Podmíněné výrazy CASE. Podmíněné výrazy CASE Výraz CASE je podmíněný příkaz jazyka SQL
Výraz CASE
Funkce DECODE
Používají se dvě metody:
Dvě metody, které se používají k implementaci podmíněného zpracování (logika IF-THEN-ELSE) v příkazu SQL, jsou výraz CASE a funkce DECODE.
Poznámka: Výraz CASE odpovídá ANSI SQL. Funkce DECODE je specifická pro syntaxi Oracle.
Výraz CASE
Zjednodušuje podmíněné dotazy tím, že funguje příkaz IF-THEN-ELSE:
Výrazy CASE umožňují používat v příkazech SQL logiku IF-THEN-ELSE, aniž byste museli volat procedury.
Jednoduše podmíněný výraz PŘÍPAD Oracle Server hledá první KDY ... POTOM pár, pro který se expr rovná porovnání_expr a vrátí return_expr. Pokud žádný z párů WHEN ... THEN tuto podmínku nesplňuje a pokud existuje klauzule else, Oracle vrátí else_expr. Jinak Oracle vrátí hodnotu null. Nelze zadat NULL pro všechny return_exprs a else_expr.
Expr a comparison_expr musí být stejný datový typ, který může být CHAR, VARCHAR2, NCHAR nebo NVARCHAR2. Všechny návratové hodnoty (return_expr) musí být stejného datového typu.
V této syntaxi Oracle porovnává vstupní výraz (e) s každým srovnávacím výrazem e1, e2, ..., en.
Pokud se vstupní výraz rovná jakémukoli srovnávacímu výrazu, vrátí výraz CASE odpovídající výraz výsledku (r).
Pokud vstupní výraz e neodpovídá žádnému srovnávacímu výrazu, vrátí výraz CASE výraz v klauzuli ELSE, pokud klauzule ELSE existuje, v opačném případě vrátí hodnotu null.
Oracle používá vyhodnocení zkratu pro jednoduchý výraz CASE. To znamená, že Oracle vyhodnotí každý srovnávací výraz (e1, e2, .. en) pouze před porovnáním jednoho se vstupním výrazem (e). Společnost Oracle nehodnotí všechny srovnávací výrazy před porovnáním kteréhokoli z nich s výrazem (e). Výsledkem je, že Oracle nikdy nevyhodnocuje srovnávací výraz, pokud se předchozí rovná vstupnímu výrazu (e).
Příklad jednoduchého CASE výrazu
Pro demonstraci použijeme tabulku produktů v.
Následující dotaz používá výraz CASE k výpočtu slevy pro každou kategorii produktu, tj. CPU 5%, grafická karta 10% a další kategorie produktů 8%
VYBRAT CASE category_id KDY 1 THEN ROUND (list_price * 0,05,2) - CPU KDY 2 PAK KOLO (List_price * 0,1,2) - grafická karta JINÉ KOLO (list_price * 0,08,2) - další kategorie KONEC sleva Z SEŘADIT PODLE |
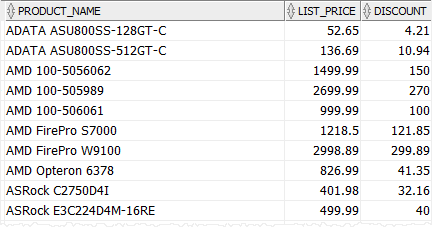
Všimněte si, že jsme zaokrouhlili slevu na dvě desetinná místa pomocí funkce ROUND ().
Hledaný výraz CASE
Hledaný výraz CASE v systému Oracle vyhodnotí seznam booleovských výrazů a určí výsledek.
