Wyrażenia warunkowe CASE. Wyrażenia warunkowe CASE Wyrażenie CASE jest instrukcją warunkową języka SQL
CASE wyrażenie
Funkcja DEKODOWANIA
Stosowane są dwie metody:
Dwie metody używane do zaimplementowania przetwarzania warunkowego (logika IF-THEN-ELSE) w instrukcji SQL to wyrażenie CASE i funkcja DECODE.
Uwaga: Wyrażenie CASE jest zgodne z ANSI SQL. Funkcja DECODE jest specyficzna dla składni Oracle.
CASE wyrażenie
Upraszcza zapytania warunkowe, sprawiając, że instrukcja IF-THEN-ELSE działa:
Wyrażenia CASE umożliwiają użycie logiki IF-THEN-ELSE w instrukcjach SQL bez konieczności wywoływania procedur.
W prosty sposób wyrażenie warunkowe PRZYPADEK Serwer Oracle wyszukuje pierwszą parę WHEN ... THEN, dla której wyraż jest równe wyraż_porównania i zwraca wartość wyraż_powrotu. Jeśli żadna z par WHEN ... THEN nie spełnia tego warunku i jeśli istnieje klauzula else, Oracle zwraca else_expr. W przeciwnym razie Oracle zwraca wartość null. Nie można określić NULL dla wszystkich return_exprs i else_expr.
Wyr i wyr_porównania muszą być tego samego typu danych, którym może być CHAR, VARCHAR2, NCHAR lub NVARCHAR2. Wszystkie zwracane wartości (return_expr) muszą być tego samego typu danych.
W tej składni Oracle porównuje wyrażenie wejściowe (e) z każdym wyrażeniem porównawczym e1, e2, ..., en.
Jeśli wyrażenie wejściowe jest równe dowolnemu wyrażeniu porównania, wyrażenie CASE zwraca odpowiednie wyrażenie wynikowe (r).
Jeśli wyrażenie wejściowe e nie pasuje do żadnego wyrażenia porównania, wyrażenie CASE zwraca wyrażenie w klauzuli ELSE, jeśli klauzula ELSE istnieje, w przeciwnym razie zwraca wartość pustą.
Oracle używa oceny zwarcia dla prostego wyrażenia CASE. Oznacza to, że Oracle ocenia każde wyrażenie porównujące (e1, e2, ..en) tylko przed porównaniem jednego z nich z wyrażeniem wejściowym (e). Oracle nie ocenia wszystkich wyrażeń porównania przed porównaniem któregokolwiek z nich z wyrażeniem (e). W rezultacie Oracle nigdy nie ocenia wyrażenia porównania, jeśli poprzednie jest równe wyrażeniu wejściowemu (e).
Przykład prostego wyrażenia CASE
Do demonstracji użyjemy tabeli produktów.
Poniższe zapytanie używa wyrażenia CASE do obliczenia rabatu dla każdej kategorii produktów, tj. CPU 5%, karta graficzna 10% i inne kategorie produktów 8%
WYBIERZ ID kategorii CASE KIEDY 1 THEN ROUND (cena_listy * 0,05,2) - CPU KIEDY 2 THEN ROUND (Cena katalogowa * 0,1,2) — karta graficzna INNA RUNDA (cena_listy * 0,08,2) - pozostałe kategorie KONIEC zniżki Z ZAMÓW PRZEZ |
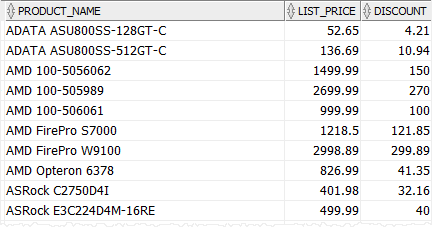
Zauważ, że użyliśmy funkcji ROUND(), aby zaokrąglić rabat do dwóch miejsc po przecinku.
Szukane wyrażenie CASE
Wyrażenie CASE przeszukiwane przez Oracle ocenia listę wyrażeń logicznych w celu określenia wyniku.
Przeszukiwana instrukcja CASE ma następującą składnię:
WALIZKA KIEDY e1TEŻ r1 , COUNT (DISTINCT DepartmentID) [Liczba unikalnych działów], COUNT (DISTINCT PositionID) [Liczba unikalnych pozycji], COUNT (BonusPercent) [Liczba pracowników z premią%], MAX (BonusPercent) [Maksymalny procent premii], MIN ( BonusPercent) [Minimalny procent premii], SUM (Salary / 100 * BonusPercent) [Suma wszystkich premii], AVG (Salary / 100 * BonusPercent) [Średnia premia], AVG (Salary) [Średnia pensja] OD Pracowników Przyjrzyjmy się, jak powstała każda wartość zwracana, i po pierwsze, przypomnijmy konstrukcje podstawowej składni instrukcji SELECT. Po pierwsze, ponieważ nie określiliśmy w zapytaniu warunków WHERE, to sumy zostaną obliczone dla szczegółowych danych, które uzyskuje się przez zapytanie: WYBIERZ * Z Pracownicy Te. dla wszystkich wierszy tabeli Pracownicy. Dla jasności wybierzemy tylko pola i wyrażenia używane w funkcjach agregujących: SELECT DepartmentID, PositionID, BonusPercent, Salary / 100 * BonusPercent, Salary FROM Employees
Są to dane początkowe (wiersze szczegółowe), według których zostaną obliczone sumy zagregowanego zapytania. Przyjrzyjmy się teraz każdej zagregowanej wartości:
Podsumujmy niektóre wyniki:
W związku z tym podczas określania dodatkowego warunku za pomocą funkcji agregujących w klauzuli WHERE zostaną obliczone tylko sumy dla wierszy, które spełniają warunek. Te. kalkulacja wartości agregatów wykonywana jest dla całego zestawu, który uzyskuje się za pomocą konstrukcji SELECT. Na przykład zróbmy to samo, ale tylko w kontekście działu IT: SELECT COUNT (*) [Łączna liczba pracowników], COUNT (DISTINCT DepartmentID) [Liczba unikalnych działów], COUNT (DISTINCT PositionID) [Liczba unikalnych pozycji], COUNT (BonusProcent) [Liczba pracowników z % premii] , MAX (BonusPercent) [Maksymalny procent bonusu], MIN (BonusPercent) [Minimalny procent bonusu], SUM (Salary / 100 * BonusPercent) [Suma wszystkich bonusów], AVG (Salary / 100 * BonusPercent) [Średnia wielkość bonusu], AVG ( Wynagrodzenie) [Średnia Wynagrodzenie] OD Pracowników GDZIE ID działu = 3 - Weź pod uwagę tylko dział IT SELECT DepartmentID, PositionID, BonusPercent, Salary / 100 * BonusPercent, Salary FROM Employees WHERE DepartmentID = 3 - uwzględnij tylko dział IT
Śmiało. Jeżeli funkcja agregująca zwraca NULL (na przykład wszyscy pracownicy nie mają określonej wartości Salary), lub w selekcji nie uwzględniono ani jednego rekordu, a w raporcie w takim przypadku musimy pokazać 0, to Funkcja ISNULL może zawinąć wyrażenie agregujące: SELECT SUM (Wynagrodzenie), AVG (Wynagrodzenie), - przetwórz sumę za pomocą ISNULL ISNULL (SUM (Wynagrodzenie), 0), ISNULL (AVG (Wynagrodzenie), 0) FROM Employees WHERE DepartmentID = 10 - specjalnie nieistniejący oddział wskazane tutaj, aby zapytanie nie zwracało rekordów
Uważam, że bardzo ważne jest zrozumienie celu każdej funkcji agregatu i sposobu jej obliczania, ponieważ w SQL jest to główne narzędzie do obliczania sum. W tym przypadku zbadaliśmy, jak każda funkcja agregująca zachowuje się niezależnie, tj. został zastosowany do wartości całego zestawu rekordów uzyskanych przez polecenie SELECT. Następnie przyjrzymy się, w jaki sposób te same funkcje są używane do obliczania sum grup przy użyciu klauzuli GROUP BY. GROUP BY - grupowanie danychWcześniej obliczyliśmy już sumy dla konkretnego działu, mniej więcej w następujący sposób:SELECT COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (Salary) SalaryAmount FROM Pracownicy WHERE ID działu = 3 - dane tylko dla działu IT Teraz wyobraź sobie, że poproszono nas o uzyskanie tych samych liczb w kontekście każdego działu. Oczywiście możemy zakasać rękawy i spełnić tę samą prośbę dla każdego działu. Tak więc, ledwie co powiedziałem, niż zrobiłem, piszemy 4 prośby: SELECT "Administracja" Info, COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (Salary) SalaryAmount FROM Pracownicy WHERE IDDziału = 1 - dane o Administracji SELECT "Księgowość" Info, COUNT (DISTINCT PositionID) PositionCount, COUNT ( * ) EmplCount, SUM (Salary) SalaryAmount FROM Employees WHERE DepartmentID = 2 - Dane księgowe SELECT "IT" Info, COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (Salary) SalaryAmount FROM Pracownicy WHERE ID działu = 3 - dane o Dział IT SELECT "Inne" Info, COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (Salary) SalaryAmount FROM Employees WHERE DepartmentID IS NULL - i nie zapomnij danych o freelancerach W rezultacie otrzymujemy 4 zbiory danych:
Należy pamiętać, że możemy używać pól określonych jako stałe - "Administracja", "Księgowość", ... Ogólnie wydobyliśmy wszystkie liczby, o które nas poproszono, wszystko łączymy w Excelu i przekazujemy dyrektorowi. Reżyserowi spodobał się raport i mówi: „i dodaj kolejną kolumnę z informacją o średniej pensji”. I jak zawsze trzeba to zrobić bardzo pilnie. Hmm, co robić?! Ponadto wyobraźmy sobie, że nasze działy to nie 3, ale 15. To jest dokładnie to, czym jest klauzula GROUP BY w takich przypadkach: SELECT DepartmentID, COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (Salary) SalaryAmount, AVG (Salary) SalaryAvg - plus spełniamy życzenia dyrektora FROM Employees GROUP BY DepartmentID
