Logik UNBEKANNT ist. Und ich hoffe, Sie fallen nie (wie ich!) ins Unrecht, indem Sie den falschen Begriff verwenden, wenn Sie mit Experten auf dem Gebiet der relationalen Theorie über die dreiwertige Logik diskutieren. PL / SQL unterstützt neben CASE-Befehlen auch CASE-Ausdrücke. Dieser Ausdruck ist dem CASE-Befehl sehr ähnlich, er ermöglicht Ihnen, einen oder mehrere Ausdrücke zur Auswertung auszuwählen. Das Ergebnis eines CASE-Ausdrucks ist ein Wert, während das Ergebnis eines CASE-Befehls die Ausführung einer Folge von PL / SQL-Befehlen ist. Einfache CASE-BefehleMit einem einfachen CASE-Befehl können Sie eine von mehreren Folgen von PL / SQL-Befehlen auswählen, die basierend auf dem Ergebnis der Auswertung eines Ausdrucks ausgeführt werden. Es ist wie folgt geschrieben: CASE Ausdruck WHEN Ergebnis_1 THEN Befehl_1 WHEN Ergebnis_2 THEN Befehl_2 ... ELSE Befehl_else END CASE; Der ELSE-Zweig ist hier optional. Beim Ausführen eines solchen Befehls wertet PL / SQL zuerst den Ausdruck aus und vergleicht dann das Ergebnis mit result_1. Bei Übereinstimmung werden die Befehle_1 ausgeführt. Andernfalls wird der Wert result_2 geprüft usw. Hier ein Beispiel für einen einfachen CASE-Befehl, bei dem der Bonus in Abhängigkeit vom Wert der Variablen Employee_type berechnet wird: CASE mitarbeiter_typ WHEN "S" THEN award_salary_bonus (mitarbeiter_id); WHEN "H" THEN award_hourly_bonus (employee_id); WHEN "C" THEN award_commissioned_bonus (mitarbeiter_id); ELSE RAISE ungültiger_Mitarbeitertyp; ENDGEHÄUSE; In diesem Beispiel gibt es eine explizite ELSE-Klausel, die jedoch im Allgemeinen nicht erforderlich ist. Ohne ELSE-Klausel ersetzt der PL/SQL-Compiler implizit den folgenden Code: SONST RAISE CASE_NOT_FOUND; Mit anderen Worten, wenn Sie das Schlüsselwort ELSE weglassen und keines der Ergebnisse in den WHEN-Klauseln mit dem Ergebnis des Ausdrucks im CASE-Befehl übereinstimmt, löst PL / SQL eine CASE_NOT_FOUND-Ausnahme aus. Dies ist der Unterschied zwischen diesem Befehl und IF. Fehlt das Schlüsselwort ELSE im IF-Befehl, passiert nichts, wenn die Bedingung nicht erfüllt ist, während beim CASE-Befehl eine ähnliche Situation zu einem Fehler führt. Es wird interessant sein zu sehen, wie die am Anfang des Kapitels beschriebene Bonusberechnungslogik mit einem einfachen CASE-Befehl implementiert wird. Auf den ersten Blick scheint dies unmöglich, aber wenn wir kreativ zur Sache kommen, kommen wir zu folgender Lösung: CASE TRUE WENN Gehalt> = 10000 UND Gehalt<=20000 THEN give_bonus(employee_id, 1500); WHEN salary >20.000 UND Gehalt<= 40000 THEN give_bonus(employee_id, 1000); WHEN salary >40000 DANN give_bonus (mitarbeiter_id, 500); ELSE give_bonus (mitarbeiter_id, 0); ENDGEHÄUSE; Wichtig hierbei ist, dass die Ausdrucks- und Ergebniselemente entweder skalare Werte oder Ausdrücke sein können, deren Ergebnisse skalare Werte sind. Wenn Sie zum Befehl IF ... THEN ... ELSIF zurückkehren, der dieselbe Logik implementiert, werden Sie feststellen, dass der Abschnitt ELSE im Befehl