Hledaný příkaz CASE má následující syntaxi:
PŘÍPAD KDY e1TH1 r1 , COUNT (DISTINCT DepartmentID) [Počet jedinečných oddělení], COUNT (DISTINCT PositionID) [Počet jedinečných pozic], COUNT (BonusPercent) [Počet zaměstnanců s% bonusem], MAX (BonusPercent) [Maximální procento bonusu], MIN ( BonusPercent) [Minimální procento bonusu], SUM (plat / 100 * BonusPercent) [součet všech bonusů], AVG (plat / 100 * BonusPercent) [průměrný bonus], AVG (plat) [průměrný plat] OD zaměstnanců Pojďme se podívat na to, jak každá návratová hodnota vznikla, a zaprvé si připomeňme konstrukce základní syntaxe příkazu SELECT. Nejprve proto v dotazu jsme nezadali WHERE podmínky, pak se vypočítají součty pro podrobná data získaná dotazem: VYBERTE * OD zaměstnanců Ty. pro všechny řádky tabulky Zaměstnanci. Pro přehlednost vybereme pouze pole a výrazy, které se používají v agregačních funkcích: VYBERTE ID oddělení, ID pozice, BonusPercent, plat / 100 * BonusPercent, plat od zaměstnanců
Toto jsou počáteční data (podrobné řádky), podle kterých se vypočítají součty agregovaného dotazu. Nyní se podívejme na každou agregovanou hodnotu:
Shrňme některé z výsledků:
V souladu s tím se při nastavení další podmínky s agregačními funkcemi v klauzuli WHERE počítají pouze součty pro řádky, které splňují podmínku. Ty. výpočet agregovaných hodnot se provádí pro celkovou množinu, která se získá pomocí konstrukce SELECT. Udělejme například všechno stejně, ale pouze v kontextu IT oddělení: VYBERTE POČET (*) [Celkový počet zaměstnanců], POČET (DISTINCT DepartmentID) [Počet jedinečných oddělení], POČET (DISTINCTID pozice) [Počet jedinečných pozic], POČET (BonusPercent) [Počet zaměstnanců s% bonusem], MAX (BonusPercent) [maximální procento bonusu], MIN (BonusPercent) [minimální procento bonusu], SUM (plat / 100 * BonusPercent) [součet všech bonusů], AVG (plat / 100 * BonusPercent) [průměrná velikost bonusu], AVG ( Plat) [Průměrný plat] OD zaměstnanců WHERE DepartmentID = 3 - Zvažte pouze oddělení IT VYBERTE ID oddělení, ID pozice, BonusPercent, plat / 100 * BonusPercent, plat OD zaměstnanců WHERE DepartmentID = 3 - zahrňte pouze oddělení IT
Pokračuj. Pokud agregační funkce vrací NULL (například všichni zaměstnanci nemají hodnotu Plat), nebo nebyl do výběru zahrnut jediný záznam a v sestavě musíme v takovém případě ukázat 0, pak funkce ISNULL může zabalit agregovaný výraz: VYBRAT SUM (plat), AVG (plat), - zpracovat součet pomocí ISNULL ISNULL (SUM (plat), 0), ISNULL (AVG (plat), 0) OD zaměstnanců WHERE DepartmentID = 10 - neexistující oddělení je speciálně zde uvedeno, aby se zabránilo dotazu v návratu záznamů
Věřím, že je velmi důležité pochopit účel každé agregační funkce a jak ji vypočítat, protože v SQL je to hlavní nástroj pro výpočet součtů. V tomto případě jsme zkoumali, jak se každá agregační funkce chová nezávisle, tj. bylo aplikováno na hodnoty celé sady záznamů získané příkazem SELECT. Dále se podíváme na to, jak se tyto stejné funkce používají k výpočtu celkových skupin pomocí klauzule GROUP BY. GROUP BY - seskupení datPřed tím jsme již vypočítali součty pro konkrétní oddělení, zhruba takto:VYBERTE POČET (DISTINCT ID pozice) PositionCount, COUNT (*) EmplCount, SUMA (plat) SalaryAmount OD zaměstnanců WHERE DepartmentID = 3 - data pouze pro IT oddělení Nyní si představte, že jsme byli požádáni, abychom získali stejné údaje v kontextu každého oddělení. Samozřejmě si můžeme vyhrnout rukávy a splnit stejný