Otrzymaliśmy wszystkie te same dane, ale teraz używamy tylko jednego żądania! Na razie nie zwracajmy uwagi na to, że nasze działy są wyświetlane w postaci cyferek, wtedy nauczymy się jak pięknie wszystko wyeksponować. W klauzuli GROUP BY można określić kilka pól „GROUP BY pole1, pole2, ..., poleN”, w tym przypadku grupowanie nastąpi według grup, które tworzą wartości tych pól „pole1, pole2, .. ., poleN". Na przykład pogrupujmy dane według działów i stanowisk: WYBIERZ IDDziału, ID stanowiska, LICZBA (*) Liczba pracowników, SUMA (Wynagrodzenie) Kwota wynagrodzenia Z GRUPA PRACOWNIKÓW WEDŁUG IDDziału, ID stanowiska WYBIERZ LICZNIK (*) LiczbaPracowników, SUMA (Wynagrodzenie) KwotaWynagrodzenia FROM Pracownicy WHERE IDDziału TO NULL I ID Stanowiska TO NULL WYBIERZ LICZNIK (*) LiczbaZatrudni, SUMA (Wynagrodzenie) KwotaWynagrodzenia FROM Pracownicy WHERE IDDziału = 1 AND IDStanowiska = 2 - ... SELECT COUNT (*) LiczbaPracowników, SUMA (Wynagrodzenie) Kwota Wynagrodzenia OD Pracowników GDZIE IDDziału = 3 ORAZ ID Stanowiska = 4 A potem wszystkie te wyniki są łączone i przekazywane nam jako jeden zestaw:
Z głównego warto zauważyć, że w przypadku grupowania (GROUP BY), na liście kolumn w bloku SELECT:
I demonstracja wszystkiego, co zostało powiedziane: SELECT "Stała łańcuchowa" Stała1, - stała w postaci ciągu 1 Stała2, - stała w postaci liczby - wyrażenie wykorzystujące pola należące do grupy CONCAT ("Nr wydziału.", ID-Działu) ConstAndGroupField, CONCAT ("Dział No.", DepartmentID , ", Position No.", PositionID) ConstAndGroupFields, DepartmentID, - pole z listy pól uczestniczących w grupowaniu - PositionID, - pole biorące udział w grupowaniu, nie jest konieczne duplikowanie tutaj COUNT ( *) EmplCount, - liczba wierszy w każdej grupie - pozostałe pola mogą być używane tylko z funkcjami agregacyjnymi: LICZBA, SUMA, MIN, MAX, ... SUM (Wynagrodzenie) KwotaWynagrodzenia, MIN (ID) MinID Z GRUPY Pracowników BY DepartmentID, PositionID - grupowanie według pól DepartmentID, PositionID Warto również zauważyć, że grupowanie może odbywać się nie tylko według pól, ale także wyrażeń. Na przykład pogrupujmy dane według pracowników, według roku urodzenia: SELECT CONCAT ("Rok urodzenia -", ROK (Urodziny)) YearOfBirthday, COUNT (*) EmplCount FROM Employees GROUP WEDŁUG ROKU (Urodziny) Spójrzmy na przykład z bardziej złożonym wyrażeniem. Na przykład weźmy gradację pracowników według roku urodzenia: WYBIERZ PRZYPADEK WHEN ROK (Urodziny)> = 2000 THEN "od 2000" WHEN ROK (Urodziny)> = 1990 THEN "1999-1990" WHEN ROK (Urodziny)> = 1980 THEN "1989-1980" WHEN ROK (Urodziny)> = 1970 THEN "1979-1970" KIEDY URODZINY NIE JEST NULL THEN "przed 1970" ELSE "nie określono" END RangeName, COUNT (*) EmplCount FROM Pracowników GRUPUJ WEDŁUG PRZYPADKU WHEN ROK (Urodziny)> = 2000 THEN "od 2000" WHEN (Urodziny)> = 1990 TO "1999-1990" KIEDY ROK (Urodziny)> = 1980 TO "1989-1980" KIEDY ROK (Urodziny)> = 1970 TO "1979-1970" KIEDY URODZINY NIE JEST PUNKTOWE TO "przed 1970" ELSE "nie określono" END
Te. w tym przypadku grupowanie odbywa się według wyrażenia CASE wcześniej obliczonego dla każdego pracownika: SELECT ID, CASE WEN YEAR (Urodziny)> = 2000 THEN "od 2000" WHEN YEAR (Urodziny)> = 1990 THEN "1999-1990" WHEN YEAR (Urodziny)> = 1980 THEN "1989-1980" WHEN YEAR (Urodziny) > = 1970 THEN "1979-1970" KIEDY URODZINY NIE JEST NULL THEN "przed 1970" ELSE "nie określono" KONIEC OD Pracownicy
I oczywiście możesz łączyć wyrażenia z polami w bloku GROUP BY: SELECT IDID, CONCAT ("Rok urodzenia -", YEAR (Birthday)) YearOfBirthday, COUNT (*) EmplCount FROM Employees GROUP BY REAR (Birthday), DepartmentID - kolejność może nie pokrywać się z kolejnością ich użycia w SELECT ORDER Blok BY DepartmentID, YearOfBirthday - na koniec możemy zastosować sortowanie do wyniku Wróćmy do naszego pierwotnego zadania. Jak już wiemy, dyrektorowi ten raport bardzo się spodobał i poprosił nas o robienie tego co tydzień, aby móc monitorować zmiany w firmie. Aby za każdym razem w Excelu nie przerywać wartości liczbowej działu po jego nazwie, wykorzystamy wiedzę, którą już posiadamy i udoskonalimy nasze zapytanie: WYBIERZ PRZYPADEK ID działu WHEN 1 THEN "Administracja" WHEN 2 THEN "Księgowość" WHEN 3 THEN "IT" ELSE "Inne" KONIEC Info, COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (Salary) SalaryAmount, AVG (Salary ) SalaryAvg - plus spełniamy życzenia dyrektora OD PRACOWNIKÓW GRUPA WEDŁUG IDDZIAŁÓW ZAMÓW WG Info - dla większej wygody dodaj sortowanie po kolumnie Info Ale nic, z czasem nauczymy się robić wszystko pięknie, aby nasza próbka nie zależała od pojawiania się nowych danych w bazie, ale była dynamiczna. Pobiegnę trochę naprzód, aby pokazać, z jakimi prośbami staramy się wystąpić: SELECT ISNULL (nazwa oddziału, "Inne") Nazwa oddziału, COUNT (DISTINCT emp.PositionID) PositionCount, COUNT (*) EmplCount, SUM (prac.Salary) SalaryAmount, AVG (prac.Salary) SalaryAvg - plus spełnij życzenia dyrektor FROM Pracownicy emp LEWY DOŁĄCZ Działy dział ON mp.IDOddziału = IDOddziału GROUP BY prac.IDOddziału, NazwaOddziału ORDER BY NazwaOddziału Ogólnie rzecz biorąc, nie martw się – wszyscy zaczynali od prostych. Na razie wystarczy zrozumieć istotę klauzuli GROUP BY. Na koniec zobaczmy, jak można tworzyć raporty podsumowujące za pomocą funkcji GROUP BY. Na przykład wyświetlmy tabelę przestawną, w kontekście działów, aby obliczyć łączne wynagrodzenie otrzymywane przez pracowników według stanowiska: SELECT IDDziału, SUM (CASE WHEN IDPozycji = 1 THEN Wynagrodzenie END) [Księgowi], SUM (CASE WHEN IDPozycji = 2 THEN Wynagrodzenie END) [Dyrektorzy], SUMA (CASE WEN IDPozycji = 3 THEN Wynagrodzenie END) [Programiści], SUMA ( PRZYPADEK GDY ID stanowiska = 4 THEN Wynagrodzenie KONIEC) [Senior Programiści], SUMA (Wynagrodzenie) [Ogółem Działu] Z GRUPA PRACOWNIKÓW WEDŁUG ID działu Możesz oczywiście zostać przepisany za pomocą IIF: SELECT IDDziału, SUM (IIF (Identyfikator Stanowiska = 1, Wynagrodzenie, NULL)) [Księgowy], SUM (IIF (Identyfikator Stanowiska = 2, Wynagrodzenie, NULL)) [Dyrektorzy], SUM (IIF (Identyfikator Stanowiska = 3, Wynagrodzenie, NULL)) [Programiści], SUM (IIF (PositionID = 4, Wynagrodzenie, NULL)) [Senior Programiści], SUM (Wynagrodzenie) [Ogółem Działu] OD Pracowników GRUPA WEDŁUG ID działu Ale w przypadku IIF będziemy musieli jawnie określić NULL, który zostanie zwrócony, jeśli warunek nie zostanie spełniony. W podobnych przypadkach wolę używać CASE bez bloku ELSE niż ponownie pisać NULL. Ale to z pewnością kwestia gustu, o którą się nie dyskutuje. A pamiętajmy, że w funkcjach agregujących nie są brane pod uwagę wartości NULL. W celu konsolidacji dokonaj niezależnej analizy danych uzyskanych w ramach rozszerzonego żądania: SELECT IDDziału, CASE WEN IDPozycji = 1 THEN Wynagrodzenie END [Księgowy], CASE WEN IDPozycji = 2 THEN Wynagrodzenie END [Dyrektorzy], CASE WEN IDPozycji = 3 THEN Wynagrodzenie END [Programiści], CASE WEN IDPozycji = 4 THEN Wynagrodzenie END [Senior Programiści] ], Wynagrodzenie [Dział Razem] OD Pracownicy
Pamiętajmy też, że jeśli zamiast NULL chcemy widzieć zera, to możemy przetworzyć wartość zwracaną przez funkcję agregującą. Na przykład: SELECT ID działu, ISNULL (SUM (IIF (Identyfikator stanowiska = 1, Wynagrodzenie, NULL)), 0) [Księgowy], ISNULL (SUM (IIF (Identyfikator stanowiska = 2, Wynagrodzenie, NULL)), 0) [Dyrektorzy], ISNULL (SUM (IIF (PositionID = 3, Wynagrodzenie, NULL)), 0) [Programiści], ISNULL (SUM (IIF (PositionID = 4, Wynagrodzenie, NULL)), 0) [Starsi Programiści], ISNULL (SUM (Wynagrodzenie), 0 ) [Ogółem działu] Z GRUPA PRACOWNIKÓW WEDŁUG ID działu
GROUP BY w rzadkim z funkcjami agregacyjnymi, jednym z głównych narzędzi służących do pozyskiwania danych sumarycznych z bazy danych, ponieważ zwykle dane są używane w tej formie, ponieważ zwykle jesteśmy zobowiązani do dostarczania raportów podsumowujących, a nie szczegółowych danych (arkuszy). I oczywiście wszystko kręci się wokół znajomości podstawowego projektu, ponieważ zanim coś streścisz (zagregujesz), najpierw musisz to poprawnie zaznaczyć za pomocą "SELECT ... WHERE ...". Praktyka odgrywa tutaj ważną rolę, dlatego jeśli wyznaczysz sobie cel, aby zrozumieć język SQL, a nie uczyć się, ale rozumieć - ćwicz, ćwicz i ćwicz, przechodząc przez najróżniejsze opcje, jakie możesz wymyślić. Na początkowym etapie, jeśli nie masz pewności co do poprawności uzyskanych zagregowanych danych, wykonaj próbkę szczegółową, zawierającą wszystkie wartości, dla których agregacja się odbywa. I sprawdź poprawność obliczeń ręcznie, korzystając z tych szczegółowych danych. W takim przypadku użycie Excela może być bardzo pomocne. Powiedzmy, że dotarłeś do tego punktuZałóżmy, że jesteś księgowym S. S. Sidorovem, który postanowił nauczyć się pisać zapytania SELECT.Załóżmy, że skończyłeś już czytać ten samouczek do tego momentu i jesteś już pewny używania wszystkich powyższych podstawowych konstrukcji, tj. możesz:
Tak, ale nie wzięli pod uwagę, że nie można jeszcze budować zapytań z kilku tabel, a tylko z jednej, tj. nie wiesz jak zrobić coś takiego: WYBIERZ PRACĘ *, - zwróć wszystkie pola tabeli Pracownicy dział Nazwa NazwaDziału, - dodaj pole Nazwisko z tabeli Działy poz.Nazwa NazwaStanowiska do tych pól - a także dodaj pole Nazwisko z tabeli Stanowiska FROM Pracodawca LEWY DOŁĄCZ Działy dep ON emp.DepartmentID = dep.ID LEFT JOIN Pozycje poz ON emp.PositionID = poz.ID Jak więc wykorzystać swoją obecną wiedzę i uzyskać jeszcze bardziej produktywne wyniki?! Wykorzystamy moc kolektywnego umysłu – idziemy do programistów, którzy dla Ciebie pracują, tj. do Andreeva A.A., Petrova P.P. lub Nikolayev N.N. i poproś jednego z nich o napisanie dla Ciebie widoku (WIDOK lub po prostu „Widok”, dzięki czemu nawet szybciej Cię zrozumieją), który oprócz głównych pól z tabeli Pracownicy zwróci również pola z „Nazwa wydziału” i „Nazwa stanowiska”, których tak bardzo brakuje ci w tygodniowym raporcie, który przesłał ci Iwanow II. Dlatego wszystko dobrze wyjaśniłeś, to informatycy od razu zrozumieli, czego od nich chcą i stworzyli specjalnie dla Ciebie widok o nazwie ViewEmployeesInfo. Oświadczamy, że nie widzisz następnego polecenia, ponieważ Specjaliści IT to robią: CREATE VIEW ViewEmployeesInfo AS SELECT Emp.prac.*, - zwróć wszystkie pola tabeli Employees dep.Name DepartmentName, - dodaj do tych pól pole Name z tabeli Departments Pos.Name PositionName - a także dodaj pole Name z tabeli Positions FROM Pracownicy emp LEFT JOIN Działy dz.pracy.Działu = ID oddziału LEFT JOIN Pozycje poz ON emp.PositionID = poz.ID Te. dla Ciebie to wszystko, choć przerażające i niezrozumiałe, tekst pozostaje poza ekranem, a informatycy podają Ci tylko nazwę widoku „ViewEmployeesInfo”, który zwraca wszystkie powyższe dane (czyli to, o co ich prosiłeś). Możesz teraz pracować z tym widokiem jak ze zwykłą tabelą: WYBIERZ * Z ZobaczInformacje o pracownikach SELECT NazwaWydziału, COUNT (DISTINCT ID stanowiska) Liczba stanowisk, LICZBA (*) Liczba pracowników, SUMA (Wynagrodzenie) Kwota wynagrodzenia, ŚREDNIE (Wynagrodzenie) Śr.wynagrodzenie FROM ViewEmployeesInfo emp GROUP BY IDDziału, Nazwa działu ORDER BY NazwaWydziału Te. dla ciebie w tym przypadku, jakby nic się nie zmieniło, kontynuujesz pracę z jedną tabelą (ale bardziej poprawne byłoby z widokiem ViewEmployeesInfo), która zwraca wszystkie potrzebne dane. Dzięki pomocy informatyków szczegóły wydobycia DepartmentName i PositionName pozostają dla Ciebie w czarnej skrzynce. Te. widok wygląda tak samo jak zwykła tabela, uważaj to za rozszerzoną wersję tabeli Pracownicy. Na przykład stwórzmy oświadczenie, aby upewnić się, że wszystko jest naprawdę tak, jak powiedziałem (że cała próbka pochodzi z jednego widoku): WYBIERZ ID, Imię, Wynagrodzenie FROM ViewEmployeesInfo GDZIE Wynagrodzenie NIE JEST NULL I Wynagrodzenie> 0 ORDER BY Nazwa Wykorzystanie widoków w niektórych przypadkach pozwala znacznie poszerzyć granice użytkowników, którzy potrafią pisać podstawowe zapytania SELECT. W tym przypadku widok jest płaską tabelą ze wszystkimi danymi, których potrzebuje użytkownik (dla tych, którzy rozumieją OLAP, można to porównać do przybliżenia kostki OLAP z faktami i wymiarami). Wycinek z Wikipedii. Chociaż SQL został pomyślany jako narzędzie dla użytkownika końcowego, w końcu stał się tak złożony, że stał się narzędziem programisty. Jak widzicie, drodzy użytkownicy, język SQL został pierwotnie pomyślany jako narzędzie dla Was. Więc wszystko jest w twoich rękach i pragnieniu, nie odpuszczaj. POSIADAJĄCY - nałożenie warunku selekcji na zgrupowane daneWłaściwie, jeśli rozumiesz, czym jest grupowanie, to nie ma nic skomplikowanego w MIEĆ. HAVING jest nieco podobny do WHERE, tylko jeśli warunek WHERE jest stosowany do danych szczegółowych, to warunek HAVING jest stosowany do już zgrupowanych danych. Z tego powodu w warunkach bloku HAVING możemy użyć albo wyrażeń z polami zawartymi w grupowaniu, albo wyrażeń zawartych w funkcjach agregujących.Rozważmy przykład: WYBIERZ IDDziału, SUMA (Wynagrodzenie) Wynagrodzenie Kwota Z Pracowników GRUPA WEDŁUG IDDziału POSIADAJĄC SUMA (Wynagrodzenie)> 3000
Te. Ta prośba zwróciła nam zgrupowane dane tylko dla tych działów, dla których łączne wynagrodzenie wszystkich pracowników przekracza 3000, tj. "SUMA (Wynagrodzenie)> 3000".
Te. tutaj przede wszystkim odbywa się grupowanie i obliczane są dane dla wszystkich działów: SELECT ID Działu, SUMA (Wynagrodzenie) Kwota Wynagrodzenia Z Pracowników GRUPA WEDŁUG ID Działu - 1. uzyskaj pogrupowane dane dla wszystkich działów I już warunek określony w bloku HAVING jest stosowany do tych danych: SELECT ID działu, SUMA (Wynagrodzenie) Kwota wynagrodzenia FROM Pracownicy GRUPA WEDŁUG ID działu - 1. uzyskaj zgrupowane dane dla wszystkich działów POSIADAJĄC SUMA (Wynagrodzenie)> 3000 - 2.warunek filtrowania zgrupowanych danych W warunku HAVING możesz również budować złożone warunki za pomocą operatorów AND, OR i NOT: WYBIERZ ID działu, SUMA (Wynagrodzenie) Kwota wynagrodzenia Z GRUPA PRACOWNIKÓW WEDŁUG ID działu POSIADAJĄC SUMA (Wynagrodzenie)> 3000 I LICZBA (*)<2 -- и число людей меньше 2-х
Jak widać tutaj funkcja agregująca (patrz "LICZBA (*)") może być określona tylko w bloku HAVING. W związku z tym możemy wyświetlić tylko numer działu, który spełnia warunek HAVING: WYBIERZ ID działu Z GRUPY PRACOWNIKÓW WEDŁUG ID działu POSIADAJĄC SUMA (Wynagrodzenie)> 3000 I LICZBA (*)<2 -- и число людей меньше 2-х Przykład użycia warunku HAVING na polu zawartym w grupie GROUP BY: SELECT IDDziału, SUMA (Wynagrodzenie) Kwota Wynagrodzenia FROM Pracownicy GRUPA WEDŁUG IDDziału - 1. utwórz grupowanie POSIADAJĄC IDDziału = 3 - 2. przefiltruj wynik grupowania To tylko przykład, ponieważ w takim przypadku bardziej logiczne byłoby sprawdzenie warunku WHERE: SELECT IDDziału, SUMA (Wynagrodzenie) Kwota Wynagrodzenia FROM Pracownicy WHERE IDDziału = 3 - 1. filtruj szczegółowe dane GROUP BY IDDziału - 2. dokonaj grupowania tylko według wybranych rekordów Te. najpierw przefiltruj pracowników według działu 3, a dopiero potem dokonaj obliczeń. Uwaga. W rzeczywistości, nawet jeśli te dwa zapytania wyglądają inaczej, optymalizator DBMS może je wykonać w ten sam sposób. Myślę, że na tym kończy się opowieść o warunkach POSIADAJĄCYCH. PodsumujmyPodsumujmy dane uzyskane w drugiej i trzeciej części i rozważmy konkretną lokalizację każdej badanej konstrukcji i wskażmy kolejność ich realizacji:
Oczywiście możesz również zastosować klauzule DISTINCT i TOP, których nauczyłeś się w części drugiej, do zgrupowanych danych. Poniższe sugestie w tym przypadku dotyczą wyniku końcowego: WYBIERZ TOP 1 - 6. zastosuje ostatnią SUMA (Wynagrodzenie) WynagrodzenieKwota Z Pracowników GRUPA WEDŁUG IDDziału POSIADAJĄC SUMA (Wynagrodzenie)> 3000 ZAMÓWIENIE WG IDDziału - 5.sortuj wynik Przeanalizuj sam, w jaki sposób uzyskano te wyniki. WniosekGłównym celem, który postawiłem w tej części, jest odkrycie dla Ciebie istoty funkcji agregujących i grupowań.Jeśli podstawowy projekt pozwolił nam uzyskać niezbędne dane szczegółowe, to zastosowanie funkcji agregujących i grupowań do tych szczegółowych danych dało nam możliwość uzyskania na ich temat danych zbiorczych. Tak więc, jak widać, wszystko jest tutaj ważne, tk. jedno oparte jest na drugim – bez znajomości podstawowej struktury nie będziemy w stanie np. poprawnie dobrać danych, dla których musimy obliczyć sumy. Tutaj celowo staram się pokazać tylko podstawy, aby skupić uwagę początkującego na najważniejszych strukturach i nie przeciążać ich niepotrzebnymi informacjami. Dobre zrozumienie podstawowych struktur (o których będę mówił w kolejnych częściach) da Ci możliwość rozwiązania niemal każdego problemu pobierania danych z RDB. Podstawowe konstrukcje instrukcji SELECT mają zastosowanie w tej samej formie w prawie wszystkich SZBD (różnice tkwią głównie w szczegółach, na przykład w implementacji funkcji - do pracy z ciągami, czasem itp.). Z kolei solidna znajomość bazy da Ci możliwość łatwego samodzielnego poznania różnych rozszerzeń języka SQL, takich jak:
Jeśli stawiasz pierwsze kroki w SQL, najpierw skup się na nauce podstawowych konstrukcji. posiadając bazę, wszystko inne będzie ci znacznie łatwiej zrozumieć, a poza tym na własną rękę. Przede wszystkim musisz dogłębnie zrozumieć możliwości języka SQL, tj. jaki rodzaj operacji generalnie umożliwia wykonanie na danych. Przekazywanie informacji początkującym w obszernej formie to kolejny z powodów, dla których pokażę tylko najważniejsze (żelazne) konstrukcje. Powodzenia w nauce i zrozumieniu języka SQL. Część czwarta -
O czym będzie mowa w tej częściW tej części poznamy:
Wyrażenie CASE - instrukcja warunkowa SQLTen operator umożliwia sprawdzenie warunków i zwrócenie jednego lub drugiego wyniku, w zależności od spełnienia określonego warunku.Oświadczenie CASE ma 2 formy: Weźmy przykład pierwszego formularza CASE: SELECT ID, Imię, Wynagrodzenie, CASE WHEN Wynagrodzenie>=3000 THEN "RFP>=3000" WHEN Wynagrodzenie>=2000 THEN "2000<= ЗП < 3000"
ELSE "ЗП < 2000"
END SalaryTypeWithELSE,
CASE
WHEN Salary>= 3000 TO "wynagrodzenie>=3000" KIEDY wynagrodzenie>=2000 TO "2000<= ЗП < 3000"
END SalaryTypeWithoutELSE
FROM Employees
Jeśli żaden z warunków WHEN nie jest spełniony, zwracana jest wartość określona po słowie ELSE (co w tym przypadku oznacza "ELSE RETURN..."). Jeśli nie określono bloku ELSE i nie są spełnione żadne warunki WHEN, zwracana jest wartość NULL. Zarówno w pierwszej, jak i drugiej formie blok ELSE znajduje się na samym końcu struktury CASE, tj. po wszystkich warunkach KIEDY. Weźmy przykład drugiego formularza CASE: Załóżmy, że na nowy rok postanowili nagrodzić wszystkich pracowników i poprosili o obliczenie wysokości premii zgodnie z następującym schematem:
Do tego zadania używamy zapytania z wyrażeniem CASE: SELECT ID, Name, Salary, DepartmentID, - dla jasności wyświetlamy procent jako linię CASE DepartmentID - zaznaczona wartość WHEN 2 THEN "10%" - 10% pensji do wydania Księgowym WHEN 3 THEN "15%" - 15% od pensji do przekazania pracownikom IT JESZCZE "5%" - wszystkim innym 5% KONIEC NowyRokBonusProcent, - zbudujmy wyrażenie używając CASE aby zobaczyć wysokość premii Wynagrodzenie / 100 * CASE DepartmentID WHEN 2 THEN 10 - 10% wynagrodzenia do wydania Dla księgowych KIEDY 3 TO 15 - 15% wynagrodzenia do wydania Pracownicy IT JESZCZE 5 - wszyscy pozostali po 5% KONIEC Kwota Premia OD Pracowników W związku z tym zwracana jest wartość bloku ELSE, jeśli DepartmentID nie pasuje do żadnej wartości WHEN. Jeśli nie ma bloku ELSE, zostanie zwrócone NULL, jeśli DepartmentID nie pasuje do żadnej wartości WHEN. Drugi formularz CASE jest łatwy do przedstawienia za pomocą pierwszego formularza: SELECT ID, Name, Salary, DepartmentID, CASE WEN DepartmentID = 2 THEN "10%" - 10% pensji wydawanej dla Księgowych WHEN DepartmentID = 3 THEN "15%" - 15% pensji wydawanej do IT pracownicy INNY "5%" - wszyscy inni 5% KONIEC NowyRokBonusProcent, - zbuduj wyrażenie używając CASE, aby zobaczyć kwotę premii Wynagrodzenie / 100 * CASE WEN DepartmentID = 2 THEN 10 - 10% wynagrodzenia do wydania Księgowym WHEN DepartmentID = 3 NASTĘPNIE 15 - 15% wynagrodzenia dla pracowników IT JESZCZE 5 - wszyscy inni po 5% KONIEC Kwota Premia OD Pracowników Tak więc druga forma jest po prostu uproszczoną notacją dla tych przypadków, w których musimy wykonać porównanie równości tej samej wartości testowej z każdą wartością / wyrażeniem WHEN. Uwaga. Pierwsza i druga forma CASE są zawarte w standardzie języka SQL, więc najprawdopodobniej powinny mieć zastosowanie w wielu DBMS. W wersji MS SQL 2012 pojawił się uproszczony formularz notacji IIF. Może służyć do uproszczenia instrukcji CASE, gdy zwracane są tylko 2 wartości. Projekt IIF wygląda następująco: IIF (warunek, prawdziwa_wartość, fałszywa_wartość) Te. w rzeczywistości jest to opakowanie dla następującej konstrukcji CASE: CASE WHEN warunek THEN prawda_wartość ELSE fałsz_wartość END Zobaczmy przykład: SELECT ID, Imię, Wynagrodzenie, IIF (Wynagrodzenie> = 2500, "Wynagrodzenie> = 2500", "Wynagrodzenie< 2500") DemoIIF, CASE WHEN Salary>= 2500 TO "RFP> = 2500" ELSE "RFP< 2500" END DemoCASE FROM Employees Konstrukcje CASE, IIF mogą być zagnieżdżone w sobie. Rozważmy abstrakcyjny przykład: SELECT ID, Name, Salary, CASE WHEN DepartmentID IN (1,2) THEN "A" WHEN DepartmentID = 3 THEN CASE PositionID - zagnieżdżony CASE WHEN 3 THEN "B-1" WHEN 4 THEN "B-2" END ELSE " C "KONIEC Demo1, IIF (IDWydziału IN (1,2)," A ", IIF (IDWydziału = 3, PRZYPADEK PozycjaID WHEN 3 THEN" B-1 "WHEN 4 THEN" B-2 "KONIEC," C ")) Demo2 OD pracowników Ponieważ konstrukcje CASE i IIF są wyrażeniami zwracającymi wynik, możemy ich używać nie tylko w bloku SELECT, ale także w innych blokach, które pozwalają na użycie wyrażeń, na przykład w klauzulach WHERE lub ORDER BY. Na przykład otrzymamy zadanie stworzenia listy rozdania pensji w następujący sposób:
Spróbujmy rozwiązać ten problem, dodając wyrażenie CASE do bloku ORDER BY: WYBIERZ ID, Nazwisko, Wynagrodzenie FROM Pracownicy ORDER BY CASE KIEDY Wynagrodzenie> = 2500 TO 1 ELSE 0 KONIEC, - najpierw wystaw pensję tym, którzy mają ją poniżej 2500 Nazwisko - dalej sortuj listę według imienia i nazwiska I abstrakcyjny przykład użycia CASE w klauzuli WHERE: SELECT ID, Imię, Wynagrodzenie FROM Pracownicy WHERE CASE WHEN Wynagrodzenie> = 2500 THEN 1 ELSE 0 END = 1 - wszystkie rekordy, których wyrażenie wynosi 1 Możesz spróbować samodzielnie powtórzyć 2 ostatnie przykłady za pomocą funkcji IIF. I na koniec jeszcze raz pamiętajmy o wartościach NULL: SELECT ID, Name, Salary, DepartmentID, CASE WEN DepartmentID = 2 THEN "10%" - 10% wynagrodzenia do wydania Księgowym WHEN DepartmentID = 3 THEN "15%" - do wydania 15% pensji pracownikom IT WHEN DepartmentID IS NULL THEN "-" - freelancerom nie dajemy bonusów (używamy IS NULL) ELSE "5%" - wszyscy inni mają po 5% END NewYearBonusPercent1, - ale nie możesz sprawdzić NULL, pamiętaj, co zostało powiedziane o NULL w drugiej części CASE DepartmentID - - wartość sprawdzona KIEDY 2 TO "10%" KIEDY 3 TO "15%" KIEDY NULL TO "-" - !!! w tym przypadku użycie drugiego formularza CASE nie jest odpowiednie ELSE "5%" KONIEC NowyRokBonusProcent2 OD Pracowników SELECT ID, Name, Salary, DepartmentID, CASE ISNULL (DepartmentID, -1) - użyj zamiennika w przypadku NULL przez -1 WHEN 2 THEN "10%" WHEN 3 THEN "15%" WHEN -1 THEN "-" - jeśli mamy pewność, że nie ma działu o ID równym (-1) i nie będzie INNE "5%" KONIEC NowyRokBonusProcent3 OD Pracowników Ogólnie lot wyobraźni w tym przypadku nie jest ograniczony. Na przykład zobaczmy, jak można modelować funkcję ISNULL za pomocą CASE i IIF: SELECT ID, Imię, Nazwisko, ISNULL (Nazwisko, "Nieokreślone") DemoISNULL, CASE WEN Nazwisko JEST NULL THEN "Nieokreślone" ELSE Nazwisko END DemoCASE, IIF (Nazwisko JEST NULL, "Nieokreślone", Nazwisko) DemoIIF FROM Pracownicy Konstrukcja CASE to bardzo potężna funkcja SQL, która pozwala narzucić dodatkową logikę obliczania wartości zbioru wyników. W tej części posiadanie konstrukcji CASE będzie nam nadal przydatne, dlatego w tej części przede wszystkim zwracamy na to uwagę. Funkcje agregująceTutaj omówimy tylko podstawowe i najczęściej używane funkcje agregujące:
Funkcje agregujące pozwalają nam obliczyć całkowitą wartość dla zbioru wierszy uzyskanych za pomocą instrukcji SELECT. Spójrzmy na każdą funkcję na przykładzie: SELECT COUNT (*) [Łączna liczba pracowników], COUNT (DISTINCT DepartmentID) [Liczba unikalnych działów], COUNT (DISTINCT PositionID) [Liczba unikalnych pozycji], COUNT (BonusProcent) [Liczba pracowników z % premii] , MAX (BonusPercent) [Maksymalny procent bonusu], MIN (BonusPercent) [Minimalny procent bonusu], SUM (Salary / 100 * BonusPercent) [Suma wszystkich bonusów], AVG (Salary / 100 * BonusPercent) [Średnia wielkość bonusu], AVG ( Wynagrodzenie) [Średnia pensja] OD Pracowników Przyjrzyjmy się, jak powstała każda wartość zwracana, i po pierwsze, przypomnijmy konstrukcje podstawowej składni instrukcji SELECT. Po pierwsze, ponieważ nie określiliśmy w zapytaniu warunków WHERE, to sumy zostaną obliczone dla szczegółowych danych, które uzyskuje się przez zapytanie: WYBIERZ * Z Pracownicy Te. dla wszystkich wierszy tabeli Pracownicy. Dla jasności wybierzemy tylko pola i wyrażenia używane w funkcjach agregujących: SELECT DepartmentID, PositionID, BonusPercent, Salary / 100 * BonusPercent, Salary FROM Employees
Są to dane początkowe (wiersze szczegółowe), według których zostaną obliczone sumy zagregowanego zapytania. Przyjrzyjmy się teraz każdej zagregowanej wartości:
Podsumujmy niektóre wyniki:
W związku z tym podczas określania dodatkowego warunku za pomocą funkcji agregujących w klauzuli WHERE zostaną obliczone tylko sumy dla wierszy, które spełniają warunek. Te. kalkulacja wartości agregatów wykonywana jest dla całego zestawu, który uzyskuje się za pomocą konstrukcji SELECT. Na przykład zróbmy to samo, ale tylko w kontekście działu IT: SELECT COUNT (*) [Łączna liczba pracowników], COUNT (DISTINCT DepartmentID) [Liczba unikalnych działów], COUNT (DISTINCT PositionID) [Liczba unikalnych pozycji], COUNT (BonusProcent) [Liczba pracowników z % premii] , MAX (BonusPercent) [Maksymalny procent bonusu], MIN (BonusPercent) [Minimalny procent bonusu], SUM (Salary / 100 * BonusPercent) [Suma wszystkich bonusów], AVG (Salary / 100 * BonusPercent) [Średnia wielkość bonusu], AVG ( Wynagrodzenie) [Średnia Wynagrodzenie] OD Pracowników GDZIE ID działu = 3 - Weź pod uwagę tylko dział IT SELECT DepartmentID, PositionID, BonusPercent, Salary / 100 * BonusPercent, Salary FROM Employees WHERE DepartmentID = 3 - uwzględnij tylko dział IT
Śmiało. Jeżeli funkcja agregująca zwraca NULL (na przykład wszyscy pracownicy nie mają określonej wartości Salary), lub w selekcji nie uwzględniono ani jednego rekordu, a w raporcie w takim przypadku musimy pokazać 0, to Funkcja ISNULL może zawinąć wyrażenie agregujące: SELECT SUM (Wynagrodzenie), AVG (Wynagrodzenie), - przetwórz sumę za pomocą ISNULL ISNULL (SUM (Wynagrodzenie), 0), ISNULL (AVG (Wynagrodzenie), 0) FROM Employees WHERE DepartmentID = 10 - specjalnie nieistniejący oddział wskazane tutaj, aby zapytanie nie zwracało rekordów
Uważam, że bardzo ważne jest zrozumienie celu każdej funkcji agregatu i sposobu jej obliczania, ponieważ w SQL jest to główne narzędzie do obliczania sum. W tym przypadku zbadaliśmy, jak każda funkcja agregująca zachowuje się niezależnie, tj. został zastosowany do wartości całego zestawu rekordów uzyskanych przez polecenie SELECT. Następnie przyjrzymy się, w jaki sposób te same funkcje są używane do obliczania sum grup przy użyciu klauzuli GROUP BY. GROUP BY - grupowanie danychWcześniej obliczyliśmy już sumy dla konkretnego działu, mniej więcej w następujący sposób:SELECT COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (Salary) SalaryAmount FROM Pracownicy WHERE ID działu = 3 - dane tylko dla działu IT Teraz wyobraź sobie, że poproszono nas o uzyskanie tych samych liczb w kontekście każdego działu. Oczywiście możemy zakasać rękawy i spełnić tę samą prośbę dla każdego działu. Tak więc, ledwie co powiedziałem, niż zrobiłem, piszemy 4 prośby: SELECT "Administracja" Info, COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (Salary) SalaryAmount FROM Pracownicy WHERE IDDziału = 1 - dane o Administracji SELECT "Księgowość" Info, COUNT (DISTINCT PositionID) PositionCount, COUNT ( * ) EmplCount, SUM (Salary) SalaryAmount FROM Employees WHERE DepartmentID = 2 - Dane księgowe SELECT "IT" Info, COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (Salary) SalaryAmount FROM Pracownicy WHERE ID działu = 3 - dane o Dział IT SELECT "Inne" Info, COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (Salary) SalaryAmount FROM Employees WHERE DepartmentID IS NULL - i nie zapomnij danych o freelancerach W rezultacie otrzymujemy 4 zbiory danych:
Należy pamiętać, że możemy używać pól określonych jako stałe - "Administracja", "Księgowość", ... Ogólnie wydobyliśmy wszystkie liczby, o które nas poproszono, wszystko łączymy w Excelu i przekazujemy dyrektorowi. Reżyserowi spodobał się raport i mówi: „i dodaj kolejną kolumnę z informacją o średniej pensji”. I jak zawsze trzeba to zrobić bardzo pilnie. Hmm, co robić?! Ponadto wyobraźmy sobie, że nasze działy to nie 3, ale 15. To jest dokładnie to, czym jest klauzula GROUP BY w takich przypadkach: SELECT DepartmentID, COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (Salary) SalaryAmount, AVG (Salary) SalaryAvg - plus spełniamy życzenia dyrektora FROM Employees GROUP BY DepartmentID
Otrzymaliśmy wszystkie te same dane, ale teraz używamy tylko jednego żądania! Na razie nie zwracajmy uwagi na to, że nasze działy są wyświetlane w postaci cyferek, wtedy nauczymy się jak pięknie wszystko wyeksponować. W klauzuli GROUP BY można określić kilka pól „GROUP BY pole1, pole2, ..., poleN”, w tym przypadku grupowanie nastąpi według grup, które tworzą wartości tych pól „pole1, pole2, .. ., poleN". Na przykład pogrupujmy dane według działów i stanowisk: WYBIERZ IDDziału, ID stanowiska, LICZBA (*) Liczba pracowników, SUMA (Wynagrodzenie) Kwota wynagrodzenia Z GRUPA PRACOWNIKÓW WEDŁUG IDDziału, ID stanowiska WYBIERZ LICZNIK (*) LiczbaPracowników, SUMA (Wynagrodzenie) KwotaWynagrodzenia FROM Pracownicy WHERE IDDziału TO NULL I ID Stanowiska TO NULL WYBIERZ LICZNIK (*) LiczbaZatrudni, SUMA (Wynagrodzenie) KwotaWynagrodzenia FROM Pracownicy WHERE IDDziału = 1 AND IDStanowiska = 2 - ... SELECT COUNT (*) LiczbaPracowników, SUMA (Wynagrodzenie) Kwota Wynagrodzenia OD Pracowników GDZIE IDDziału = 3 ORAZ ID Stanowiska = 4 A potem wszystkie te wyniki są łączone i przekazywane nam jako jeden zestaw:
Z głównego warto zauważyć, że w przypadku grupowania (GROUP BY), na liście kolumn w bloku SELECT:
I demonstracja wszystkiego, co zostało powiedziane: SELECT "Stała łańcuchowa" Stała1, - stała w postaci ciągu 1 Stała2, - stała w postaci liczby - wyrażenie wykorzystujące pola należące do grupy CONCAT ("Nr wydziału.", ID-Działu) ConstAndGroupField, CONCAT ("Dział No.", DepartmentID , ", Position No.", PositionID) ConstAndGroupFields, DepartmentID, - pole z listy pól uczestniczących w grupowaniu - PositionID, - pole biorące udział w grupowaniu, nie jest konieczne duplikowanie tutaj COUNT ( *) EmplCount, - liczba wierszy w każdej grupie - pozostałe pola mogą być używane tylko z funkcjami agregacyjnymi: LICZBA, SUMA, MIN, MAX, ... SUM (Wynagrodzenie) KwotaWynagrodzenia, MIN (ID) MinID Z GRUPY Pracowników BY DepartmentID, PositionID - grupowanie według pól DepartmentID, PositionID Warto również zauważyć, że grupowanie może odbywać się nie tylko według pól, ale także wyrażeń. Na przykład pogrupujmy dane według pracowników, według roku urodzenia: SELECT CONCAT ("Rok urodzenia -", ROK (Urodziny)) YearOfBirthday, COUNT (*) EmplCount FROM Employees GROUP WEDŁUG ROKU (Urodziny) Spójrzmy na przykład z bardziej złożonym wyrażeniem. Na przykład weźmy gradację pracowników według roku urodzenia: WYBIERZ PRZYPADEK WHEN ROK (Urodziny)> = 2000 THEN "od 2000" WHEN ROK (Urodziny)> = 1990 THEN "1999-1990" WHEN ROK (Urodziny)> = 1980 THEN "1989-1980" WHEN ROK (Urodziny)> = 1970 THEN "1979-1970" KIEDY URODZINY NIE JEST NULL THEN "przed 1970" ELSE "nie określono" END RangeName, COUNT (*) EmplCount FROM Pracowników GRUPUJ WEDŁUG PRZYPADKU WHEN ROK (Urodziny)> = 2000 THEN "od 2000" WHEN (Urodziny)> = 1990 TO "1999-1990" KIEDY ROK (Urodziny)> = 1980 TO "1989-1980" KIEDY ROK (Urodziny)> = 1970 TO "1979-1970" KIEDY URODZINY NIE JEST PUNKTOWE TO "przed 1970" ELSE "nie określono" END
Te. w tym przypadku grupowanie odbywa się według wyrażenia CASE wcześniej obliczonego dla każdego pracownika: SELECT ID, CASE WEN YEAR (Urodziny)> = 2000 THEN "od 2000" WHEN YEAR (Urodziny)> = 1990 THEN "1999-1990" WHEN YEAR (Urodziny)> = 1980 THEN "1989-1980" WHEN YEAR (Urodziny) > = 1970 THEN "1979-1970" KIEDY URODZINY NIE JEST NULL THEN "przed 1970" ELSE "nie określono" KONIEC OD Pracownicy
I oczywiście możesz łączyć wyrażenia z polami w bloku GROUP BY: SELECT IDID, CONCAT ("Rok urodzenia -", YEAR (Birthday)) YearOfBirthday, COUNT (*) EmplCount FROM Employees GROUP BY REAR (Birthday), DepartmentID - kolejność może nie pokrywać się z kolejnością ich użycia w SELECT ORDER Blok BY DepartmentID, YearOfBirthday - na koniec możemy zastosować sortowanie do wyniku Wróćmy do naszego pierwotnego zadania. Jak już wiemy, dyrektorowi ten raport bardzo się spodobał i poprosił nas o robienie tego co tydzień, aby móc monitorować zmiany w firmie. Aby za każdym razem w Excelu nie przerywać wartości liczbowej działu po jego nazwie, wykorzystamy wiedzę, którą już posiadamy i udoskonalimy nasze zapytanie: WYBIERZ PRZYPADEK ID działu WHEN 1 THEN "Administracja" WHEN 2 THEN "Księgowość" WHEN 3 THEN "IT" ELSE "Inne" KONIEC Info, COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (Salary) SalaryAmount, AVG (Salary ) SalaryAvg - plus spełniamy życzenia dyrektora OD PRACOWNIKÓW GRUPA WEDŁUG IDDZIAŁÓW ZAMÓW WG Info - dla większej wygody dodaj sortowanie po kolumnie Info Ale nic, z czasem nauczymy się robić wszystko pięknie, aby nasza próbka nie zależała od pojawiania się nowych danych w bazie, ale była dynamiczna. Pobiegnę trochę naprzód, aby pokazać, z jakimi prośbami staramy się wystąpić: SELECT ISNULL (nazwa oddziału, "Inne") Nazwa oddziału, COUNT (DISTINCT emp.PositionID) PositionCount, COUNT (*) EmplCount, SUM (prac.Salary) SalaryAmount, AVG (prac.Salary) SalaryAvg - plus spełnij życzenia dyrektor FROM Pracownicy emp LEWY DOŁĄCZ Działy dział ON mp.IDOddziału = IDOddziału GROUP BY prac.IDOddziału, NazwaOddziału ORDER BY NazwaOddziału Ogólnie rzecz biorąc, nie martw się – wszyscy zaczynali od prostych. Na razie wystarczy zrozumieć istotę klauzuli GROUP BY. Na koniec zobaczmy, jak można tworzyć raporty podsumowujące za pomocą funkcji GROUP BY. Na przykład wyświetlmy tabelę przestawną, w kontekście działów, aby obliczyć łączne wynagrodzenie otrzymywane przez pracowników według stanowiska: SELECT IDDziału, SUM (CASE WHEN IDPozycji = 1 THEN Wynagrodzenie END) [Księgowi], SUM (CASE WHEN IDPozycji = 2 THEN Wynagrodzenie END) [Dyrektorzy], SUMA (CASE WEN IDPozycji = 3 THEN Wynagrodzenie END) [Programiści], SUMA ( PRZYPADEK GDY ID stanowiska = 4 THEN Wynagrodzenie KONIEC) [Senior Programiści], SUMA (Wynagrodzenie) [Ogółem Działu] Z GRUPA PRACOWNIKÓW WEDŁUG ID działu Możesz oczywiście zostać przepisany za pomocą IIF: SELECT IDDziału, SUM (IIF (Identyfikator Stanowiska = 1, Wynagrodzenie, NULL)) [Księgowy], SUM (IIF (Identyfikator Stanowiska = 2, Wynagrodzenie, NULL)) [Dyrektorzy], SUM (IIF (Identyfikator Stanowiska = 3, Wynagrodzenie, NULL)) [Programiści], SUM (IIF (PositionID = 4, Wynagrodzenie, NULL)) [Senior Programiści], SUM (Wynagrodzenie) [Ogółem Działu] OD Pracowników GRUPA WEDŁUG ID działu Ale w przypadku IIF będziemy musieli jawnie określić NULL, który zostanie zwrócony, jeśli warunek nie zostanie spełniony. W podobnych przypadkach wolę używać CASE bez bloku ELSE niż ponownie pisać NULL. Ale to z pewnością kwestia gustu, o którą się nie dyskutuje. A pamiętajmy, że w funkcjach agregujących nie są brane pod uwagę wartości NULL. W celu konsolidacji dokonaj niezależnej analizy danych uzyskanych w ramach rozszerzonego żądania: SELECT IDDziału, CASE WEN IDPozycji = 1 THEN Wynagrodzenie END [Księgowy], CASE WEN IDPozycji = 2 THEN Wynagrodzenie END [Dyrektorzy], CASE WEN IDPozycji = 3 THEN Wynagrodzenie END [Programiści], CASE WEN IDPozycji = 4 THEN Wynagrodzenie END [Senior Programiści] ], Wynagrodzenie [Dział Razem] OD Pracownicy
Pamiętajmy też, że jeśli zamiast NULL chcemy widzieć zera, to możemy przetworzyć wartość zwracaną przez funkcję agregującą. Na przykład: SELECT ID działu, ISNULL (SUM (IIF (Identyfikator stanowiska = 1, Wynagrodzenie, NULL)), 0) [Księgowy], ISNULL (SUM (IIF (Identyfikator stanowiska = 2, Wynagrodzenie, NULL)), 0) [Dyrektorzy], ISNULL (SUM (IIF (PositionID = 3, Wynagrodzenie, NULL)), 0) [Programiści], ISNULL (SUM (IIF (PositionID = 4, Wynagrodzenie, NULL)), 0) [Starsi Programiści], ISNULL (SUM (Wynagrodzenie), 0 ) [Ogółem działu] Z GRUPA PRACOWNIKÓW WEDŁUG ID działu
GROUP BY w rzadkim z funkcjami agregacyjnymi, jednym z głównych narzędzi służących do pozyskiwania danych sumarycznych z bazy danych, ponieważ zwykle dane są używane w tej formie, ponieważ zwykle jesteśmy zobowiązani do dostarczania raportów podsumowujących, a nie szczegółowych danych (arkuszy). I oczywiście wszystko kręci się wokół znajomości podstawowego projektu, ponieważ zanim coś streścisz (zagregujesz), najpierw musisz to poprawnie zaznaczyć za pomocą "SELECT ... WHERE ...". Praktyka odgrywa tutaj ważną rolę, dlatego jeśli wyznaczysz sobie cel, aby zrozumieć język SQL, a nie uczyć się, ale rozumieć - ćwicz, ćwicz i ćwicz, przechodząc przez najróżniejsze opcje, jakie możesz wymyślić. Na początkowym etapie, jeśli nie masz pewności co do poprawności uzyskanych zagregowanych danych, wykonaj próbkę szczegółową, zawierającą wszystkie wartości, dla których agregacja się odbywa. I sprawdź poprawność obliczeń ręcznie, korzystając z tych szczegółowych danych. W takim przypadku użycie Excela może być bardzo pomocne. Powiedzmy, że dotarłeś do tego punktuZałóżmy, że jesteś księgowym S. S. Sidorovem, który postanowił nauczyć się pisać zapytania SELECT.Załóżmy, że skończyłeś już czytać ten samouczek do tego momentu i jesteś już pewny używania wszystkich powyższych podstawowych konstrukcji, tj. możesz:
Tak, ale nie wzięli pod uwagę, że nie można jeszcze budować zapytań z kilku tabel, a tylko z jednej, tj. nie wiesz jak zrobić coś takiego: WYBIERZ PRACĘ *, - zwróć wszystkie pola tabeli Pracownicy dział Nazwa NazwaDziału, - dodaj pole Nazwisko z tabeli Działy poz.Nazwa NazwaStanowiska do tych pól - a także dodaj pole Nazwisko z tabeli Stanowiska FROM Pracodawca LEWY DOŁĄCZ Działy dep ON emp.DepartmentID = dep.ID LEFT JOIN Pozycje poz ON emp.PositionID = poz.ID Jak więc wykorzystać swoją obecną wiedzę i uzyskać jeszcze bardziej produktywne wyniki?! Wykorzystamy moc kolektywnego umysłu – idziemy do programistów, którzy dla Ciebie pracują, tj. do Andreeva A.A., Petrova P.P. lub Nikolayev N.N. i poproś jednego z nich o napisanie dla Ciebie widoku (WIDOK lub po prostu „Widok”, dzięki czemu nawet szybciej Cię zrozumieją), który oprócz głównych pól z tabeli Pracownicy zwróci również pola z „Nazwa wydziału” i „Nazwa stanowiska”, których tak bardzo brakuje ci w tygodniowym raporcie, który przesłał ci Iwanow II. Dlatego wszystko dobrze wyjaśniłeś, to informatycy od razu zrozumieli, czego od nich chcą i stworzyli specjalnie dla Ciebie widok o nazwie ViewEmployeesInfo. Oświadczamy, że nie widzisz następnego polecenia, ponieważ Specjaliści IT to robią: CREATE VIEW ViewEmployeesInfo AS SELECT Emp.prac.*, - zwróć wszystkie pola tabeli Employees dep.Name DepartmentName, - dodaj do tych pól pole Name z tabeli Departments Pos.Name PositionName - a także dodaj pole Name z tabeli Positions FROM Pracownicy emp LEFT JOIN Działy dz.pracy.Działu = ID oddziału LEFT JOIN Pozycje poz ON emp.PositionID = poz.ID Te. dla Ciebie to wszystko, choć przerażające i niezrozumiałe, tekst pozostaje poza ekranem, a informatycy podają Ci tylko nazwę widoku „ViewEmployeesInfo”, który zwraca wszystkie powyższe dane (czyli to, o co ich prosiłeś). Możesz teraz pracować z tym widokiem jak ze zwykłą tabelą: WYBIERZ * Z ZobaczInformacje o pracownikach SELECT NazwaWydziału, COUNT (DISTINCT ID stanowiska) Liczba stanowisk, LICZBA (*) Liczba pracowników, SUMA (Wynagrodzenie) Kwota wynagrodzenia, ŚREDNIE (Wynagrodzenie) Śr.wynagrodzenie FROM ViewEmployeesInfo emp GROUP BY IDDziału, Nazwa działu ORDER BY NazwaWydziału Te. dla ciebie w tym przypadku, jakby nic się nie zmieniło, kontynuujesz pracę z jedną tabelą (ale bardziej poprawne byłoby z widokiem ViewEmployeesInfo), która zwraca wszystkie potrzebne dane. Dzięki pomocy informatyków szczegóły wydobycia DepartmentName i PositionName pozostają dla Ciebie w czarnej skrzynce. Te. widok wygląda tak samo jak zwykła tabela, uważaj to za rozszerzoną wersję tabeli Pracownicy. Na przykład stwórzmy oświadczenie, aby upewnić się, że wszystko jest naprawdę tak, jak powiedziałem (że cała próbka pochodzi z jednego widoku): WYBIERZ ID, Imię, Wynagrodzenie FROM ViewEmployeesInfo GDZIE Wynagrodzenie NIE JEST NULL I Wynagrodzenie> 0 ORDER BY Nazwa Wykorzystanie widoków w niektórych przypadkach pozwala znacznie poszerzyć granice użytkowników, którzy potrafią pisać podstawowe zapytania SELECT. W tym przypadku widok jest płaską tabelą ze wszystkimi danymi, których potrzebuje użytkownik (dla tych, którzy rozumieją OLAP, można to porównać do przybliżenia kostki OLAP z faktami i wymiarami). Wycinek z Wikipedii. Chociaż SQL został pomyślany jako narzędzie dla użytkownika końcowego, w końcu stał się tak złożony, że stał się narzędziem programisty. Jak widzicie, drodzy użytkownicy, język SQL został pierwotnie pomyślany jako narzędzie dla Was. Więc wszystko jest w twoich rękach i pragnieniu, nie odpuszczaj. POSIADAJĄCY - nałożenie warunku selekcji na zgrupowane daneWłaściwie, jeśli rozumiesz, czym jest grupowanie, to nie ma nic skomplikowanego w MIEĆ. HAVING jest nieco podobny do WHERE, tylko jeśli warunek WHERE jest stosowany do danych szczegółowych, to warunek HAVING jest stosowany do już zgrupowanych danych. Z tego powodu w warunkach bloku HAVING możemy użyć albo wyrażeń z polami zawartymi w grupowaniu, albo wyrażeń zawartych w funkcjach agregujących.Rozważmy przykład: WYBIERZ IDDziału, SUMA (Wynagrodzenie) Wynagrodzenie Kwota Z Pracowników GRUPA WEDŁUG IDDziału POSIADAJĄC SUMA (Wynagrodzenie)> 3000
Te. Ta prośba zwróciła nam zgrupowane dane tylko dla tych działów, dla których łączne wynagrodzenie wszystkich pracowników przekracza 3000, tj. "SUMA (Wynagrodzenie)> 3000".
Te. tutaj przede wszystkim odbywa się grupowanie i obliczane są dane dla wszystkich działów: SELECT ID Działu, SUMA (Wynagrodzenie) Kwota Wynagrodzenia Z Pracowników GRUPA WEDŁUG ID Działu - 1. uzyskaj pogrupowane dane dla wszystkich działów I już warunek określony w bloku HAVING jest stosowany do tych danych: SELECT ID działu, SUMA (Wynagrodzenie) Kwota wynagrodzenia FROM Pracownicy GRUPA WEDŁUG ID działu - 1. uzyskaj zgrupowane dane dla wszystkich działów POSIADAJĄC SUMA (Wynagrodzenie)> 3000 - 2.warunek filtrowania zgrupowanych danych W warunku HAVING możesz również budować złożone warunki za pomocą operatorów AND, OR i NOT: WYBIERZ ID działu, SUMA (Wynagrodzenie) Kwota wynagrodzenia Z GRUPA PRACOWNIKÓW WEDŁUG ID działu POSIADAJĄC SUMA (Wynagrodzenie)> 3000 I LICZBA (*)<2 -- и число людей меньше 2-х
Jak widać tutaj funkcja agregująca (patrz "LICZBA (*)") może być określona tylko w bloku HAVING. W związku z tym możemy wyświetlić tylko numer działu, który spełnia warunek HAVING: WYBIERZ ID działu Z GRUPY PRACOWNIKÓW WEDŁUG ID działu POSIADAJĄC SUMA (Wynagrodzenie)> 3000 I LICZBA (*)<2 -- и число людей меньше 2-х Przykład użycia warunku HAVING na polu zawartym w grupie GROUP BY: SELECT IDDziału, SUMA (Wynagrodzenie) Kwota Wynagrodzenia FROM Pracownicy GRUPA WEDŁUG IDDziału - 1. utwórz grupowanie POSIADAJĄC IDDziału = 3 - 2. przefiltruj wynik grupowania To tylko przykład, ponieważ w takim przypadku bardziej logiczne byłoby sprawdzenie warunku WHERE: SELECT IDDziału, SUMA (Wynagrodzenie) Kwota Wynagrodzenia FROM Pracownicy WHERE IDDziału = 3 - 1. filtruj szczegółowe dane GROUP BY IDDziału - 2. dokonaj grupowania tylko według wybranych rekordów Te. najpierw przefiltruj pracowników według działu 3, a dopiero potem dokonaj obliczeń. Uwaga. W rzeczywistości, nawet jeśli te dwa zapytania wyglądają inaczej, optymalizator DBMS może je wykonać w ten sam sposób. Myślę, że na tym kończy się opowieść o warunkach POSIADAJĄCYCH. PodsumujmyPodsumujmy dane uzyskane w drugiej i trzeciej części i rozważmy konkretną lokalizację każdej badanej konstrukcji i wskażmy kolejność ich realizacji:
Oczywiście możesz również zastosować klauzule DISTINCT i TOP, których nauczyłeś się w części drugiej, do zgrupowanych danych. Poniższe sugestie w tym przypadku dotyczą wyniku końcowego: WYBIERZ TOP 1 - 6. zastosuje ostatnią SUMA (Wynagrodzenie) WynagrodzenieKwota Z Pracowników GRUPA WEDŁUG IDDziału POSIADAJĄC SUMA (Wynagrodzenie)> 3000 ZAMÓWIENIE WG IDDziału - 5.sortuj wynik Przeanalizuj sam, w jaki sposób uzyskano te wyniki. WniosekGłównym celem, który postawiłem w tej części, jest odkrycie dla Ciebie istoty funkcji agregujących i grupowań.Jeśli podstawowy projekt pozwolił nam uzyskać niezbędne dane szczegółowe, to zastosowanie funkcji agregujących i grupowań do tych szczegółowych danych dało nam możliwość uzyskania na ich temat danych zbiorczych. Tak więc, jak widać, wszystko jest tutaj ważne, tk. jedno oparte jest na drugim – bez znajomości podstawowej struktury nie będziemy w stanie np. poprawnie dobrać danych, dla których musimy obliczyć sumy. Tutaj celowo staram się pokazać tylko podstawy, aby skupić uwagę początkującego na najważniejszych strukturach i nie przeciążać ich niepotrzebnymi informacjami. Dobre zrozumienie podstawowych struktur (o których będę mówił w kolejnych częściach) da Ci możliwość rozwiązania niemal każdego problemu pobierania danych z RDB. Podstawowe konstrukcje instrukcji SELECT mają zastosowanie w tej samej formie w prawie wszystkich SZBD (różnice tkwią głównie w szczegółach, na przykład w implementacji funkcji - do pracy z ciągami, czasem itp.). Z kolei solidna znajomość bazy da Ci możliwość łatwego samodzielnego poznania różnych rozszerzeń języka SQL, takich jak:
Jeśli stawiasz pierwsze kroki w SQL, najpierw skup się na nauce podstawowych konstrukcji. posiadając bazę, wszystko inne będzie ci znacznie łatwiej zrozumieć, a poza tym na własną rękę. Przede wszystkim musisz dogłębnie zrozumieć możliwości języka SQL, tj. jaki rodzaj operacji generalnie umożliwia wykonanie na danych. Przekazywanie informacji początkującym w obszernej formie to kolejny z powodów, dla których pokażę tylko najważniejsze (żelazne) konstrukcje. Powodzenia w nauce i zrozumieniu języka SQL. Część czwarta - Zespół CASE pozwala wybrać dla jeden z wiele sekwencji poleceń... Konstrukcja ta jest obecna w standardzie SQL od 1992 roku, chociaż nie była obsługiwana w Oracle SQL do Oracle8i, a w PL/SQL do Oracle9i Release 1. Począwszy od tej wersji obsługiwane są następujące odmiany poleceń CASE:
NULL czy NIEZNANE?W artykule dotyczącym instrukcji IF mogłeś dowiedzieć się, że wynikiem wyrażenia logicznego może być TRUE, FALSE lub NULL. W PL/SQL jest to prawda, ale w szerszym kontekście teorii relacji uważa się za niepoprawne mówienie o zwróceniu wartości NULL z wyrażenia logicznego. Teoria relacyjna mówi, że porównania z NULL są takie: 2 < NULL daje logiczny wynik UNKNOWN, a UNKNOWN nie jest NULL. Jednak nie powinieneś się zbytnio przejmować używaniem przez PL/SQL NULL dla UNKNOWN. Należy jednak pamiętać, że trzecia wartość w logice 3-wartościowej jest NIEZNANA. I mam nadzieję, że nigdy (tak jak ja!) nie wpadniesz w pułapkę niewłaściwego terminu podczas omawiania trójwartościowej logiki z ekspertami w dziedzinie teorii relacji. Oprócz poleceń CASE, PL/SQL obsługuje również wyrażenia CASE. To wyrażenie jest bardzo podobne do polecenia CASE, pozwala wybrać jedno lub więcej wyrażeń do oceny. Wynikiem wyrażenia CASE jest jedna wartość, natomiast wynikiem polecenia CASE jest wykonanie sekwencji poleceń PL/SQL. Proste polecenia CASEProste polecenie CASE pozwala wybrać jedną z kilku sekwencji poleceń PL / SQL do wykonania na podstawie wyniku oceny wyrażenia. Jest napisany w następujący sposób: wyrażenie CASE WHEN wynik_1 THEN polecenie_1 WHEN wynik_2 THEN polecenie_2 ... ELSE polecenie_else END CASE; Oddział ELSE jest tutaj opcjonalny. Wykonując takie polecenie, PL / SQL najpierw ocenia wyrażenie, a następnie porównuje wynik z result_1. Jeśli pasują, wykonywane są polecenia_1. W przeciwnym razie sprawdzana jest wartość result_2 i tak dalej. Oto przykład prostego polecenia CASE, w którym premia naliczana jest w zależności od wartości zmiennej typ_pracownika: CASE typ_pracownika KIEDY "S" TO WTEDY award_salary_bonus (employee_id); KIEDY „H” TO nagroda_godzinowa_bonus (identyfikator_pracownika); KIEDY „C” TO award_commissioned_bonus (employee_id); ELSE RAISE invalid_employee_type; PRZYPADEK KOŃCOWY; W tym przykładzie istnieje wyraźna klauzula ELSE, ale generalnie nie jest ona wymagana. Bez klauzuli ELSE kompilator PL/SQL niejawnie zastępuje następujący kod: JESZCZE PODNIEŚ CASE_NOT_FOUND; Innymi słowy, jeśli pominiesz słowo kluczowe ELSE i jeśli żaden z wyników w klauzulach WHEN nie pasuje do wyniku wyrażenia w poleceniu CASE, PL / SQL zgłosi wyjątek CASE_NOT_FOUND. To jest różnica między tym poleceniem a JEŻELI. Gdy słowo kluczowe ELSE jest nieobecne w poleceniu IF, nic się nie dzieje, jeśli warunek nie jest spełniony, podczas gdy w poleceniu CASE podobna sytuacja prowadzi do błędu. Interesujące będzie zobaczyć, jak zaimplementować logikę obliczania premii opisaną na początku rozdziału za pomocą prostego polecenia CASE. Na pierwszy rzut oka wydaje się to niemożliwe, ale zabierając się twórczo do biznesu, dochodzimy do następującego rozwiązania: PRZYPADEK PRAWDZIWY KIEDY pensja> = 10000 AND pensja<=20000 THEN give_bonus(employee_id, 1500); WHEN salary >20 000 I wynagrodzenie<= 40000 THEN give_bonus(employee_id, 1000); WHEN salary >40000 THEN daj_bonus (identyfikator_pracownika, 500); ELSE daje_bonus (identyfikator_pracownika, 0); PRZYPADEK KOŃCOWY; Ważną rzeczą tutaj jest to, że wyrażenie i elementy wynikowe mogą być wartościami skalarnymi lub wyrażeniami, których wyniki są wartościami skalarnymi. Wracając do polecenia IF ... THEN ... ELSIF, które implementuje tę samą logikę, zobaczysz, że sekcja ELSE jest zdefiniowana w poleceniu CASE, natomiast w poleceniu IF – THEN – ELSIF brakuje słowa kluczowego ELSE. Powód dodania ELSE jest prosty: jeśli żaden z warunków premii nie jest spełniony, polecenie IF nic nie robi, a premia wynosi zero. W takim przypadku polecenie CASE generuje błąd, więc sytuacja z zerową premią musi być zaprogramowana jawnie. Aby zapobiec błędom CASE_NOT_FOUND, upewnij się, że co najmniej jeden z warunków zostanie spełniony dla dowolnej wartości testowanego wyrażenia. Powyższe polecenie CASE TRUE może dla niektórych brzmieć jak sztuczka, ale tak naprawdę implementuje tylko polecenie wyszukiwania CASE, o którym będziemy mówić w następnej sekcji. Polecenie wyszukiwania CASEPolecenie wyszukiwania CASE sprawdza listę wyrażeń logicznych; po znalezieniu wyrażenia równego TRUE, wykonuje sekwencję poleceń z nim związanych. Zasadniczo polecenie wyszukiwania CASE jest analogiczne do polecenia CASE TRUE pokazanego w poprzedniej sekcji. Polecenie wyszukiwania CASE ma następującą notację: CASE WHEN wyrażenie_1 THEN polecenie_1 GDY wyrażenie_2 THEN polecenie_2 ... ELSE polecenie_else END CASE; Idealnie nadaje się do implementacji logiki naliczania premii: PRZYPADEK, KIEDY pensja> = 10000 AND pensja<=20000 THEN give_bonus(employee_id, 1500); WHEN salary >20 000 I wynagrodzenie<= 40000 THEN give_bonus(employee_id, 1000); WHEN salary >40000 THEN daj_bonus (identyfikator_pracownika, 500); ELSE daje_bonus (identyfikator_pracownika, 0); PRZYPADEK KOŃCOWY; Polecenie wyszukiwania CASE, podobnie jak proste polecenie, podlega następującym zasadom:
Rozważmy inną implementację logiki obliczania premii, która wykorzystuje fakt, że warunki KIEDY są sprawdzane w kolejności ich zapisywania. Poszczególne wyrażenia są prostsze, ale czy możemy powiedzieć, że znaczenie całego polecenia stało się jaśniejsze? PRZYPADEK GDY pensja> 40000 THEN give_bonus (employee_id, 500); KIEDY wynagrodzenie > 20000 THEN daj_bonus (identyfikator pracownika, 1000); KIEDY pensja> = 10000 THEN daj_bonus (identyfikator pracownika, 1500); ELSE daje_bonus (identyfikator_pracownika, 0); PRZYPADEK KOŃCOWY; Jeśli dany pracownik ma pensję w wysokości 20 000, to dwa pierwsze warunki są NIEPRAWIDŁOWE, a trzeci PRAWDZIWE, więc pracownik otrzyma premię w wysokości 1500 USD. Jeśli wynagrodzenie wynosi 21 000, wynik drugiego warunku będzie PRAWDZIWY, a premia wyniesie 1000 USD. Wykonanie polecenia CASE zakończy się na drugiej gałęzi WHEN, a trzeci warunek nie zostanie nawet sprawdzony. Kwestią sporną jest, czy to podejście powinno być stosowane podczas pisania poleceń CASE. Tak czy inaczej, pamiętaj, że możliwe jest napisanie takiego polecenia i wymagana jest szczególna ostrożność podczas debugowania i edycji programów, w których wynik zależy od kolejności wyrażeń. Logika polegająca na uporządkowaniu jednorodnych gałęzi KIEDY jest potencjalnym źródłem błędów wynikających z ich przestawiania. Jako przykład rozważmy następujące polecenie wyszukiwania CASE, w którym przy zapłacie 20 000 sprawdzanie warunków w obu klauzulach WHEN daje wartość TRUE: PRZYPADEK, KIEDY wynagrodzenie MIĘDZY 10000 A 20000 TO give_bonus (employee_id, 1500); KIEDY wynagrodzenie MIĘDZY 20000 A 40000 TO give_bonus (employee_id, 1000); ... Wyobraź sobie, że opiekun tego programu nonszalancko przestawia klauzule WHEN, aby uporządkować je w porządku malejącym. Nie odrzucaj tej możliwości! Programiści często mają tendencję do „podkręcania” pięknie działającego kodu w oparciu o jakiś wewnętrzny porządek. Polecenie CASE z przearanżowanymi klauzulami WHEN wygląda tak: PRZYPADEK GDY wynagrodzenie POMIĘDZY 20000 A 40000 TO give_bonus (employee_id, 1000); KIEDY wynagrodzenie MIĘDZY 10000 A 20000 TO daje premię (identyfikator pracownika, 1500); ... Na pierwszy rzut oka wszystko się zgadza, prawda? Niestety ze względu na nakładanie się dwóch gałęzi KIEDY w programie pojawia się podstępny błąd. Teraz pracownik z pensją 20 000 otrzyma premię w wysokości 1000 zamiast wymaganych 1500. W niektórych sytuacjach może być pożądane nakładanie się oddziałów KIEDY, ale nadal należy tego unikać, gdy tylko jest to możliwe. Zawsze pamiętaj, że kolejność gałęzi jest ważna i powstrzymuj chęć modyfikowania już działającego kodu – „nie naprawiaj tego, co nie jest zepsute”. Ponieważ warunki WHEN są testowane w kolejności, możesz nieco poprawić wydajność kodu, umieszczając gałęzie z najbardziej prawdopodobnymi warunkami na górze listy. Ponadto, jeśli masz gałąź z "drogimi" wyrażeniami (na przykład wymagającymi znacznego czasu procesora i pamięci), możesz umieścić je na końcu, aby zminimalizować szanse na ich przetestowanie. Zobacz sekcję Zagnieżdżone polecenia JEŻELI, aby uzyskać szczegółowe informacje. Polecenia wyszukiwania CASE są używane, gdy polecenia do wykonania są zdefiniowane przez zestaw wyrażeń logicznych. Proste polecenie CASE jest używane, gdy decyzja jest podejmowana na podstawie wyniku pojedynczego wyrażenia.
Zagnieżdżone polecenia CASEPolecenia CASE, podobnie jak polecenia IF, mogą być zagnieżdżane. Na przykład zagnieżdżone polecenie CASE pojawia się w następującej (raczej mylącej) implementacji logiki bonusowej: PRZYPADEK, KIEDY wynagrodzenie> = 10000 TO PRZYPADEK, KIEDY wynagrodzenie<= 20000 THEN give_bonus(employee_id, 1500); WHEN salary >40000 THEN daj_bonus (identyfikator_pracownika, 500); KIEDY wynagrodzenie> 20000 THEN daj_bonus (identyfikator pracownika, 1000); PRZYPADEK KOŃCOWY; KIEDY wynagrodzenie< 10000 THEN give_bonus(employee_id,0); END CASE; W poleceniu CASE można użyć dowolnego polecenia, więc wewnętrzne polecenie CASE można łatwo zastąpić poleceniem IF. Podobnie każde polecenie może być zagnieżdżone w instrukcji IF, w tym CASE. Wyrażenia CASEWyrażenia CASE wykonują to samo zadanie co polecenia CASE, ale nie dla poleceń wykonywalnych, ale dla wyrażeń. Proste wyrażenie CASE wybiera jedno z kilku wyrażeń do oceny na podstawie określonej wartości skalarnej. Wyrażenie wyszukiwania CASE ocenia wyrażenia na liście sekwencyjnie, aż jedno z nich zwróci wartość TRUE, a następnie zwraca wynik skojarzonego wyrażenia. Składnia tych dwóch odmian wyrażeń CASE to: Simple_Case_expression: = CASE wyrażenie WHEN wynik_1 THEN wynik_wyrażenie_1 WHEN wynik_2 THEN wynik_wyrażenie_2 ... ELSE wynik_wyrażenie_else END; Search_Case_expression: = CASE WHEN wyrażenie_1 THEN wynik_wyrażenie_1 WHEN wyrażenie_2 THEN wynik_wyrażenie_2 ... ELSE wynik_wyrażenie_else END; Wyrażenie CASE zwraca jedną wartość — wynik wyrażenia wybranego do oceny. Każda klauzula WHEN musi być powiązana z jednym wyrażeniem wynikowym (ale nie z poleceniem). Na końcu wyrażenia CASE nie ma średnika ani END CASE. Wyrażenie CASE kończy się słowem kluczowym END. Poniżej znajduje się przykład prostego wyrażenia CASE używanego w połączeniu z procedurą PUT_LINE pakietu DBMS_OUTPUT w celu wyświetlenia wartości zmiennej logicznej. ZADEKLARUJ boolean_true BOOLEAN: = PRAWDA; boolean_false BOOLEAN: = FAŁSZ; boolean_null BOOLEAN; FUNKCJA boolean_to_varchar2 (flaga W BOOLEAN) RETURN VARCHAR2 JEST POCZĄTEK POWRÓT CASE flag GDY TRUE TO „True” KIEDY FALSE TO „False” ELSE „NULL” END; KONIEC; BEGIN DBMS_OUTPUT.PUT_LINE (boolean_to_varchar2 (boolean_true)); DBMS_OUTPUT.PUT_LINE (boolean_to_varchar2 (boolean_false)); DBMS_OUTPUT.PUT_LINE (boolean_to_varchar2 (boolean_null)); KONIEC; Aby zaimplementować logikę obliczania premii, można użyć wyrażenia wyszukiwania CASE, które zwraca wartość premii dla danego wynagrodzenia: ZADEKLARUJ WYNAGRODZENIE NUMER: = 20000; identyfikator_pracownika NUMER: = 36325; PROCEDURA give_bonus (emp_id W LICZBIE, bonus_amt W LICZBIE) TO POCZĄTEK DBMS_OUTPUT.PUT_LINE (emp_id); DBMS_OUTPUT.PUT_LINE (bonus_amt); KONIEC; BEGIN give_bonus (employee_id, CASE, GDY pensja> = 10000 AND pensja<= 20000 THEN 1500 WHEN salary >20 000 I wynagrodzenie<= 40000 THEN 1000 WHEN salary >40 000 TO 500 JESZCZE 0 KONIEC); KONIEC; Wyrażenia CASE można używać wszędzie tam, gdzie można użyć wyrażeń dowolnego innego typu. Poniższy przykład używa wyrażenia CASE do obliczenia składki, pomnożenia jej przez 10 i przypisania wyniku do zmiennej wyświetlanej przez DBMS_OUTPUT: ZADEKLARUJ WYNAGRODZENIE NUMER: = 20000; identyfikator_pracownika NUMER: = 36325; bonus_amount NUMBER; BEGIN bonus_amount: = CASE WHEN pensja> = 10000 AND pensja<= 20000 THEN 1500 WHEN salary >20 000 I wynagrodzenie<= 40000 THEN 1000 WHEN salary >40000 TO 500 JESZCZE 0 KONIEC * 10; DBMS_OUTPUT.PUT_LINE (kwota_bonusu); KONIEC; W przeciwieństwie do polecenia CASE, jeśli żadna klauzula WHEN nie jest spełniona, wyrażenie CASE nie zgłasza błędu, ale po prostu zwraca NULL. Popularny
Nowość na stronie
|