CASE definiert ist, während das Schlüsselwort ELSE im Befehl IF – THEN – ELSIF fehlt. Der Grund für das Hinzufügen von ELSE ist einfach: Wenn keine der Bonusbedingungen erfüllt ist, tut der IF-Befehl nichts und der Bonus ist Null. In diesem Fall generiert der CASE-Befehl einen Fehler, daher muss die Situation mit einer Nullprämie explizit programmiert werden. Um CASE_NOT_FOUND-Fehler zu vermeiden, stellen Sie sicher, dass mindestens eine der Bedingungen für jeden Wert des getesteten Ausdrucks erfüllt ist. Der obige CASE TRUE-Befehl mag für manche wie eine Spielerei klingen, aber er implementiert wirklich nur den CASE-Suchbefehl, über den wir im nächsten Abschnitt sprechen werden. CASE-SuchbefehlDer CASE-Suchbefehl untersucht eine Liste boolescher Ausdrücke; Wenn ein Ausdruck gefunden wird, der gleich WAHR ist, führt er eine Folge zugehöriger Befehle aus. Im Wesentlichen entspricht der CASE-Suchbefehl dem CASE TRUE-Befehl, für den ein Beispiel im vorherigen Abschnitt gezeigt wurde. Der CASE-Suchbefehl hat die folgende Schreibweise: CASE WHEN Ausdruck_1 THEN Befehl_1 WHEN Ausdruck_2 THEN Befehl_2 ... ELSE Befehl_else END CASE; Es ist ideal, um die Logik der Bonusabgrenzung umzusetzen: CASE WHEN Gehalt> = 10000 AND Gehalt<=20000 THEN give_bonus(employee_id, 1500); WHEN salary >20.000 UND Gehalt<= 40000 THEN give_bonus(employee_id, 1000); WHEN salary >40000 DANN give_bonus (mitarbeiter_id, 500); ELSE give_bonus (mitarbeiter_id, 0); ENDGEHÄUSE; Der CASE-Suchbefehl befolgt wie ein einfacher Befehl die folgenden Regeln:
Betrachten Sie eine andere Implementierung der Bonusberechnungslogik, die die Tatsache nutzt, dass WHEN-Bedingungen in der Reihenfolge geprüft werden, in der sie geschrieben werden. Einzelne Ausdrücke sind einfacher, aber können wir sagen, dass die Bedeutung des gesamten Befehls klarer geworden ist? FALL WENN Gehalt> 40000 DANN Give_bonus (Mitarbeiter_ID, 500); WANN Gehalt> 20000 DANN Give_bonus (Mitarbeiter_ID, 1000); WHEN Gehalt> = 10000 DANN Give_bonus (Mitarbeiter_ID, 1500); ELSE give_bonus (mitarbeiter_id, 0); ENDGEHÄUSE; Wenn ein bestimmter Mitarbeiter ein Gehalt von 20.000 hat, dann sind die ersten beiden Bedingungen FALSCH und die dritte ist WAHR, der Mitarbeiter erhält also einen Bonus von 1.500 US-Dollar. Wenn das Gehalt 21.000 beträgt, ist das Ergebnis der zweiten Bedingung WAHR und der Bonus beträgt 1.000 USD. Die Ausführung des CASE-Befehls wird im zweiten WHEN-Zweig beendet und die dritte Bedingung wird nicht einmal geprüft. Ob dieser Ansatz beim Schreiben von CASE-Befehlen verwendet werden sollte oder nicht, ist umstritten. Denken Sie jedoch daran, dass es möglich ist, einen solchen Befehl zu schreiben, und dass beim Debuggen und Bearbeiten von Programmen, bei denen das Ergebnis von der Reihenfolge der Ausdrücke abhängt, besondere Sorgfalt erforderlich ist. Logik, die von der Anordnung homogener WHEN-Verzweigungen abhängt, ist eine potenzielle Fehlerquelle, die sich aus ihrer Neuordnung ergibt. Betrachten Sie als Beispiel den folgenden CASE-Lookup-Befehl, bei dem bei einem Gehalt von 20.000 der Bedingungstest in beiden WHEN-Klauseln als TRUE ausgewertet wird: FALL, WENN Gehalt ZWISCHEN 10000 UND 20000 DANN give_bonus (mitarbeiter_id, 1500); WENN Gehalt ZWISCHEN 20000 UND 40000 DANN give_bonus (mitarbeiter_id, 1000); ... Stellen Sie sich vor, der Betreuer dieses Programms ordnet leichtfertig die WHEN-Klauseln um, um sie in absteigender Gehaltsreihenfolge zu ordnen. Lehnen Sie diese Möglichkeit nicht ab! Programmierer neigen oft dazu, schön funktionierenden Code zu "verfeinern", geleitet von einer Art interner Ordnungsvorstellung. Ein CASE-Befehl mit neu angeordneten WHEN-Klauseln sieht so aus: FALL, WENN Gehalt ZWISCHEN 20000 UND 40000 DANN give_bonus (mitarbeiter_id, 1000); WENN Gehalt ZWISCHEN 10000 UND 20000 DANN give_bonus (mitarbeiter_id, 1500); ... Auf den ersten Blick stimmt doch alles, oder? Leider kommt es aufgrund der Überlappung zweier WHEN-Zweige zu einem heimtückischen Fehler im Programm. Nun erhält ein Mitarbeiter mit einem Gehalt von 20.000 statt der erwarteten 1.500 einen Bonus von 1.000. Überschneidungen zwischen den WHEN-Filialen können in manchen Situationen wünschenswert sein, sollten aber dennoch möglichst vermieden werden. Denken Sie immer daran, dass die Reihenfolge der Verzweigungen wichtig ist, und halten Sie den Drang zurück, bereits funktionierenden Code zu ändern – „reparieren Sie nicht, was nicht kaputt ist“. Da die WHEN-Bedingungen der Reihe nach getestet werden, können Sie die Codeeffizienz geringfügig verbessern, indem Sie die Verzweigungen mit den wahrscheinlichsten Bedingungen an den Anfang der Liste setzen. Wenn Sie außerdem einen Zweig mit "teuren" Ausdrücken haben (die beispielsweise viel CPU-Zeit und Speicher benötigen), können Sie diese ans Ende setzen, um die Wahrscheinlichkeit zu minimieren, dass sie getestet werden. Weitere Informationen finden Sie im Abschnitt Verschachtelte IF-Befehle. CASE-Suchbefehle werden verwendet, wenn die auszuführenden Befehle durch einen Satz logischer Ausdrücke definiert sind. Ein einfacher CASE-Befehl wird verwendet, wenn eine Entscheidung basierend auf dem Ergebnis eines einzelnen Ausdrucks getroffen wird.
Verschachtelte CASE-BefehleCASE-Befehle können wie IF-Befehle verschachtelt werden. Der verschachtelte CASE-Befehl kommt beispielsweise in der folgenden (eher verwirrenden) Implementierung der Bonuslogik vor: FALL WHEN Gehalt> = 10000 DANN FALL WHEN Gehalt<= 20000 THEN give_bonus(employee_id, 1500); WHEN salary >40000 DANN give_bonus (mitarbeiter_id, 500); WANN Gehalt> 20000 DANN Give_bonus (Mitarbeiter-ID, 1000); ENDGEHÄUSE; WANN Gehalt< 10000 THEN give_bonus(employee_id,0); END CASE; Im CASE-Befehl kann jeder Befehl verwendet werden, sodass der interne CASE-Befehl leicht durch den IF-Befehl ersetzt werden kann. Ebenso kann jeder Befehl in einer IF-Anweisung verschachtelt werden, einschließlich CASE. CASE-AusdrückeCASE-Ausdrücke erfüllen dieselbe Aufgabe wie CASE-Befehle, jedoch nicht für ausführbare Befehle, sondern für Ausdrücke. Ein einfacher CASE-Ausdruck wählt einen von mehreren Ausdrücken zur Auswertung basierend auf einem angegebenen Skalarwert aus. Ein CASE-Suchausdruck wertet die Ausdrücke in der Liste nacheinander aus, bis einer als TRUE ausgewertet wird, und gibt dann das Ergebnis des zugeordneten Ausdrucks zurück. Die Syntax für diese beiden Varianten von CASE-Ausdrücken lautet: Simple_Case_expression: = CASE Ausdruck WHEN result_1 THEN result_expression_1 WHEN result_2 THEN result_expression_2 ... ELSE result_expression_else END; Search_Case_expression: = CASE WHEN expression_1 THEN result_expression1 WHEN expression_2 THEN result_expression_2 ... ELSE result_expression_else END; Der CASE-Ausdruck gibt einen Wert zurück – das Ergebnis des zur Auswertung ausgewählten Ausdrucks. Jede WHEN-Klausel muss einem Ergebnisausdruck (aber keinem Befehl) zugeordnet sein. Am Ende eines CASE-Ausdrucks steht kein Semikolon oder END CASE. Der CASE-Ausdruck endet mit dem Schlüsselwort END. Das Folgende ist ein Beispiel für einen einfachen CASE-Ausdruck, der in Verbindung mit der PUT_LINE-Prozedur des DBMS_OUTPUT-Pakets verwendet wird, um den Wert einer booleschen Variablen anzuzeigen. DECLARE boolean_true BOOLEAN: = TRUE; boolean_false BOOLEAN: = FALSE; boolean_null BOOLEAN; FUNKTION boolean_to_varchar2 (Flag IN BOOLEAN) RETURN VARCHAR2 IS BEGIN RETURN CASE Flag WHEN TRUE THEN "True" WHEN FALSE THEN "False" ELSE "NULL" END; ENDE; BEGIN DBMS_OUTPUT.PUT_LINE (boolean_to_varchar2 (boolean_true)); DBMS_OUTPUT.PUT_LINE (boolean_to_varchar2 (boolean_false)); DBMS_OUTPUT.PUT_LINE (boolean_to_varchar2 (boolean_null)); ENDE; Um die Logik zur Berechnung der Zuschläge zu implementieren, können Sie den Suchausdruck CASE verwenden, der den Zuschlagswert für ein bestimmtes Gehalt zurückgibt: GEHALTSZAHL ERKLÄREN: = 20000; Mitarbeiter_ID NUMMER: = 36325; VERFAHREN give_bonus (emp_id IN NUMBER, bonus_amt IN NUMBER) IS BEGIN DBMS_OUTPUT.PUT_LINE (emp_id); DBMS_OUTPUT.PUT_LINE (bonus_amt); ENDE; BEGIN give_bonus (employee_id, CASE WHEN Gehalt> = 10000 AND Gehalt<= 20000 THEN 1500 WHEN salary >20.000 UND Gehalt<= 40000 THEN 1000 WHEN salary >40.000 DANN 500 SONST 0 ENDE); ENDE; Der CASE-Ausdruck kann überall dort verwendet werden, wo Ausdrücke eines anderen Typs verwendet werden können. Im folgenden Beispiel wird ein CASE-Ausdruck verwendet, um die Prämie zu berechnen, mit 10 zu multiplizieren und das Ergebnis einer von DBMS_OUTPUT angezeigten Variablen zuzuweisen: GEHALTSZAHL ERKLÄREN: = 20000; Mitarbeiter_ID NUMMER: = 36325; Bonusbetrag NUMBER; BEGIN bonus_amount: = CASE WHEN Gehalt> = 10000 UND Gehalt<= 20000 THEN 1500 WHEN salary >20.000 UND Gehalt<= 40000 THEN 1000 WHEN salary >40000 DANN 500 SONST 0 ENDE * 10; DBMS_OUTPUT.PUT_LINE (Bonus_Betrag); ENDE; Im Gegensatz zum CASE-Befehl gibt der CASE-Ausdruck keinen Fehler aus, wenn keine WHEN-Klausel erfüllt ist, sondern gibt einfach NULL zurück. Beliebt
Neu auf der Seite
|

