požadavek pro každé oddělení. Takže hned, než to uděláme, napíšeme 4 žádosti: VYBERTE "Správa" Informace, POČET (DISTINCT ID pozice) PositionCount, POČET (*) EmplCount, SUM (Plat) SalaryAmount OD zaměstnanců WHERE DepartmentID = 1 - údaje o správě VYBERTE "Informace o účetnictví", POČET (DISTINCT PositionID) PositionCount, POČET (* ) EmplCount, SUM (plat) SalaryAmount FROM zaměstnanců WHERE DepartmentID = 2 - účetní data VYBRAT „IT“ informace, POČET (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (plat) SalaryAmount OD zaměstnanců WHERE DepartmentID = 3 - údaje o IT oddělení VYBERTE „Jiné“ informace, POČET (DISTINCTID pozice), POČET POČET, POČET (*) EmplCount, SUM (plat) SalaryAmount OD zaměstnanců, KDE JE ID ODDĚLENÍ NULL - a nezapomeňte na údaje o nezávislých Ve výsledku získáme 4 datové sady:
Vezměte prosím na vědomí, že můžeme použít pole uvedená jako konstanty - „Správa“, „Účetnictví“, ... Obecně jsme extrahovali všechna čísla, která byla od nás požadována, vše kombinujeme v aplikaci Excel a dáme to řediteli. Ředitelovi se zpráva líbila a říká: „a přidejte další sloupec s informacemi o průměrném platu.“ A jako vždy je třeba to udělat velmi naléhavě. Hmm, co dělat?! Navíc si představme, že naše oddělení nejsou 3, ale 15. Přesně to je klauzule GROUP BY pro takové případy: VYBERTE DepartmentID, COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (Salary) SalaryAmount, AVG (Salary) SalaryAvg - plus plníme přání ředitele FROM Zaměstnanci SKUPINA PODLE DepartmentID
Získali jsme všechna stejná data, ale nyní používáme pouze jeden požadavek! Zatím nevěnujte pozornost tomu, že se naše oddělení zobrazují ve formě čísel, pak se naučíme, jak vše krásně zobrazit. V klauzuli GROUP BY můžete zadat několik polí "GROUP BY pole1, pole2, ..., poleN", v tomto případě dojde ke seskupení podle skupin, které tvoří hodnoty těchto polí "pole1, pole2, .. ., poleN ". Pojďme například seskupit data podle oddělení a pozic: VYBERTE ID oddělení, ID pozice, POČET (*) EmplCount, SUMA (plat) SalaryAmount OD zaměstnanců SKUPINU PODLE ID oddělení, ID pozice VYBERTE POČET (*) EmplCount, SUM (plat) SalaryAmount FROM zaměstnanců KDE JE IDENTIFIKÁTOR NULL A PositionID JE NULL VYBERTE POČET (*) EmplCount, SUM (plat) SalaryAmount FROM zaměstnanců KDE JE IDENTIFIKÁTOR = 1 A PositionID = 2 - ... VYBERTE POČET (*) EmplCount, SUM (plat) SalaryAmount OD zaměstnanců WHERE DepartmentID = 3 AND PositionID = 4 A pak jsou všechny tyto výsledky spojeny dohromady a dány nám jako jednu sadu:
Z hlavní stojí za zmínku, že v případě seskupení (GROUP BY) v seznamu sloupců v bloku SELECT:
A ukázka všeho, co bylo řečeno: VYBERTE "Stringová konstanta" Const1, - konstanta ve formě řetězce 1 Const2, - konstanta ve formě čísla - výraz pomocí polí účastnících se ve skupině CONCAT ("Číslo oddělení", DepartmentID) ConstAndGroupField, CONCAT ("Oddělení Č. ", DepartmentID,", číslo pozice ", PositionID) ConstAndGroupFields, DepartmentID, - pole ze seznamu polí účastnících se seskupení - PositionID, - pole účastnící se seskupení, zde není nutné duplikovat COUNT ( *) EmplCount, - počet řádků v každé skupině - zbytek polí lze použít pouze s agregačními funkcemi: COUNT, SUM, MIN, MAX,… SUM (plat) SalaryAmount, MIN (ID) MINID OD zaměstnanců SKUPINU PODLE DepartmentID , PositionID - seskupení podle polí DepartmentID, PositionID Za zmínku stojí také to, že seskupování lze provést nejen podle polí, ale také podle výrazů. Pojďme například seskupit data podle zaměstnanců podle roku narození: VÝBĚR KONCATU ("Rok narození -", ROK (Narozeniny)) YearOfBirthday, POČET (*) EmplCount OD zaměstnanců SKUPINA DO ROKU (Narozeniny) Podívejme se na příklad se složitějším výrazem. Pojďme například získat hodnocení zaměstnanců podle roku narození: VYBERTE PŘÍPAD KDY ROK (Narozeniny)> = 2000 PAK "od roku 2000" KDY ROK (Narozeniny)> = 1990 POTOM "1999-1990" KDY ROK (Narozeniny)> = 1980 POTOM "1989-1980" KDY ROK (Narozeniny)> = 1970 POTOM „1979-1970“ KDY NAROZENINY NENÍ NULOVÁ “před 1970„ ELSE “nespecifikováno„ END RangeName, COUNT (*) EmplCount OD zaměstnanců SKUPINA PODLE PŘÍPADŮ KDY ROK (Narozeniny)> = 2000 POTOM “od roku 2000„ KDY ROK (Narozeniny)> = 1990 PAK "1999-1990" KDY ROK (Narozeniny)> = 1980 PAK "1989-1980" KDY ROK (Narozeniny)> = 1970 POTOM "1979-1970" KDY NARODENINY NENÍ NULL PAK "před rokem 1970" JINÉ „nespecifikováno“ KONEC
Ty. v tomto případě se seskupení provádí podle výrazu CASE, který byl dříve vypočítán pro každého zaměstnance: VYBERTE ID, PŘÍPAD KDY ROK (Narozeniny)> = 2000 PAK "od roku 2000" KDY ROK (Narozeniny)> = 1990 POTOM "1999-1990" KDY ROK (Narozeniny)> = 1980 POTOM "1989-1980" KDY ROK (Narozeniny) > = 1970 PAK
A samozřejmě můžete kombinovat výrazy s poli v bloku GROUP BY: SELECT DepartmentID, CONCAT ("Rok narození -", YEAR (Narozeniny)) YearOfBirthday, COUNT (*) EmplCount OD zaměstnanců SKUPINOVĚ DO ROKU (Narozeniny), DepartmentID - objednávka se nemusí shodovat s objednávkou jejich použití ve VÝBĚRU OBJEDNÁVKY BY DepartmentID block, YearOfBirthday - konečně můžeme na výsledek použít třídění Vraťme se k původnímu úkolu. Jak již víme, řediteli se zpráva velmi líbila a požádal nás, abychom to dělali každý týden, aby mohl sledovat změny ve společnosti. Abychom nepřerušili pokaždé v aplikaci Excel číselnou hodnotu oddělení jménem, použijeme znalosti, které již máme, a vylepšíme náš dotaz: VYBERTE CASE DepartmentID KDY 1 POTOM „Správa“ KDY 2 POTOM „Účetnictví“ KDY 3 POTOM „TO“ JINÉ „Jiné“ KONEC Info, POČET (DISTINCTID pozice) PositionCount, POČET (*) EmplCount, SUM (plat) SalaryAmount, AVG (plat ) SalaryAvg - plus plníme přání ředitele OD OD zaměstnanců SKUPINA PODLE ODDĚLENÍ OBJEDNÁVKA PODLE INFORMACE - pro větší pohodlí přidejte řazení podle sloupce Informace Ale nic se časem naučíme dělat všechno krásně, aby náš vzorek nezávisel na vzhledu nových dat v databázi, ale byl dynamický. Půjdu trochu dopředu, abych ukázal, jaké požadavky se snažíme přijít: VYBERTE ISNULL (dep.Name, "Other") DepName, COUNT (DISTINCT emp.PositionID) PositionCount, COUNT (*) EmplCount, SUM (emp.Salary) SalaryAmount, AVG (emp.Salary) SalaryAvg - plus splňte přání ředitel FROM Zaměstnanci emp LEFT JOIN Departments dep ON emp.DepartmentID = dep.ID GROUP BY emp.DepartmentID, dep.Name ORDER BY DepName Obecně se nebojte - každý začal jednoduše. Prozatím stačí pochopit podstatu klauzule GROUP BY. Nakonec se podívejme, jak můžete vytvářet souhrnné sestavy pomocí GROUP BY. Například si v kontextu oddělení zobrazíme kontingenční tabulku, takže se vypočítá celková mzda, kterou zaměstnanci dostanou podle pozice: VYBERTE ID oddělení, SUM (PŘÍPAD, KDY PositionID = 1 POTOM KONEC platu) [Účetní], SUM (PŘÍPAD, KDY PositionID = 2 POTOM KONEC platu) [Ředitelé], SUM (PŘÍPAD, KDY PositionID = 3 POTOM KONEC platu) [Programátoři], SUM ( PŘÍPAD KDYŽ ID pozice = 4 POTOM KONEC platu) [Senior Programmers], SUM (Plat) [Oddělení celkem] OD zaměstnanců SKUPINU PODLE Oddělení Můžete je samozřejmě přepsat pomocí IIF: VÝBĚR DepartmentID, SUMA (IIF (PositionID = 1, plat, NULL)) [účetní], SUM (IIF (PositionID = 2, plat, NULL)) [ředitelé], SUM (IIF (PositionID = 3, plat, NULL)) [Programátoři], SUM (IIF (PositionID = 4, Plat, NULL)) [Senior Programmers], SUM (Plat) [Oddělení celkem] OD zaměstnanců SKUPINU PODLE ODDĚLENÍ Ale v případě IIF musíme explicitně zadat NULL, který se vrátí, pokud podmínka není splněna. V podobných případech dávám přednost použití CASE bez bloku ELSE, než znovu zapsat NULL. Ale to je určitě věc vkusu, o které se nediskutuje. A pamatujme, že hodnoty NULL nejsou v agregačních funkcích brány v úvahu. Chcete-li konsolidovat, proveďte nezávislou analýzu dat získaných rozšířeným požadavkem: VYBERTE ID oddělení, PŘÍPAD KDY Pozice ID = 1 POTOM KONEC platu [Účetní], PŘÍPAD KDY Pozice ID = 2 POTOM KONEC platu [Ředitelé], PŘÍPAD KDY Pozice ID = 3 POTOM KONEC platu [Programátoři], PŘÍPAD KDY Pozice ID = 4 POTOM KONEC platu [Senior Programátoři ], Plat [Oddělení celkem] OD zaměstnanců
A také si zapamatujme, že pokud místo NULL chceme vidět nuly, můžeme zpracovat hodnotu vrácenou agregační funkcí. Například: VYBERTE ID oddělení, ISNULL (SUM (IIF (PositionID = 1, plat, NULL)), 0) [účetní], ISNULL (SUM (IIF (PositionID = 2, plat, NULL)), 0) [ředitelé], ISNULL (SUM (IIF (PositionID = 3, plat, NULL)), 0) [programátoři], ISNULL (SUM (IIF (PositionID = 4, plat, NULL)), 0) [starší programátoři], ISNULL (SUM (plat), 0) ) [Oddělení celkem] OD zaměstnanců SKUPINU PODLE ID oddělení
SKUPINA BY v řídkých agregačních funkcích, jeden z hlavních nástrojů používaných k získání souhrnných dat z databáze, protože data se obvykle používají v této formě, protože obvykle jsme povinni poskytovat spíše souhrnné zprávy než podrobné údaje (listy). A samozřejmě se to všechno točí kolem znalosti základního designu, protože než něco shrnete (agregujete), musíte to nejprve správně vybrat pomocí „VYBRAT ... KDE ...“. Praxe zde hraje důležitou roli, a proto, pokud si stanovíte cíl porozumět jazyku SQL, ne naučit se, ale porozumět - procvičovat, procvičovat a procvičovat, procházet nejrůznějšími možnostmi, které vás napadnou. Pokud si v počáteční fázi nejste jisti správností získaných agregovaných dat, vytvořte podrobný vzorek, včetně všech hodnot, pro které agregace probíhá. A pomocí těchto podrobných údajů zkontrolujte správnost výpočtů ručně. V tomto případě může být použití aplikace Excel velmi užitečné. Řekněme, že jste se dostali do tohoto boduŘekněme, že jste účetní S. S. Sidorov, který se rozhodl naučit se psát dotazy SELECT.Řekněme, že jste tento tutoriál dočetli až do tohoto okamžiku a už s jistotou používáte všechny výše uvedené základní konstrukce, tj. můžeš:
Ano, ale nezohlednili, že ještě nemůžete vytvářet dotazy z několika tabulek, ale pouze z jedné, tj. nevíš, jak něco takového udělat: VYBRAT emp. *, - vrátit všechna pole tabulky Zaměstnanci dep. Název DepartmentName, - přidat pole Název z tabulky Departments poz. Název Pozice Název do těchto polí - a také přidat pole Název z tabulky Pozice Z FROM Zaměstnanci emp LEVÉ PŘIPOJENÍ Departments dep ON emp.DepartmentID = dep.ID LEFT JOIN Pozice pos ON ON emp.PositionID = poz.ID Jak tedy můžete využít své současné znalosti a dosáhnout ještě produktivnějších výsledků současně?! Využijeme sílu kolektivní mysli - půjdeme k programátorům, kteří pro vás pracují, tj. Andreev A.A., Petrov P.P. nebo Nikolayev N.N. a požádejte jednoho z nich, aby vám napsal pohled (VIEW nebo jednoduše „View“, aby vám dokonce rychleji porozuměl), který kromě hlavních polí z tabulky Zaměstnanci vrátí také pole s „Název oddělení“ a „Název pozice“, které vám teď tak chybí pro týdenní report, který vám Ivanov II nahrál. Protože vysvětlili jste vše správně, pak IT specialisté okamžitě pochopili, co od nich chtějí, a vytvořili, speciálně pro vás, pohled s názvem ViewEmployeesInfo. Prohlašujeme, že další příkaz nevidíte, protože IT specialisté to dělají: VYTVOŘIT ZOBRAZENÍ ViewEmployeesInfo AS SELECT emp. *, - vrátit všechna pole tabulky Zaměstnanci dep. Název DepartmentName, - přidat do těchto polí pole Název z tabulky Oddělení Název pozice Název - a také přidat pole Název z tabulky Pozice OD Emp Employment LEFT JOIN Departments dep ON emp.DepartmentID = dep.ID LEFT JOIN Positions pos ON ON emp.PositionID = pos.ID Ty. pro vás to všechno, i když děsivé a nepochopitelné, text zůstává v zákulisí a IT specialisté vám poskytnou pouze název pohledu „ViewEmployeesInfo“, který vrací všechna výše uvedená data (tj. to, o co jste je požádali). S tímto pohledem nyní můžete pracovat jako s běžnou tabulkou: VYBERTE * Z FROM ViewEmployeesInfo VYBRAT DepartmentName, COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (plat) SalaryAmount, AVG (plat) SalaryAvg FROM ViewEmployeesInfo emp GROUP BY DepartmentID, DepartmentName ORDER BY DepartmentName Ty. pro vás v tomto případě, jako by se nic nezměnilo, budete pokračovat v práci s jednou tabulkou stejným způsobem (ale správnější je to říci v pohledu ViewEmployeesInfo), která vrátí všechna data, která potřebujete. Díky pomoci IT specialistů pro vás podrobnosti těžby DepartmentName a PositionName zůstávají v černé skříňce. Ty. pohled pro vás vypadá stejně jako běžná tabulka, považujte ji za rozšířenou verzi tabulky Zaměstnanci. Například vytvořme prohlášení jako příklad, abyste se ujistili, že vše je opravdu tak, jak jsem řekl (že celý vzorek pochází z jednoho pohledu): VYBERTE ID, jméno, plat FROM ViewEmployeesInfo KDE PLAT NENÍ NULL A plat> 0 OBJEDNAT PODLE JMÉNA Použití pohledů v některých případech umožňuje výrazně rozšířit hranice uživatelů, kteří vědí, jak psát základní dotazy SELECT. V tomto případě je to pohled plochá tabulka se všemi daty, která uživatel potřebuje (pro ty, kteří rozumějí OLAP, to lze přirovnat k aproximaci krychle OLAP s fakty a dimenzemi). Výřez z Wikipedie. Ačkoli byl SQL koncipován jako nástroj pro koncového uživatele, nakonec se stal tak složitým, že se stal nástrojem programátora. Jak vidíte, vážení uživatelé, jazyk SQL byl původně koncipován jako nástroj pro vás. Takže vše je ve vašich rukou a touze, nepouštějte to. HAVING - uložení podmínky výběru seskupeným datůmVe skutečnosti, pokud rozumíte tomu, co je seskupení, není s HAVINGEM nic složitého. HAVING je poněkud podobný WHERE, pouze pokud je podmínka WHERE aplikována na podrobná data, pak je podmínka HAVING použita na již seskupená data. Z tohoto důvodu můžeme v podmínkách bloku HAVING použít buď výrazy s poli zahrnutými do seskupení, nebo výrazy uzavřené v agregačních funkcích.Zvažme příklad: VYBERTE ID oddělení, SUM (plat) Mzda částka od SKUPINY PODLE ODDÍLŮ MÁ SUM (plat)> 3000
Ty. Tento požadavek nám vrátil seskupené údaje pouze za ta oddělení, u nichž celkový plat všech zaměstnanců přesahuje 3000, tj. „SUM (plat)> 3000“.
Ty. zde nejdříve proběhne seskupení a vypočítají se údaje za všechna oddělení: VYBERTE ID oddělení, SUM (plat) SalaryAmount FROM zaměstnanců SKUPINU PODLE ID oddělení - 1. získejte seskupená data pro všechna oddělení Na tato data je již použita podmínka uvedená v bloku HAVING: VYBERTE ID oddělení, SUM (plat) SalaryAmount FROM zaměstnanců SKUPIT PODLE DepartmentID - 1. získejte seskupená data pro všechna oddělení MÁ SUM (plat)> 3000 - 2. podmínka pro filtrování seskupených dat Ve stavu HAVING můžete také vytvořit složité podmínky pomocí operátorů AND, OR a NOT: VYBERTE ID oddělení, SUM (plat) SalaryAmount FROM zaměstnanců SKUPINU PODLE DepartmentID HAVING SUM (plat)> 3000 A POČET (*)<2 -- и число людей меньше 2-х
Jak vidíte zde, agregační funkci (viz „POČET (*)“) lze zadat pouze v bloku HAVING. Podle toho můžeme zobrazit pouze číslo oddělení, které odpovídá podmínce HAVING: VYBERTE ID oddělení OD zaměstnanců SKUPINU PODLE JEDNOTEK ODDĚLENÍ SEM (plat)> 3000 A POČET (*)<2 -- и число людей меньше 2-х Příklad použití podmínky HAVING na poli zahrnutém do GROUP BY: VYBERTE ID oddělení, SUM (plat) SalaryAmount FROM zaměstnanců SKUPINU PODLE DepartmentID - 1. proveďte seskupení HAVING DepartmentID = 3 - 2. filtrujte výsledek seskupení Toto je jen příklad, protože v tomto případě by bylo logičtější zkontrolovat podmínku WHERE: VYBERTE ID oddělení, SUM (plat) SalaryAmount OD zaměstnanců WHERE DepartmentID = 3 - 1. filtrovat podrobná data SKUPINU PODLE DepartmentID - 2. vytvořit seskupení pouze podle vybraných záznamů Ty. nejprve filtrujte zaměstnance podle oddělení 3 a teprve poté proveďte výpočet. Poznámka. Ve skutečnosti, i když tyto dva dotazy vypadají odlišně, optimalizátor DBMS je může provádět stejným způsobem. Myslím, že tím končí příběh o HAVINGOVÝCH podmínkách. Pojďme to shrnoutShrňme data získaná ve druhé a třetí části a zvažte konkrétní umístění každé struktury, kterou jsme studovali, a označme pořadí jejich implementace:
Samozřejmě můžete také použít seskupené údaje klauzule DISTINCT a TOP, které jste se naučili v druhé části. Tyto návrhy se v tomto případě vztahují na konečný výsledek: VYBERTE NEJLEPŠÍ 1 - 6. použije poslední SUM (plat) SalaryAmount FROM zaměstnanců SKUPINA PODLE DepartmentID MÁ SUM (plat)> 3000 OBJEDNAT PODLE DepartmentID - 5. roztřídit výsledek Analyzujte, jak byly tyto výsledky získány sami. ZávěrHlavním cílem, který jsem si v této části stanovil, je odhalit pro vás podstatu agregačních funkcí a seskupení.Pokud nám základní design umožnil získat potřebná podrobná data, aplikace agregačních funkcí a seskupení na tato podrobná data nám poskytla příležitost získat o nich souhrnná data. Jak tedy vidíte, vše je zde důležité, tk. jeden je založen na druhém - bez znalosti základní struktury nebudeme schopni například správně vybrat data, pro která potřebujeme vypočítat součty. Zde se záměrně snažím ukázat pouze základy, abych soustředil pozornost začátečníka na nejdůležitější struktury a nepřetěžoval je zbytečnými informacemi. Solidní porozumění základním strukturám (o kterých budu dále hovořit v dalších částech) vám dá příležitost vyřešit téměř jakýkoli problém načítání dat z RDB. Základní konstrukce příkazu SELECT jsou použitelné ve stejné formě téměř ve všech DBMS (rozdíly spočívají hlavně v detailech, například v implementaci funkcí - pro práci s řetězci, čas atd.). Následná solidní znalost základny vám dá příležitost snadno se samostatně naučit různá rozšíření jazyka SQL, například:
Pokud provádíte své první kroky v SQL, nejprve se zaměřte na učení základních konstrukcí. když vlastníte základnu, vše ostatní vám bude mnohem snazší pochopit, a kromě toho na vlastní pěst. Nejprve musíte do hloubky porozumět schopnostem jazyka SQL, tj. jaký druh operace obecně umožňuje provádět na datech. Předávat informace začátečníkům v objemné formě je dalším z důvodů, proč ukážu jen ty nejdůležitější (železné) struktury. Hodně štěstí při učení a porozumění jazyku SQL. Část čtvrtá -
O čem bude pojednáno v této částiV této části se seznámíme s:
CASE výraz - podmíněný příkaz SQLTento operátor umožňuje zkontrolovat podmínky a vrátit, v závislosti na splnění konkrétní podmínky, jednoho nebo jiného výsledku.Příkaz CASE má dvě formy: Vezměme si příklad prvního formuláře CASE: VYBERTE ID, jméno, plat, PŘÍPAD, KDYŽ plat> = 3000 POTOM „RFP> = 3000“ KDYŽ plat> = 2000 POTOM “2000<= ЗП < 3000"
ELSE "ЗП < 2000"
END SalaryTypeWithELSE,
CASE
WHEN Salary>= 3000 PAK "plat> = 3000" KDY Plat> = 2000 POTEN "2000<= ЗП < 3000"
END SalaryTypeWithoutELSE
FROM Employees
Pokud není splněna žádná z podmínek KDYŽ, vrátí se hodnota zadaná za slovem ELSE (což v tomto případě znamená „ELSE RETURN ...“). Pokud není zadán žádný blok ELSE a nejsou splněny žádné podmínky WHEN, vrátí se NULL. V první i druhé formě jde blok ELSE na samém konci struktury CASE, tj. koneckonců KDYŽ podmínky. Vezměme si příklad druhého formuláře CASE: Řekněme, že pro nový rok se rozhodli odměnit všechny zaměstnance a požádali o výpočet výše bonusů podle následujícího schématu:
Pro tento úkol používáme dotaz s výrazem CASE: VYBERTE ID, jméno, plat, ID oddělení, - pro přehlednost zobrazíme procento jako řádek CASE DepartmentID - zkontrolovaná hodnota KDY 2 POTOM „10%“ - 10% z platu k vystavení účetním KDY 3 POTOM „15% „- 15% z platu, aby bylo poskytnuto IT zaměstnancům JINÉ„ 5% “- všem ostatním 5% KONEC NewYearBonusPercent, - vytvořme výraz pomocí CASE, abychom viděli výši bonusu Plat / 100 * CASE DepartmentID KDY 2 POTOM 10 - 10% z platu k vystavení Účetním KDYŽ 3 POTOM 15 - 15% z platu k vydání zaměstnancům IT JINÉ 5 - všichni ostatní po 5% KONEC BonusAmount OD zaměstnanců V souladu s tím se vrátí hodnota bloku ELSE, pokud DepartmentID neodpovídá žádné hodnotě WHEN. Pokud není k dispozici žádný jiný blok, vrátí se NULL, pokud DepartmentID neodpovídá žádné hodnotě KDYŽ. Druhý formulář CASE lze snadno reprezentovat pomocí prvního formuláře: VYBERTE ID, jméno, plat, ID oddělení, PŘÍPAD KDY ODDĚLENÍ = 2 POTOM „10%“ - 10% z platu, který bude vystaven účetním KDYŽ ODDĚLENÍ = 3 POTOM „15%“ - 15% z platu, který bude vydán zaměstnancům IT JINÉ “ 5% "- všichni ostatní 5% KONEC NewYearBonusPercent, - vytvořte výraz pomocí PŘÍPADU, abyste viděli částku bonusu Plat / 100 * PŘÍPAD, KDY DepartmentID = 2 PAK 10 - 10% z platu, který se má vyplatit účetním KDY DepartmentID = 3 PAK 15 - 15% z platu za vydání IT zaměstnanců ELSE 5 - všichni ostatní 5% za každý KONEC BonusAmount OD zaměstnanců Druhá forma je tedy jen zjednodušená notace pro ty případy, kdy musíme provést srovnání rovnosti stejné testovací hodnoty s každou hodnotou KDYŽ hodnota / výraz. Poznámka. První a druhá forma CASE jsou součástí standardu jazyka SQL, takže by s největší pravděpodobností měly být použitelné v mnoha DBMS. S MS SQL verze 2012 se objevil zjednodušený formulář notace IIF. Lze jej použít ke zjednodušení příkazu CASE, když jsou vráceny pouze 2 hodnoty. Konstrukce IIF je následující: IIF (podmínka, true_value, false_value) Ty. ve skutečnosti se jedná o obal pro následující konstrukci CASE: PