Умовні вирази CASE. Умовні вирази CASE Вираз CASE – умовний оператор мови SQL
Вираз CASE
Функція DECODE
Використовують два методи:
Два методи, які використовуються, щоб реалізувати умовну обробку (логіку IF-THEN-ELSE) у SQL-операторі, - це вираз CASE та функція DECODE.
Позначте : CASE-вираз задовольняє ANSI SQL. Функція DECODE специфічна для синтаксису Oracle.
Вираз CASE
Спрощує умовні запити, роблячи роботу оператора IF-THEN-ELSE:
Вирази CASE дозволяють використовувати логіку IF-THEN-ELSE в SQL-операторах, не маючи необхідності викликати процедури.
У простому умовному вираженні CASE сервер Oracle шукає першу пару WHEN...THEN, для якої expr одно comparison_expr і повертає return_expr. Якщо жодна з пар WHEN ... THEN не задовольняє цю умову, і якщо вираз else існує, сервер Oracle повертає else_expr. Інакше сервер Oracle повертає null. Не можна вказати NULL для всіх return_exprs і для else_expr.
Вирази expr і comparison_expr повинні мати той самий тип даних, який може бути CHAR, VARCHAR2, NCHAR або NVARCHAR2. Усі значення, що повертаються (return_expr) повинні мати однаковий тип даних.
У цьому syntax, Oracle compares the input expression (e) to each comparison expression e1, e2, …, en.
Якщо введення екземплярів еквівалентів будь-якого comparison expression, the case expression returns the corresponding result expression (r).
Якщо вхідний дзвінок не вдається до будь-якого comparison expression, з'єднання CASE повідомить про повторення в ELSE clause if ELSE clause exists, otherwise, it returns a null value.
Oracle використовує Short-circuit evaluation for the simple CASE expression. Це означає, що Oracle виявляють, що їх comparison expression (e1, e2, .. en) тільки перед тим, як comparing one of them with the input expression (e). Oracle не усвідомлює всі загальні запитання перед тим, як comparing any of them with the expression (e). Як результат, Oracle не визнає, що comparison expression if a previous one equals the input expression (e).
Simple CASE expression example
We will use the products table in the for demonstration.
Наступні методи використання CASE expression для калькуляції discount для кожного продукту категорії i.e., CPU 5%, відеокарта 10%, та інших продуктів категорії 8%
SELECT CASE category_id WHEN 1 THEN ROUND (list_price*0.05,2)-- CPU WHEN 2 THEN ROUND (List_price*0.1,2)-- Video Card ELSE ROUND (list_price*0.08,2)-- other categories END discount FROM ORDER BY |
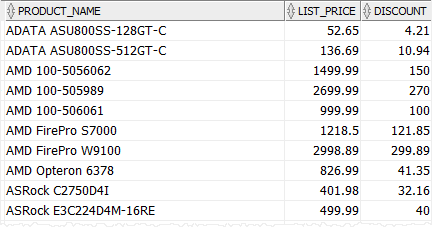
Зверніть увагу, що ми використовуємо ROUND () функцію до кінця дисконту до двох decimal places.
Searched CASE expression
У Oracle searched CASE expression evaluates list of Boolean expressions to determine the result.
Searched CASE statement has following syntax:
CASE WHEN e1THEN r1 , COUNT(DISTINCT DepartmentID) [Кількість унікальних відділів], COUNT(DISTINCT PositionID) [Кількість унікальних посад], COUNT(BonusPercent) [Кількість співробітників яких вказано % бонусу], MAX(BonusPercent) [Максимальний відсоток бонусу], MIN (BonusPercent) [Мінімальний відсоток бонусу], SUM(Salary/100*BonusPercent) [Сума всіх бонусів], AVG(Salary/100*BonusPercent) [Середній розмір бонусу], AVG(Salary) [Середній розмір ЗП] FROM Employees Розберемо яким чином вийшло кожне повернене значення, а за одне згадаємо конструкції базового синтаксису оператора SELECT. По-перше, т.к. ми в запиті не вказали WHERE-умови, то підсумки будуть вважатися для детальних даних, які виходять запитом: SELECT * FROM Employees Тобто. всім рядків таблиці Employees. Для наочності виберемо лише поля та вирази, які використовуються в агрегатних функціях: SELECT DepartmentID, PositionID, BonusPercent, Salary/100*BonusPercent , Salary FROM Employees
Це вихідні дані (детальні рядки), за якими і будуть рахуватися підсумки агрегованого запиту. Тепер розберемо кожне агреговане значення:
Підіб'ємо деякі підсумки:
Відповідно при завданні з агрегатними функціями додаткової умови в блоці WHERE, будуть підраховані лише підсумки, що за рядками задовольняють умові. Тобто. Розрахунок агрегатних значень відбувається для підсумкового набору, отриманого за допомогою конструкції SELECT. Наприклад, зробимо все те саме, але тільки в розрізі ІТ-відділу: SELECT COUNT(*) [Загальна кількість співробітників], COUNT(DISTINCT DepartmentID) [Кількість унікальних відділів], COUNT(DISTINCT PositionID) [Кількість унікальних посад], COUNT(BonusPercent) [Кількість співробітників, у яких вказано % бонуса] , MAX(BonusPercent) [Максимальний відсоток бонусу], MIN(BonusPercent) [Мінімальний відсоток бонусу], SUM(Salary/100*BonusPercent) [Сума всіх бонусів], AVG(Salary/100*BonusPercent) [Середній розмір бонусу], AVG (Salary) [Середній розмір ЗП] FROM Employees WHERE DepartmentID=3 -- врахувати лише ІТ-відділ SELECT DepartmentID, PositionID, BonusPercent, Salary/100*BonusPercent , Salary FROM Employees WHERE DepartmentID=3 -- врахувати лише ІТ-відділ
Йдемо далі. У випадку, якщо агрегатна функція повертає NULL (наприклад, у всіх співробітників не вказано значення Salary), або у вибірку не потрапило жодного запису, а у звіті для такого випадку нам потрібно показати 0, то функцією ISNULL можна обернути агрегатний вираз: SELECT SUM (Salary), AVG (Salary), - обробляємо результат за допомогою ISNULL ISNULL (SUM (Salary), 0), ISNULL (AVG (Salary), 0) FROM Employees WHERE DepartmentID = 10 - тут спеціально зазначений неіснуючий відділ , щоб запит не повернув записів
Я вважаю, що дуже важливо розуміти призначення кожної агрегатної функції і як вони роблять розрахунок, т.к. SQL це головний інструмент, який служить для розрахунку підсумкових значень. У разі ми розглянули, як кожна агрегатна функція поводиться самостійно, тобто. вона застосовувалася до значень всього набору записів, отриманих командою SELECT. Далі ми розглянемо, як ці функції застосовуються для обчислення підсумків по групах, за допомогою конструкції GROUP BY. GROUP BY – угруповання данихДо цього ми вже обчислювали підсумки для конкретного відділу приблизно таким чином:SELECT COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=3 -- дані тільки по ІТ відділу А тепер уявіть, що нас попросили отримати такі ж цифри у розрізі кожного відділу. Звичайно, ми можемо засукати рукави і виконати цей же запит для кожного відділу. Отже, сказано-зроблено, пишемо 4 запити: SELECT "Адміністрація" Info, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=1 -- дані по Адміністрації SELECT "Бухгалтерія" Info, COUNT(DISTINCT PositionID) Position *) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=2 -- дані по Бухгалтерії SELECT "ІТ" Info, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE - дані по ІТ відділу SELECT "Інші" Info, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) Salary В результаті ми отримаємо 4 набори даних:
Зверніть увагу, що ми можемо використовувати поля, задані у вигляді констант – "Адміністрація", "Бухгалтерія", … Загалом усі цифри, про які нас просили, ми здобули, поєднуємо все в Excel і віддаємо директорові. Звіт директору сподобався, і він каже: «а додайте ще колонку з інформацією щодо середнього окладу». І як завжди, це потрібно зробити дуже терміново. Мда, що робити? До того ж уявимо ще відділів у нас не 3, а 15. Ось якраз приблизно для таких випадків служить конструкція GROUP BY: SELECT DepartmentID, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount, AVG(Salary) SalaryAvg - плюс виконуємо побажання директора FROM Employees GROUP BY DepartmentID
Ми отримали ті самі дані, але тепер використовуючи тільки один запит! Поки не звертайте увагу, що департаменти у нас вивелися у вигляді цифр, далі ми навчимося виводити все красиво. У пропозиції GROUP BY можна вказувати кілька полів «GROUP BY поле1, поле2, …, полеN», у цьому випадку угруповання відбудеться за групами, які утворюють значення даних полів «поле1, поле2, …, полеN». Для прикладу зробимо групування даних у розрізі Відділів та Посад: SELECT DepartmentID,PositionID, COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees GROUP BY DepartmentID,PositionID SELECT COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID NULL AND PositionID IS NULL SELECT COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=1 AND Position COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=3 AND PositionID=4 А потім всі ці результати поєднуються разом і віддаються нам у вигляді одного набору:
З основного, слід зазначити, що у разі угруповання (GROUP BY), у переліку колонок у блоці SELECT:
І демонстрація всього сказаного: SELECT "Рядок константа" Const1, - константа у вигляді рядка 1 Const2, - константа у вигляді числа - вираз з використанням полів у групуванні CONCAT("Відділ №",DepartmentID) ConstAndGroupField, CONCAT("Відділ №",DepartmentID ,", Посада № ",PositionID) ConstAndGroupFields, DepartmentID, -- поле зі списку полів у групуванні -- PositionID, -- поле що у групуванні, необов'язково дублювати тут COUNT(*) EmplCount, -- у рядків в кожній групі - інші поля можна використовувати тільки з агрегатними функціями: COUNT, SUM, MIN, MAX, … SUM (Salary) SalaryAmount, MIN (ID) Так само варто відзначити, що угруповання можна робити не лише по полях, але й за виразами. Наприклад згрупуємо дані по співробітникам, за роками народження: SELECT CONCAT("Рік народження - ",YEAR(Birthday)) YearOfBirthday, COUNT(*) EmplCount FROM Employees GROUP BY YEAR(Birthday) Розглянемо приклад із складнішим виразом. Наприклад, отримаємо градацію співробітників за роками народження: SELECT CASE WHEN YEAR(Birthday)>=2000 THEN "від 2000" WHEN YEAR(Birthday)>=1990 THEN "1999-1990" WHEN YEAR(Birthday)>=1980 THEN "1989-19 1970 THEN "1979-1970" WHEN Birthday IS NOT NULL THEN "раніше 1970" ELSE "не вказано" END RangeName, COUNT(*) (Birthday)>=1990 THEN "1999-1990" WHEN YEAR (Birthday)>=1980 THEN "1989-1980" WHEN YEAR (Birthday)>=1970 THEN "1979-1970" WHEN Bien ELSE "не вказано" END
Тобто. у цьому випадку угруповання проводиться за попередньо обчисленим для кожного співробітника CASE-виразом: SELECT ID, CASE WHEN YEAR(Birthday)>=2000 THEN "від 2000" WHEN YEAR(Birthday)>=1990 THEN "1999-1990" WHEN YEAR(Birthday)>=1980 THEN "1989 >=1970 THEN "1979-1970" WHEN Birthday IS NOT NULL THEN "раніше 1970" ELSE "не вказано" END FROM Employees
Ну і звичайно ж ви можете поєднувати в блоці GROUP BY вирази з полями: SELECT DepartmentID, CONCAT("Рік народження - ",YEAR(Birthday)) YearOfBirthday, COUNT(*) EmplCount FROM Employees GROUP BY YEAR(Birthday),DepartmentID -- порядок може не збігатися з порядком їх використання в блоці SELECT ORDER YearOfBirthday - наостанок ми можемо застосувати до результату сортування Повернемося до нашого початкового завдання. Як ми вже знаємо, звіт дуже сподобався директору, і він попросив нас робити його щотижня, щоб він міг моніторити зміни компанії. Щоб не перебивати щоразу в Excel цифрове значення відділу на його найменування, скористаємося знаннями, які ми вже маємо, і вдосконалимо наш запит: SELECT CASE DepartmentID WHEN 1 THEN "Адміністрація" WHEN 2 THEN "Бухгалтерія" WHEN 3 THEN "ІТ" ELSE "Інші" END Info, COUNT(DISTINCT PositionID) ) SalaryAvg -- плюс виконуємо побажання директора FROM Employees GROUP BY DepartmentID ORDER BY Info -- додамо для більшої зручності сортування по колонці Info Але нічого, з часом, ми навчимося робити все красиво, щоб вибірка у нас не залежала від появи в БД нових даних, а була динамічною. Трохи забігу вперед, щоб показати написання яких запитів ми прагнемо прийти: SELECT ISNULL(dep.Name,"Інші") DepName, COUNT(DISTINCT emp.PositionID) PositionCount, COUNT(*) EmplCount, SUM(emp.Salary) SalaryAmount, AVG(emp.Salary) SalaryAvg - плюс виконуємо побажання директора FROM Employees emp LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID GROUP BY emp.DepartmentID,dep.Name ORDER BY DepName Загалом, не переживайте – всі починали просто. Поки що вам просто потрібно зрозуміти суть конструкції GROUP BY. Насамкінець, давайте подивимося яким чином можна будувати зведені звіти за допомогою GROUP BY. Для прикладу виведемо зведену таблицю, в розрізі відділів, так щоб була підрахована сумарна заробітна плата, яку отримують співробітники в розбивці за посадами: SELECT DepartmentID, SUM(CASE WHEN PositionID=1 THEN Salary END) [Бухгалтера], SUM(CASE WHEN PositionID=2 THEN Salary END) [Директора], SUM(CASE WHEN PositionID=3 THEN Salary END) [Програмісти], SUM CASE WHEN PositionID=4 THEN Salary END) [Старші програмісти], SUM(Salary) [Разом з відділу] FROM Employees GROUP BY DepartmentID Можна, звичайно, переписати і за допомогою IIF: SELECT DepartmentID, SUM(IIF(PositionID=1,Salary,NULL)) [Бухгалтера], SUM(IIF(PositionID=2,Salary,NULL)) [Директора], SUM(IIF(PositionID=3,Salary,NULL)) [Програмісти], SUM(IIF(PositionID=4,Salary,NULL)) [Старші програмісти], SUM(Salary) [Разом у відділі] FROM Employees GROUP BY DepartmentID Але у випадку IIF нам доведеться явно вказувати NULL, яке повертається у разі невиконання умови. В аналогічних випадках мені більше подобається використовувати CASE без блоку ELSE, ніж писати NULL. Але це, звичайно, справа смаку, про який не сперечаються. І давайте згадаємо, що в агрегатних функціях при агрегації не враховуються значення NULL. Для закріплення зробіть самостійний аналіз отриманих даних за розгорнутим запитом: SELECT DepartmentID, CASE WHEN PositionID=1 THEN Salary END [Бухгалтера], CASE WHEN PositionID=2 THEN Salary END [Директора], CASE WHEN PositionID=3 THEN Salary END [Програмісти], CASE WHEN PositionID=4 THEN ], Salary [Разом по відділу] FROM Employees
І ще давайте згадаємо, що якщо замість NULL ми хочемо побачити нулі, то ми можемо обробити значення, яке повертається агрегатною функцією. Наприклад: SELECT DepartmentID, ISNULL(SUM(IIF(PositionID=1,Salary,NULL)),0) [Бухгалтера], ISNULL(SUM(IIF(PositionID=2,Salary,NULL)),0) [Директора], ISNULL(SUM (IIF(PositionID=3,Salary,NULL)),0) [Програмісти], ISNULL(SUM(IIF(PositionID=4,Salary,NULL)),0) [Старші програмісти], ISNULL(SUM(Salary),0 ) [Разом по відділу] FROM Employees GROUP BY DepartmentID
GROUP BY у скупі з агрегатними функціями, один з основних засобів, що служать для отримання зведених даних з БД, адже зазвичай дані у такому вигляді і використовуються, т.к. зазвичай від нас вимагають надання зведених звітів, а не детальних даних (простирадла). І звичайно все це крутиться навколо знання базової конструкції, т.к. перш ніж щось підсумувати (агрегувати), вам потрібно насамперед це правильно вибрати, використовуючи "SELECT ... WHERE ...". Важливе місце тут має практика, тому, якщо ви поставили метою зрозуміти мову SQL, не вивчити, а саме зрозуміти - практикуйтеся, практикуйтеся і практикуйтеся, перебираючи різні варіанти, які тільки зможете придумати. На початкових порах, якщо ви не впевнені в правильності отриманих агрегованих даних, робіть детальну вибірку, яка включає всі значення, якими йде агрегація. І перевіряйте правильність розрахунків вручну за цими детальними даними. У цьому випадку дуже може допомогти використання програми Excel. Припустимо, що ви дійшли до цього моментуДопустимо, що ви бухгалтер Сидоров С.С., який вирішив навчитися писати SELECT-запити.Припустимо, що ви вже встигли дочитати цей підручник до цього моменту, і вже впевнено користуєтесь усіма перерахованими базовими конструкціями, тобто. ви вмієте:
Так, але вони не врахували, що ви не вмієте будувати запити з кількох таблиць, лише з однієї, тобто. ви не вмієте робити щось на кшталт такого: SELECT emp.*, -- повернути всі поля таблиці Employees dep.Name DepartmentName, -- до цих полів додати поле Name з таблиці Departments pos.Name PositionName -- та ще додати поле Name з таблиці Positions FROM Employees emp LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID LEFT JOIN Positions pos ON emp.PositionID=pos.ID І так, як можна скористатися вашими поточними знаннями і отримати при цьому ще більш продуктивні результати?! Скористаємося силою колективного розуму – йдемо до програмістів, які у вас, тобто. до Андрєєва А.А., Петрова П.П. або Миколаєву Н.Н., і попросимо когось із них написати для вас уявлення (VIEW або просто «В'юха», так вони навіть, думаю, швидше зрозуміють вас), яке крім основних полів з таблиці Employees, ще повертатиме поля з "Назвою відділу" та "Назвою посади", яких вам так бракує зараз для щотижневого звіту, яким вас завантажив Іванов І.І. Т.к. ви всі грамотно пояснили, то ІТ-шники, відразу ж зрозуміли, що від них хочуть і створили, спеціально для вас, уявлення з назвою ViewEmployeesInfo. Уявляємо, що наступної команди не бачите, т.к. це роблять ІТ-шники: CREATE VIEW ViewEmployeesInfo AS SELECT emp.*, -- повернути всі поля таблиці Employees dep.Name DepartmentName, -- до цих полів додати поле Name з таблиці Departments pos.Name PositionName -- і додати поле Name з таблиці Positions FROM Employees emp LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID LEFT JOIN Positions pos ON emp.PositionID=pos.ID Тобто. для вас весь цей, поки страшний і незрозумілий, текст залишається за кадром, а ІТ-шники дають вам тільки назву уявлення «ViewEmployeesInfo», яке повертає всі вищезазначені дані (тобто те, що ви у них просили). Ви тепер можете працювати з даним поданням, як зі звичайною таблицею: SELECT * FROM ViewEmployeesInfo SELECT DepartmentName, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount, AVG(Salary) SalaryAvg FROM ViewEmployeesInfo emp GROUP BY DepartmentID,DepartmentName ORDER BY DepartmentName Тобто. Вам у цьому випадку, ніби нічого і не змінилося, ви продовжуєте так само працювати з однією таблицею (тільки вже правильніше сказати з поданням ViewEmployeesInfo), яке повертає всі необхідні вам дані. Завдяки допомозі ІТ-шників, деталі з добування DepartmentName і PositionName залишилися для вас у чорній скриньці. Тобто. уявлення вам виглядає так само, як і звичайна таблиця, вважайте, що це розширена версія таблиці Employees. Давайте для прикладу ще сформуємо відомість, щоб ви переконалися, що все дійсно так, як я і говорив (що вся вибірка йде з одного уявлення): SELECT ID, Name, Salary FROM ViewEmployeesInfo WHERE Salary IS NOT NULL AND Salary>0 ORDER BY Name Використання уявлень у деяких випадках дає можливість значно розширити межі користувачів, які мають написання базових SELECT-запитів. В даному випадку представлення, являє собою плоску таблицю з усіма необхідними користувачеві даними (для тих, хто розуміється на OLAP, це можна порівняти з наближеною подобою OLAP-куба з фактами та вимірами). Вирізка із вікіпедії.Хоча SQL і замислювався як роботи кінцевого користувача, зрештою він став настільки складним, що перетворився на інструмент програміста. Як бачите, шановні користувачі, мова SQL спочатку замислювався як інструмент для вас. Отже, все у ваших руках та бажанні, не відпускайте руки. HAVING – накладення умови вибірки до згрупованих данихВласне якщо ви зрозуміли, що таке угруповання, то з HAVING нічого складного немає. HAVING – чимось подібний до WHERE, тільки якщо WHERE-умова застосовується до детальних даних, то HAVING-умова застосовується до вже згрупованих даних. З цієї причини в умовах блоку HAVING ми можемо використовувати або вирази з полями, що входять до угруповання, або вирази, що містяться в агрегатних функціях.Розглянемо приклад: SELECT DepartmentID, SUM(Salary) SalaryAmount FROM Employees GROUP BY DepartmentID HAVING SUM(Salary)>3000
Тобто. даний запит повернув нам згруповані дані лише з тим відділам, які мають сума ЗП всіх співробітників перевищує 3000, тобто. "SUM (Salary)> 3000".
Тобто. тут у першу чергу відбувається угруповання та обчислюються дані по всіх відділах: SELECT DepartmentID, SUM(Salary) SalaryAmount FROM Employees GROUP BY DepartmentID -- 1. отримуємо згруповані дані по всіх відділах А вже до цих даних застосовується умова, зазначена в блоці HAVING: SELECT DepartmentID, SUM(Salary) SalaryAmount FROM Employees GROUP BY DepartmentID -- 1. отримуємо згруповані дані по всіх відділах HAVING SUM(Salary)>3000 -- 2. умова для фільтрації згрупованих даних У HAVING-умові так само можна будувати складні умови, використовуючи оператори AND, OR та NOT: SELECT DepartmentID, SUM(Salary) SalaryAmount FROM Employees GROUP BY DepartmentID HAVING SUM(Salary)>3000 AND COUNT(*)<2 -- и число людей меньше 2-х
Як можна помітити тут агрегатна функція (див. «COUNT(*)») може бути вказана тільки в блоці HAVING. Відповідно ми можемо відобразити лише номер відділу, що підпадає під HAVING-умову: SELECT DepartmentID FROM Employees GROUP BY DepartmentID HAVING SUM(Salary)>3000 AND COUNT(*)<2 -- и число людей меньше 2-х Приклад використання HAVING-умови поля включеного в GROUP BY: SELECT DepartmentID, SUM(Salary) SalaryAmount FROM Employees GROUP BY DepartmentID -- 1. зробити групування HAVING DepartmentID=3 -- 2. накласти фільтр на результат угруповання Це лише приклад, т.к. в даному випадку перевірку логічніше було б зробити через WHERE-умову: SELECT DepartmentID, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=3 - 1. провести фільтрацію детальних даних GROUP BY DepartmentID - 2. зробити угруповання тільки за відібраними записами Тобто. спочатку відфільтрувати співробітників з відділу 3, і потім зробити розрахунок. Примітка.Насправді, незважаючи на те, що ці два запити виглядають по-різному, оптимізатор СУБД може виконати їх однаково. Думаю, на цьому розповідь про HAVING-умови можна закінчити. Підведемо підсумкиЗведемо дані отримані у другій та третій частині та розглянемо конкретне місце розташування кожної вивченої нами конструкції та вкажемо порядок їх виконання:
Звичайно, ви також можете застосувати до згрупованих даних пропозиції DISTINCT і TOP, вивчені в другій частині. Ці пропозиції в цьому випадку застосовуються до остаточного результату: SELECT TOP 1 -- 6. застосовується в останню чергу SUM(Salary) SalaryAmount FROM Employees GROUP BY DepartmentID HAVING SUM(Salary)>3000 ORDER BY DepartmentID -- 5. сортування результату Як вийшли дані результати, проаналізуйте самостійно. ВисновокОсновна мета яку я ставив у цій частині – розкрити вам суть агрегатних функцій та угруповань.Якщо базова конструкція дозволяла нам отримати необхідні детальні дані, то застосування агрегатних функцій та угруповань до цих детальних даних дало нам можливість отримати по них зведені дані. Отже, як бачите тут усе важливе, т.к. одне спирається інше – без знання базової конструкції ми зможемо, наприклад, правильно відібрати дані, якими нам треба прорахувати результати. Тут я навмисно намагаюся показувати лише основи, щоб зосередити увагу початківців на найголовніших конструкціях та не перевантажувати їх зайвою інформацією. Тверде розуміння основних конструкцій (про які я ще продовжу розповідь у наступних частинах) дасть вам можливість вирішити практично будь-яке завдання щодо вибірки даних з РБД. Основні конструкції оператора SELECT застосовні в такому вигляді практично у всіх СУБД (відмінності в основному складаються в деталях, наприклад, в реалізації функцій - для роботи з рядками, часом, і т.д.). Надалі, тверде знання бази дасть вам можливість самостійно легко вивчити різні розширення мови SQL, такі як:
Якщо ви робите перші кроки в SQL, то зосередьтеся насамперед, саме з вивченні базових конструкцій, т.к. володіючи базою, все інше вам зрозуміти буде набагато легше, до того ж самостійно. Вам насамперед, хіба що потрібно об'ємно зрозуміти можливості мови SQL, тобто. які операції він взагалі дозволяє зробити над даними. Донести до початківців інформацію в об'ємному вигляді – це ще одна з причин, чому я показуватиму тільки найголовніші (залізні) конструкції. Успіхів вам у вивченні та розумінні мови SQL. Частина четверта -
Про що буде розказано у цій частиніУ цій частині ми познайомимося:
CASE – умовний оператор мови SQLЦей оператор дозволяє здійснити перевірку умов і повернути залежно від виконання тієї чи іншої умови той чи інший результат.Оператор CASE має 2 форми: Розберемо з прикладу першу форму CASE: SELECT ID,Name,Salary, CASE WHEN Salary>=3000 THEN "ЗП >= 3000" WHEN Salary>=2000 THEN "2000<= ЗП < 3000"
ELSE "ЗП < 2000"
END SalaryTypeWithELSE,
CASE
WHEN Salary>=3000 THEN "ЗП >= 3000" WHEN Salary>=2000 THEN "2000<= ЗП < 3000"
END SalaryTypeWithoutELSE
FROM Employees
Якщо жодна з WHEN-умов не виконується, то повертається значення, вказане після слова ELSE (що в даному випадку означає «ІНАЧЕ ВЕРНІ…»). Якщо ELSE-блок не вказано і не виконується жодна умова WHEN, то повертається NULL. І в першій, і в другій формі ELSE-блок йде наприкінці конструкції CASE, тобто. після всіх WHEN умов. Розберемо з прикладу другу форму CASE: Припустимо, на новий рік вирішили преміювати всіх співробітників та попросили обчислити суму бонусів за наступною схемою:
Використовуємо для цієї задачі запит із виразом CASE: SELECT ID,Name,Salary,DepartmentID, -- для наочності виведемо відсоток у вигляді рядка CASE DepartmentID -- значення WHEN 2 THEN "10%" -- 10% від ЗП видати Бухгалтерам WHEN 3 THEN "15%" -- 15% від ЗП видати ІТ-шникам ELSE "5%" - решті по 5% END NewYearBonusPercent, - побудуємо вираз із використанням CASE, щоб побачити суму бонусу Salary/100* CASE DepartmentID WHEN 2 THEN 10 - 10% від ЗП видати Бухгалтерам WHEN 3 THEN 15 -- 15% від ЗП видати ІТ-шникам ELSE 5 -- решті по 5% END BonusAmount FROM Employees Відповідно, значення блоку ELSE повертається у разі, якщо DepartmentID не збігся з жодним WHEN-значенням. Якщо блок ELSE відсутній, то у разі розбіжності DepartmentID з жодним WHEN-значенням буде повернуто NULL. Другу форму CASE нескладно уявити за допомогою першої форми: SELECT ID,Name,Salary,DepartmentID,CASE WHEN DepartmentID=2 THEN "10%" -- 10% від ЗП видати Бухгалтерам WHEN DepartmentID=3 THEN "15%" -- 15% від ЗП видати ІТ-шникам ELSE "5% " -- всім іншим по 5% END NewYearBonusPercent, -- побудуємо вираз із використанням CASE, щоб побачити суму бонусу Salary/100* CASE WHEN DepartmentID=2 THEN 10 -- 10% від ЗП видати Бухгалтерам WHEN DepartmentID=3 THEN 15 -- 15% від ЗП видати ІТ-шникам ELSE 5 - решті по 5% END BonusAmount FROM Employees Так, друга форма – це лише спрощена запис для тих випадків, коли нам потрібно зробити порівняння на рівність, одного й того ж значення, що перевіряється з кожним WHEN-значенням/виразом. Примітка.Перша та друга форма CASE входять до стандарту мови SQL, тому швидше за все вони мають бути застосовані у багатьох СУБД. З MS SQL версії 2012 року з'явилася спрощена форма запису IIF. Вона може використовуватися для спрощеного запису конструкції CASE, якщо повертаються тільки 2 значення. Конструкція IIF має такий вигляд: IIF (умова, true_значення, false_значення) Тобто. по суті це обгортка для наступної CASE конструкції: CASE WHEN умова THEN true_значення ELSE false_значення END Подивимося на прикладі: SELECT ID,Name,Salary, IIF(Salary>=2500,"ЗП >= 2500","ЗП< 2500") DemoIIF, CASE WHEN Salary>=2500 THEN "ЗП >= 2500" ELSE "ЗП< 2500" END DemoCASE FROM Employees Конструкції CASE, IIF можуть бути вкладеними одна в одну. Розглянемо абстрактний приклад: SELECT ID,Name,Salary, CASE WHEN DepartmentID IN(1,2) THEN "A" WHEN DepartmentID=3 THEN CASE PositionID -- вкладений CASE WHEN 3 THEN "B-1" WHEN 4 THEN "B-2" END ELSE " C" END Demo1, IIF(DepartmentID IN(1,2),"A", IIF(DepartmentID=3,CASE PositionID WHEN 3 THEN "B-1" WHEN 4 THEN "B-2" END,"C")) Demo2 FROM Employees Оскільки конструкція CASE і IIF представляють собою вираз, які повертають результат, ми можемо використовувати їх у блоці SELECT, а й у інших блоках, допускають використання виразів, наприклад, у блоках WHERE чи ORDER BY. Для прикладу, нехай перед нами поставили завдання створити список на видачу ЗП на руки, таким чином:
Спробуємо вирішити це завдання за допомогою додавання CASE-вираження до блоку ORDER BY: SELECT ID,Name,Salary FROM Employees ORDER BY CASE WHEN Salary>=2500 THEN 1 ELSE 0 END, -- видати ЗП спочатку тим у кого вона нижче 2500 Name -- далі впорядкувати список у порядку ПІБ І абстрактний приклад використання CASE у блоці WHERE: SELECT ID,Name,Salary FROM Employees WHERE CASE WHEN Salary>=2500 THEN 1 ELSE 0 END=1 -- всі записи яких вираз дорівнює 1 Можете спробувати самостійно переробити 2 останні приклади з функцією IIF. І насамкінець, згадаємо ще раз про NULL-значення: SELECT ID,Name,Salary,DepartmentID,CASE WHEN DepartmentID=2 THEN "10%" -- 10% від ЗП видати Бухгалтерам WHEN DepartmentID=3 THEN "15%" -- 15% від ЗП видати ІТ-шникам WHEN DepartmentID IS NULL THEN "-" -- позаштатникам бонусів не даємо (використовуємо IS NULL) ELSE "5%" -- всім іншим по 5% END NewYearBonusPercent1, -- а так перевіряти на NULL не можна, згадуємо що йшлося про NULL у другій частині CASE DepartmentID - - значення WHEN 2 THEN "10%" WHEN 3 THEN "15%" WHEN NULL THEN "-" -- !!! у цьому випадку використання другої форми CASE не підходить ELSE "5%" END NewYearBonusPercent2 FROM Employees SELECT ID,Name,Salary,DepartmentID, CASE ISNULL(DepartmentID,-1) -- використовуємо заміну у разі NULL на -1 WHEN 2 THEN "10%" WHEN 3 THEN "15%" WHEN -1 THEN "-" -- якщо ми впевнені, що відділу з ID рівним (-1) немає і не буде ELSE "5%" END NewYearBonusPercent3 FROM Employees Загалом політ фантазії в даному випадку не обмежений. Наприклад подивимося, як з допомогою CASE і IIF можна змоделювати функцію ISNULL: SELECT ID,Name,LastName, ISNULL(LastName,"Не вказано") DemoISNULL, CASE WHEN LastName IS NULL THEN "Не вказано" ELSE LastName END DemoCASE, IIF(LastName IS NULL,"Не вказано",LastName) Конструкція CASE є дуже потужним засобом мови SQL, який дозволяє накласти додаткову логіку для розрахунку значень результуючого набору. У цій частині володіння CASE-конструкцією нам ще знадобиться, тому в цій частині насамперед увага приділена саме їй. Агрегатні функціїТут ми розглянемо лише основні і найчастіше використовувані агрегатні функції:
Агрегатні функції дозволяють зробити розрахунок підсумкового значення для набору рядків отриманих з допомогою оператора SELECT. Розглянемо кожну функцію з прикладу: SELECT COUNT(*) [Загальна кількість співробітників], COUNT(DISTINCT DepartmentID) [Кількість унікальних відділів], COUNT(DISTINCT PositionID) [Кількість унікальних посад], COUNT(BonusPercent) [Кількість співробітників, у яких вказано % бонуса] , MAX(BonusPercent) [Максимальний відсоток бонусу], MIN(BonusPercent) [Мінімальний відсоток бонусу], SUM(Salary/100*BonusPercent) [Сума всіх бонусів], AVG(Salary/100*BonusPercent) [Середній розмір бонусу], AVG (Salary) [Середній розмір ЗП] FROM Employees Розберемо яким чином вийшло кожне повернене значення, а за одне згадаємо конструкції базового синтаксису оператора SELECT. По-перше, т.к. ми в запиті не вказали WHERE-умови, то підсумки будуть вважатися для детальних даних, які виходять запитом: SELECT * FROM Employees Тобто. всім рядків таблиці Employees. Для наочності виберемо лише поля та вирази, які використовуються в агрегатних функціях: SELECT DepartmentID, PositionID, BonusPercent, Salary/100*BonusPercent , Salary FROM Employees
Це вихідні дані (детальні рядки), за якими і будуть рахуватися підсумки агрегованого запиту. Тепер розберемо кожне агреговане значення:
Підіб'ємо деякі підсумки:
Відповідно при завданні з агрегатними функціями додаткової умови в блоці WHERE, будуть підраховані лише підсумки, що за рядками задовольняють умові. Тобто. Розрахунок агрегатних значень відбувається для підсумкового набору, отриманого за допомогою конструкції SELECT. Наприклад, зробимо все те саме, але тільки в розрізі ІТ-відділу: SELECT COUNT(*) [Загальна кількість співробітників], COUNT(DISTINCT DepartmentID) [Кількість унікальних відділів], COUNT(DISTINCT PositionID) [Кількість унікальних посад], COUNT(BonusPercent) [Кількість співробітників, у яких вказано % бонуса] , MAX(BonusPercent) [Максимальний відсоток бонусу], MIN(BonusPercent) [Мінімальний відсоток бонусу], SUM(Salary/100*BonusPercent) [Сума всіх бонусів], AVG(Salary/100*BonusPercent) [Середній розмір бонусу], AVG (Salary) [Середній розмір ЗП] FROM Employees WHERE DepartmentID=3 -- врахувати лише ІТ-відділ SELECT DepartmentID, PositionID, BonusPercent, Salary/100*BonusPercent , Salary FROM Employees WHERE DepartmentID=3 -- врахувати лише ІТ-відділ
Йдемо далі. У випадку, якщо агрегатна функція повертає NULL (наприклад, у всіх співробітників не вказано значення Salary), або у вибірку не потрапило жодного запису, а у звіті для такого випадку нам потрібно показати 0, то функцією ISNULL можна обернути агрегатний вираз: SELECT SUM (Salary), AVG (Salary), - обробляємо результат за допомогою ISNULL ISNULL (SUM (Salary), 0), ISNULL (AVG (Salary), 0) FROM Employees WHERE DepartmentID = 10 - тут спеціально зазначений неіснуючий відділ , щоб запит не повернув записів
Я вважаю, що дуже важливо розуміти призначення кожної агрегатної функції і як вони роблять розрахунок, т.к. SQL це головний інструмент, який служить для розрахунку підсумкових значень. У разі ми розглянули, як кожна агрегатна функція поводиться самостійно, тобто. вона застосовувалася до значень всього набору записів, отриманих командою SELECT. Далі ми розглянемо, як ці функції застосовуються для обчислення підсумків по групах, за допомогою конструкції GROUP BY. GROUP BY – угруповання данихДо цього ми вже обчислювали підсумки для конкретного відділу приблизно таким чином:SELECT COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=3 -- дані тільки по ІТ відділу А тепер уявіть, що нас попросили отримати такі ж цифри у розрізі кожного відділу. Звичайно, ми можемо засукати рукави і виконати цей же запит для кожного відділу. Отже, сказано-зроблено, пишемо 4 запити: SELECT "Адміністрація" Info, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=1 -- дані по Адміністрації SELECT "Бухгалтерія" Info, COUNT(DISTINCT PositionID) Position *) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=2 -- дані по Бухгалтерії SELECT "ІТ" Info, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE - дані по ІТ відділу SELECT "Інші" Info, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) Salary В результаті ми отримаємо 4 набори даних:
Зверніть увагу, що ми можемо використовувати поля, задані у вигляді констант – "Адміністрація", "Бухгалтерія", … Загалом усі цифри, про які нас просили, ми здобули, поєднуємо все в Excel і віддаємо директорові. Звіт директору сподобався, і він каже: «а додайте ще колонку з інформацією щодо середнього окладу». І як завжди, це потрібно зробити дуже терміново. Мда, що робити? До того ж уявимо ще відділів у нас не 3, а 15. Ось якраз приблизно для таких випадків служить конструкція GROUP BY: SELECT DepartmentID, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount, AVG(Salary) SalaryAvg - плюс виконуємо побажання директора FROM Employees GROUP BY DepartmentID
Ми отримали ті самі дані, але тепер використовуючи тільки один запит! Поки не звертайте увагу, що департаменти у нас вивелися у вигляді цифр, далі ми навчимося виводити все красиво. У пропозиції GROUP BY можна вказувати кілька полів «GROUP BY поле1, поле2, …, полеN», у цьому випадку угруповання відбудеться за групами, які утворюють значення даних полів «поле1, поле2, …, полеN». Для прикладу зробимо групування даних у розрізі Відділів та Посад: SELECT DepartmentID,PositionID, COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees GROUP BY DepartmentID,PositionID SELECT COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID NULL AND PositionID IS NULL SELECT COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=1 AND Position COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=3 AND PositionID=4 А потім всі ці результати поєднуються разом і віддаються нам у вигляді одного набору:
З основного, слід зазначити, що у разі угруповання (GROUP BY), у переліку колонок у блоці SELECT:
І демонстрація всього сказаного: SELECT "Рядок константа" Const1, - константа у вигляді рядка 1 Const2, - константа у вигляді числа - вираз з використанням полів у групуванні CONCAT("Відділ №",DepartmentID) ConstAndGroupField, CONCAT("Відділ №",DepartmentID ,", Посада № ",PositionID) ConstAndGroupFields, DepartmentID, -- поле зі списку полів у групуванні -- PositionID, -- поле що у групуванні, необов'язково дублювати тут COUNT(*) EmplCount, -- у рядків в кожній групі - інші поля можна використовувати тільки з агрегатними функціями: COUNT, SUM, MIN, MAX, … SUM (Salary) SalaryAmount, MIN (ID) Так само варто відзначити, що угруповання можна робити не лише по полях, але й за виразами. Наприклад згрупуємо дані по співробітникам, за роками народження: SELECT CONCAT("Рік народження - ",YEAR(Birthday)) YearOfBirthday, COUNT(*) EmplCount FROM Employees GROUP BY YEAR(Birthday) Розглянемо приклад із складнішим виразом. Наприклад, отримаємо градацію співробітників за роками народження: SELECT CASE WHEN YEAR(Birthday)>=2000 THEN "від 2000" WHEN YEAR(Birthday)>=1990 THEN "1999-1990" WHEN YEAR(Birthday)>=1980 THEN "1989-19 1970 THEN "1979-1970" WHEN Birthday IS NOT NULL THEN "раніше 1970" ELSE "не вказано" END RangeName, COUNT(*) (Birthday)>=1990 THEN "1999-1990" WHEN YEAR (Birthday)>=1980 THEN "1989-1980" WHEN YEAR (Birthday)>=1970 THEN "1979-1970" WHEN Bien ELSE "не вказано" END
Тобто. у цьому випадку угруповання проводиться за попередньо обчисленим для кожного співробітника CASE-виразом: SELECT ID, CASE WHEN YEAR(Birthday)>=2000 THEN "від 2000" WHEN YEAR(Birthday)>=1990 THEN "1999-1990" WHEN YEAR(Birthday)>=1980 THEN "1989 >=1970 THEN "1979-1970" WHEN Birthday IS NOT NULL THEN "раніше 1970" ELSE "не вказано" END FROM Employees
Ну і звичайно ж ви можете поєднувати в блоці GROUP BY вирази з полями: SELECT DepartmentID, CONCAT("Рік народження - ",YEAR(Birthday)) YearOfBirthday, COUNT(*) EmplCount FROM Employees GROUP BY YEAR(Birthday),DepartmentID -- порядок може не збігатися з порядком їх використання в блоці SELECT ORDER YearOfBirthday - наостанок ми можемо застосувати до результату сортування Повернемося до нашого початкового завдання. Як ми вже знаємо, звіт дуже сподобався директору, і він попросив нас робити його щотижня, щоб він міг моніторити зміни компанії. Щоб не перебивати щоразу в Excel цифрове значення відділу на його найменування, скористаємося знаннями, які ми вже маємо, і вдосконалимо наш запит: SELECT CASE DepartmentID WHEN 1 THEN "Адміністрація" WHEN 2 THEN "Бухгалтерія" WHEN 3 THEN "ІТ" ELSE "Інші" END Info, COUNT(DISTINCT PositionID) ) SalaryAvg -- плюс виконуємо побажання директора FROM Employees GROUP BY DepartmentID ORDER BY Info -- додамо для більшої зручності сортування по колонці Info Але нічого, з часом, ми навчимося робити все красиво, щоб вибірка у нас не залежала від появи в БД нових даних, а була динамічною. Трохи забігу вперед, щоб показати написання яких запитів ми прагнемо прийти: SELECT ISNULL(dep.Name,"Інші") DepName, COUNT(DISTINCT emp.PositionID) PositionCount, COUNT(*) EmplCount, SUM(emp.Salary) SalaryAmount, AVG(emp.Salary) SalaryAvg - плюс виконуємо побажання директора FROM Employees emp LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID GROUP BY emp.DepartmentID,dep.Name ORDER BY DepName Загалом, не переживайте – всі починали просто. Поки що вам просто потрібно зрозуміти суть конструкції GROUP BY. Насамкінець, давайте подивимося яким чином можна будувати зведені звіти за допомогою GROUP BY. Для прикладу виведемо зведену таблицю, в розрізі відділів, так щоб була підрахована сумарна заробітна плата, яку отримують співробітники в розбивці за посадами: SELECT DepartmentID, SUM(CASE WHEN PositionID=1 THEN Salary END) [Бухгалтера], SUM(CASE WHEN PositionID=2 THEN Salary END) [Директора], SUM(CASE WHEN PositionID=3 THEN Salary END) [Програмісти], SUM CASE WHEN PositionID=4 THEN Salary END) [Старші програмісти], SUM(Salary) [Разом з відділу] FROM Employees GROUP BY DepartmentID Можна, звичайно, переписати і за допомогою IIF: SELECT DepartmentID, SUM(IIF(PositionID=1,Salary,NULL)) [Бухгалтера], SUM(IIF(PositionID=2,Salary,NULL)) [Директора], SUM(IIF(PositionID=3,Salary,NULL)) [Програмісти], SUM(IIF(PositionID=4,Salary,NULL)) [Старші програмісти], SUM(Salary) [Разом у відділі] FROM Employees GROUP BY DepartmentID Але у випадку IIF нам доведеться явно вказувати NULL, яке повертається у разі невиконання умови. В аналогічних випадках мені більше подобається використовувати CASE без блоку ELSE, ніж писати NULL. Але це, звичайно, справа смаку, про який не сперечаються. І давайте згадаємо, що в агрегатних функціях при агрегації не враховуються значення NULL. Для закріплення зробіть самостійний аналіз отриманих даних за розгорнутим запитом: SELECT DepartmentID, CASE WHEN PositionID=1 THEN Salary END [Бухгалтера], CASE WHEN PositionID=2 THEN Salary END [Директора], CASE WHEN PositionID=3 THEN Salary END [Програмісти], CASE WHEN PositionID=4 THEN ], Salary [Разом по відділу] FROM Employees
І ще давайте згадаємо, що якщо замість NULL ми хочемо побачити нулі, то ми можемо обробити значення, яке повертається агрегатною функцією. Наприклад: SELECT DepartmentID, ISNULL(SUM(IIF(PositionID=1,Salary,NULL)),0) [Бухгалтера], ISNULL(SUM(IIF(PositionID=2,Salary,NULL)),0) [Директора], ISNULL(SUM (IIF(PositionID=3,Salary,NULL)),0) [Програмісти], ISNULL(SUM(IIF(PositionID=4,Salary,NULL)),0) [Старші програмісти], ISNULL(SUM(Salary),0 ) [Разом по відділу] FROM Employees GROUP BY DepartmentID
GROUP BY у скупі з агрегатними функціями, один з основних засобів, що служать для отримання зведених даних з БД, адже зазвичай дані у такому вигляді і використовуються, т.к. зазвичай від нас вимагають надання зведених звітів, а не детальних даних (простирадла). І звичайно все це крутиться навколо знання базової конструкції, т.к. перш ніж щось підсумувати (агрегувати), вам потрібно насамперед це правильно вибрати, використовуючи "SELECT ... WHERE ...". Важливе місце тут має практика, тому, якщо ви поставили метою зрозуміти мову SQL, не вивчити, а саме зрозуміти - практикуйтеся, практикуйтеся і практикуйтеся, перебираючи різні варіанти, які тільки зможете придумати. На початкових порах, якщо ви не впевнені в правильності отриманих агрегованих даних, робіть детальну вибірку, яка включає всі значення, якими йде агрегація. І перевіряйте правильність розрахунків вручну за цими детальними даними. У цьому випадку дуже може допомогти використання програми Excel. Припустимо, що ви дійшли до цього моментуДопустимо, що ви бухгалтер Сидоров С.С., який вирішив навчитися писати SELECT-запити.Припустимо, що ви вже встигли дочитати цей підручник до цього моменту, і вже впевнено користуєтесь усіма перерахованими базовими конструкціями, тобто. ви вмієте:
Так, але вони не врахували, що ви не вмієте будувати запити з кількох таблиць, лише з однієї, тобто. ви не вмієте робити щось на кшталт такого: SELECT emp.*, -- повернути всі поля таблиці Employees dep.Name DepartmentName, -- до цих полів додати поле Name з таблиці Departments pos.Name PositionName -- та ще додати поле Name з таблиці Positions FROM Employees emp LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID LEFT JOIN Positions pos ON emp.PositionID=pos.ID І так, як можна скористатися вашими поточними знаннями і отримати при цьому ще більш продуктивні результати?! Скористаємося силою колективного розуму – йдемо до програмістів, які у вас, тобто. до Андрєєва А.А., Петрова П.П. або Миколаєву Н.Н., і попросимо когось із них написати для вас уявлення (VIEW або просто «В'юха», так вони навіть, думаю, швидше зрозуміють вас), яке крім основних полів з таблиці Employees, ще повертатиме поля з "Назвою відділу" та "Назвою посади", яких вам так бракує зараз для щотижневого звіту, яким вас завантажив Іванов І.І. Т.к. ви всі грамотно пояснили, то ІТ-шники, відразу ж зрозуміли, що від них хочуть і створили, спеціально для вас, уявлення з назвою ViewEmployeesInfo. Уявляємо, що наступної команди не бачите, т.к. це роблять ІТ-шники: CREATE VIEW ViewEmployeesInfo AS SELECT emp.*, -- повернути всі поля таблиці Employees dep.Name DepartmentName, -- до цих полів додати поле Name з таблиці Departments pos.Name PositionName -- і додати поле Name з таблиці Positions FROM Employees emp LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID LEFT JOIN Positions pos ON emp.PositionID=pos.ID Тобто. для вас весь цей, поки страшний і незрозумілий, текст залишається за кадром, а ІТ-шники дають вам тільки назву уявлення «ViewEmployeesInfo», яке повертає всі вищезазначені дані (тобто те, що ви у них просили). Ви тепер можете працювати з даним поданням, як зі звичайною таблицею: SELECT * FROM ViewEmployeesInfo SELECT DepartmentName, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount, AVG(Salary) SalaryAvg FROM ViewEmployeesInfo emp GROUP BY DepartmentID,DepartmentName ORDER BY DepartmentName Тобто. Вам у цьому випадку, ніби нічого і не змінилося, ви продовжуєте так само працювати з однією таблицею (тільки вже правильніше сказати з поданням ViewEmployeesInfo), яке повертає всі необхідні вам дані. Завдяки допомозі ІТ-шників, деталі з добування DepartmentName і PositionName залишилися для вас у чорній скриньці. Тобто. уявлення вам виглядає так само, як і звичайна таблиця, вважайте, що це розширена версія таблиці Employees. Давайте для прикладу ще сформуємо відомість, щоб ви переконалися, що все дійсно так, як я і говорив (що вся вибірка йде з одного уявлення): SELECT ID, Name, Salary FROM ViewEmployeesInfo WHERE Salary IS NOT NULL AND Salary>0 ORDER BY Name Використання уявлень у деяких випадках дає можливість значно розширити межі користувачів, які мають написання базових SELECT-запитів. В даному випадку представлення, являє собою плоску таблицю з усіма необхідними користувачеві даними (для тих, хто розуміється на OLAP, це можна порівняти з наближеною подобою OLAP-куба з фактами та вимірами). Вирізка із вікіпедії.Хоча SQL і замислювався як роботи кінцевого користувача, зрештою він став настільки складним, що перетворився на інструмент програміста. Як бачите, шановні користувачі, мова SQL спочатку замислювався як інструмент для вас. Отже, все у ваших руках та бажанні, не відпускайте руки. HAVING – накладення умови вибірки до згрупованих данихВласне якщо ви зрозуміли, що таке угруповання, то з HAVING нічого складного немає. HAVING – чимось подібний до WHERE, тільки якщо WHERE-умова застосовується до детальних даних, то HAVING-умова застосовується до вже згрупованих даних. З цієї причини в умовах блоку HAVING ми можемо використовувати або вирази з полями, що входять до угруповання, або вирази, що містяться в агрегатних функціях.Розглянемо приклад: SELECT DepartmentID, SUM(Salary) SalaryAmount FROM Employees GROUP BY DepartmentID HAVING SUM(Salary)>3000
Тобто. даний запит повернув нам згруповані дані лише з тим відділам, які мають сума ЗП всіх співробітників перевищує 3000, тобто. "SUM (Salary)> 3000".
Тобто. тут у першу чергу відбувається угруповання та обчислюються дані по всіх відділах: SELECT DepartmentID, SUM(Salary) SalaryAmount FROM Employees GROUP BY DepartmentID -- 1. отримуємо згруповані дані по всіх відділах А вже до цих даних застосовується умова, зазначена в блоці HAVING: SELECT DepartmentID, SUM(Salary) SalaryAmount FROM Employees GROUP BY DepartmentID -- 1. отримуємо згруповані дані по всіх відділах HAVING SUM(Salary)>3000 -- 2. умова для фільтрації згрупованих даних У HAVING-умові так само можна будувати складні умови, використовуючи оператори AND, OR та NOT: SELECT DepartmentID, SUM(Salary) SalaryAmount FROM Employees GROUP BY DepartmentID HAVING SUM(Salary)>3000 AND COUNT(*)<2 -- и число людей меньше 2-х
Як можна помітити тут агрегатна функція (див. «COUNT(*)») може бути вказана тільки в блоці HAVING. Відповідно ми можемо відобразити лише номер відділу, що підпадає під HAVING-умову: SELECT DepartmentID FROM Employees GROUP BY DepartmentID HAVING SUM(Salary)>3000 AND COUNT(*)<2 -- и число людей меньше 2-х Приклад використання HAVING-умови поля включеного в GROUP BY: SELECT DepartmentID, SUM(Salary) SalaryAmount FROM Employees GROUP BY DepartmentID -- 1. зробити групування HAVING DepartmentID=3 -- 2. накласти фільтр на результат угруповання Це лише приклад, т.к. в даному випадку перевірку логічніше було б зробити через WHERE-умову: SELECT DepartmentID, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=3 - 1. провести фільтрацію детальних даних GROUP BY DepartmentID - 2. зробити угруповання тільки за відібраними записами Тобто. спочатку відфільтрувати співробітників з відділу 3, і потім зробити розрахунок. Примітка.Насправді, незважаючи на те, що ці два запити виглядають по-різному, оптимізатор СУБД може виконати їх однаково. Думаю, на цьому розповідь про HAVING-умови можна закінчити. Підведемо підсумкиЗведемо дані отримані у другій та третій частині та розглянемо конкретне місце розташування кожної вивченої нами конструкції та вкажемо порядок їх виконання:
Звичайно, ви також можете застосувати до згрупованих даних пропозиції DISTINCT і TOP, вивчені в другій частині. Ці пропозиції в цьому випадку застосовуються до остаточного результату: SELECT TOP 1 -- 6. застосовується в останню чергу SUM(Salary) SalaryAmount FROM Employees GROUP BY DepartmentID HAVING SUM(Salary)>3000 ORDER BY DepartmentID -- 5. сортування результату Як вийшли дані результати, проаналізуйте самостійно. ВисновокОсновна мета яку я ставив у цій частині – розкрити вам суть агрегатних функцій та угруповань.Якщо базова конструкція дозволяла нам отримати необхідні детальні дані, то застосування агрегатних функцій та угруповань до цих детальних даних дало нам можливість отримати по них зведені дані. Отже, як бачите тут усе важливе, т.к. одне спирається інше – без знання базової конструкції ми зможемо, наприклад, правильно відібрати дані, якими нам треба прорахувати результати. Тут я навмисно намагаюся показувати лише основи, щоб зосередити увагу початківців на найголовніших конструкціях та не перевантажувати їх зайвою інформацією. Тверде розуміння основних конструкцій (про які я ще продовжу розповідь у наступних частинах) дасть вам можливість вирішити практично будь-яке завдання щодо вибірки даних з РБД. Основні конструкції оператора SELECT застосовні в такому вигляді практично у всіх СУБД (відмінності в основному складаються в деталях, наприклад, в реалізації функцій - для роботи з рядками, часом, і т.д.). Надалі, тверде знання бази дасть вам можливість самостійно легко вивчити різні розширення мови SQL, такі як:
Якщо ви робите перші кроки в SQL, то зосередьтеся насамперед, саме з вивченні базових конструкцій, т.к. володіючи базою, все інше вам зрозуміти буде набагато легше, до того ж самостійно. Вам насамперед, хіба що потрібно об'ємно зрозуміти можливості мови SQL, тобто. які операції він взагалі дозволяє зробити над даними. Донести до початківців інформацію в об'ємному вигляді – це ще одна з причин, чому я показуватиму тільки найголовніші (залізні) конструкції. Успіхів вам у вивченні та розумінні мови SQL. Частина четверта - Команда CASE дозволяє вибрати для виконання однуз кількох послідовностей команд. Ця конструкція присутня в стандарті SQL з 1992 року, хоча Oracle SQL вона не підтримувалася аж до версії Oracle8i, а в PL/SQL - до версії Oracle9i Release 1. Починаючи з цієї версії, підтримуються наступні різновиди команд CASE:
NULL чи UNKNOWN?У статті, присвяченій оператору IF , ви могли дізнатися, що результат логічного виразу може дорівнювати TRUE , FALSE або NULL . У PL/SQL це твердження є істинним, але в більш широкому контексті реляційної теорії вважається некоректним говорити про повернення NULL з логічного виразу. Реляційна теорія каже, що порівняння з NULL такого виду: 2 < NULL дає логічний результат UNKNOWN, причому значення UNKNOWN не еквівалентно NULL. Втім, вам не варто переживати через те, що в PL/SQL для UNKNOWN використовується позначення NULL . Однак вам слід знати, що третім значенням тризначної логіки є UNKNOWN . І я сподіваюся, що ви ніколи не впадете в халепу (як це бувало зі мною!), використовуючи неправильний термін при обговоренні тризначної логіки з експертами в галузі реляційної теорії. Крім команд CASE, PL/SQL також підтримує CASE-вирази. Такий вираз дуже схожий на команду CASE, він дозволяє вибрати для обчислення один або кілька виразів. Результатом виразу CASE є значення, тоді як результатом команди CASE є виконання послідовності команд PL/SQL. Прості команди CASEПроста команда CASE дозволяє вибрати для виконання одну з кількох послідовностей команд PL/SQL, залежно від результату обчислення виразу. Він записується так: CASE вираз WHEN результат_1 THEN команди_1 WHEN результат_2 THEN команди_2 ... ELSE команди_else END CASE; Гілка ELSE тут не є обов'язковою. За виконання такої команди PL/SQL спочатку обчислює вираз, після чого результат порівнюється з результат_1 . Якщо вони збігаються, виконуються команди_1 . В іншому випадку перевіряється значення результат_2 і т.д. Наведемо приклад простої команди CASE , у якому премія нараховується залежно від значення змінної employee_type: CASE employee_type WHEN "S" THEN award_salary_bonus(employee_id); WHEN "H" THEN award_hourly_bonus (employee_id); WHEN "C" THEN award_commissioned_bonus(employee_id); ELSE RAISE invalid_employee_type; END CASE; У цьому прикладі є явно задана секція ELSE , проте в загальному випадку вона не обов'язкова. Без секції ELSE компілятор PL/SQL неявно підставляє такий код: ELSE RAISE CASE_NOT_FOUND; Інакше кажучи, якщо не задати ключове слово ELSE і якщо жодний результат у секціях WHEN не відповідає результату виразу в команді CASE , PL/SQL ініціює виняток CASE_NOT_FOUND . У цьому полягає відмінність цієї команди від IF . Коли у команді IF немає ключового слова ELSE , то при невиконанні умови не відбувається нічого, тоді як у команді CASE аналогічна ситуація призводить до помилки. Цікаво подивитися, як за допомогою простої команди CASE реалізувати описану на початку глави логіку нарахування премій. На перший погляд, це здається неможливим, але підійшовши до справи творчо, ми приходимо до наступного рішення: CASE TRUE WHEN salary >= 10000 AND salary<=20000 THEN give_bonus(employee_id, 1500); WHEN salary >20000 AND salary<= 40000 THEN give_bonus(employee_id, 1000); WHEN salary >40000 THEN give_bonus (employee_id, 500); ELSE give_bonus(employee_id, 0); END CASE; Тут важливо те, що елементи вираз і результат можуть бути скалярними значеннями, або виразами, результатами яких є скалярні значення. Повернувшись до команди IF...THEN...ELSIF , яка реалізує ту ж логіку, ви побачите, що в команді CASE визначено секцію ELSE , тоді як у команді IF–THEN–ELSIF ключове слово ELSE відсутнє. Причина додавання ELSE проста: якщо жодна з умов нарахування премії не виконується, команда IF нічого не робить і премія виходить нульовою. Команда CASE у разі видає помилку, тому ситуацію з нульовим розміром премії доводиться програмувати явно. Щоб запобігти помилкам CASE_NOT_FOUND , переконайтеся в тому, що при будь-якому значенні виразу буде виконано хоча б одну з умов. Наведена вище команда CASE TRUE комусь здасться ефектним трюком, але насправді вона лише реалізує пошукову команду CASE , про яку ми поговоримо в наступному розділі. Пошукова команда CASEПошукова команда CASE перевіряє список логічних виразів; виявивши вираз, що дорівнює TRUE , виконує послідовність пов'язаних з ним команд. По суті пошукова команда CASE є аналогом команди CASE TRUE , приклад якої наведено в попередньому розділі. Пошукова команда CASE має таку форму запису: CASE WHEN выражение_1 THEN команди_1 WHEN выражение_2 THEN команда_2 ... ELSE команди_else END CASE; Вона ідеально підходить для реалізації логіки нарахування премії: CASE WHEN salary >= 10000 AND salary<=20000 THEN give_bonus(employee_id, 1500); WHEN salary >20000 AND salary<= 40000 THEN give_bonus(employee_id, 1000); WHEN salary >40000 THEN give_bonus (employee_id, 500); ELSE give_bonus(employee_id, 0); END CASE; Пошукова команда CASE, як і проста команда, підпорядковується наступним правилам:
Розглянемо ще одну реалізацію логіки нарахування премії, в якій використовується та обставина, що умови WHEN перевіряються у порядку їх запису. Окремі вислови простіші, але чи можна сказати, що зміст усієї команди став більш зрозумілим? CASE WHEN salary > 40000 THEN give_bonus(employee_id, 500); WHEN salary > 20000 THEN give_bonus(employee_id, 1000); WHEN salary >= 10000 THEN give_bonus(employee_id, 1500); ELSE give_bonus(employee_id, 0); END CASE; Якщо оклад якогось співробітника дорівнює 20 000, то перші дві умови рівні FALSE, а третє - TRUE, тому співробітник отримає премію 1500 доларів. Якщо ж оклад дорівнює 21 000, то результат другої умови дорівнюватиме TRUE , і премія складе 1000 доларів. Виконання команди CASE завершиться на другій гілці WHEN, а третя умова навіть не перевірятиметься. Чи варто використовувати такий підхід при написанні команд CASE – питання спірне. Як би там не було, майте на увазі, що написати таку команду можливо, а при налагодженні та редагуванні програм, в яких результат залежить від порядку висловлювання, необхідна особлива уважність. Логіка, яка залежить від порядку проходження однорідних гілок WHEN, є потенційним джерелом помилок, що виникають при їх перестановці. Як приклад розглянемо наступну пошукову команду CASE , у якій при значенні salary , що дорівнює 20 000, перевірка умов обох гілках WHEN дає TRUE: CASE WHEN salary BETWEEN 10000 і 20000 THEN give_bonus (employee_id, 1500); WHEN salary BETWEEN 20000 І 40000 THEN give_bonus (employee_id, 1000); ... Уявіть, що програміст, який займається супроводом цієї програми, легковажно переставить гілки WHEN, щоб упорядкувати їх за спаданням salary. Не відкидайте таку можливість! Програмісти часто схильні «доводити до розуму» код, що працює, керуючись якимись внутрішніми уявленнями про порядок. Команда CASE з переставленими секціями WHEN має такий вигляд: CASE WHEN salary BETWEEN 20000 і 40000 THEN give_bonus (employee_id, 1000); WHEN salary BETWEEN 10000 і 20000 THEN give_bonus (employee_id, 1500); ... На перший погляд все правильно, чи не так? На жаль, через перекриття двох гілок WHEN у програмі з'являється підступна помилка. Тепер співробітник з окладом 20 000 отримає премію 1000 замість належних 1500. Можливо, в деяких ситуаціях перекриття між гілками WHEN бажано і все ж таки його слід по можливості уникати. Завжди пам'ятайте, що порядок проходження гілок важливий, і стримуйте бажання доопрацювати код, що вже працює, - «не чиніть те, що не зламано». Оскільки умови WHEN перевіряються по порядку, можна трохи підвищити ефективність коду, помістивши гілки з найімовірнішими умовами початку списку. Крім того, якщо у вас є гілка з «витратними» виразами (наприклад, що потребують значного процесорного часу та пам'яті), їх можна помістити в кінець, щоб звести до мінімуму можливість їх перевірки. За подробицями звертайтесь до розділу «Вкладені команди IF». Пошукові команди CASE використовуються у тих випадках, коли виконувані команди визначаються набором логічних виразів. Проста команда CASE використовується тоді, коли рішення приймається виходячи з результату одного висловлювання.
Вкладені команди CASEКоманди CASE , як і команди IF можуть бути вкладеними. Наприклад, вкладена команда CASE присутня у наступній (досить заплутаній) реалізації логіки нарахування премій: CASE WHEN salary >= 10000 THEN CASE WHEN salary<= 20000 THEN give_bonus(employee_id, 1500); WHEN salary >40000 THEN give_bonus (employee_id, 500); WHEN salary > 20000 THEN give_bonus(employee_id, 1000); END CASE; WHEN salary< 10000 THEN give_bonus(employee_id,0); END CASE; У CASE можуть використовуватися будь-які команди, так що внутрішня команда CASE легко замінюється командою IF . Аналогічним чином, у команду IF може бути вкладена будь-яка команда, у тому числі CASE . Вирази CASEВисловлювання CASE вирішують таку ж задачу, як і команди CASE , але не для виконуваних команд, а виразів. Просте вираз CASE вибирає для обчислення один з кількох виразів на підставі заданого скалярного значення. Пошукове вираз CASE послідовно обчислює вирази зі списку, поки один з них не виявиться рівним TRUE , а потім повертає результат пов'язаного з ним виразу. Синтаксис цих двох різновидів виразів CASE: Простий_вираз_Case:= CASE вираз WHEN результат_1 THEN результуючий_вираз_1 WHEN результат_2 THEN результуючий_вираз_2 ... ELSE результуючий_вираз_else END; Пошуковий_вираз_Case:= CASE WHEN_вираз_1 THEN результуючий_вираз_1 WHEN вираз_2 THEN результуючий_вираз_2 ... ELSE результуючий_вираз_else END; Вираз CASE повертає одне значення – результат вибраного для обчислення виразу. Кожній гілки WHEN має бути поставлене у відповідність один результуючий вираз (але не команда). Наприкінці виразу CASE не ставиться ні крапка з комою, ні END CASE . Вираз CASE завершується ключовим словом END. Далі наводиться приклад простого виразу CASE , що використовується спільно з процедурою PUT_LINE пакета DBMS_OUTPUT для виведення на екран значення логічної змінної. DECLARE boolean_true BOOLEAN: = TRUE; boolean_false BOOLEAN: = FALSE; boolean_null BOOLEAN; FUNCTION boolean_to_varchar2 (flag IN BOOLEAN) RETURN VARCHAR2 IS BEGIN RETURN CASE flag WHEN TRUE THEN "True" WHEN FALSE THEN "False" ELSE "NULL" END; END; BEGIN DBMS_OUTPUT.PUT_LINE(boolean_to_varchar2(boolean_true)); DBMS_OUTPUT.PUT_LINE(boolean_to_varchar2(boolean_false)); DBMS_OUTPUT.PUT_LINE(boolean_to_varchar2(boolean_null)); END; Для реалізації логіки нарахування премій можна використовувати пошуковий вираз CASE , що повертає величину премії заданого окладу: DECLARE salary NUMBER: = 20000; employee_id NUMBER:=36325; PROCEDURE give_bonus (emp_id IN NUMBER, bonus_amt IN NUMBER) IS BEGIN DBMS_OUTPUT.PUT_LINE(emp_id); DBMS_OUTPUT.PUT_LINE(bonus_amt); END; BEGIN give_bonus(employee_id, CASE WHEN salary >= 10000 AND salary<= 20000 THEN 1500 WHEN salary >20000 AND salary<= 40000 THEN 1000 WHEN salary >40000 (THEN 500 ELSE 0 END); END; Вираз CASE може застосовуватися скрізь, де допускається використання виразів іншого типу. У наступному прикладі CASE-вираз використовується для обчислення розміру премії, множення його на 10 і надання результату змінної, що виводиться на екран засобами DBMS_OUTPUT: DECLARE salary NUMBER: = 20000; employee_id NUMBER:=36325; bonus_amount NUMBER; BEGIN bonus_amount:= CASE WHEN salary >= 10000 AND salary<= 20000 THEN 1500 WHEN salary >20000 AND salary<= 40000 THEN 1000 WHEN salary >40000 THEN 500 ELSE 0 END * 10; DBMS_OUTPUT.PUT_LINE(bonus_amount); END; На відміну від команди CASE, якщо умова жодної гілки WHEN не виконано, вираз CASE не видає помилку, а просто повертає NULL. Популярне
Нове на сайті
|

























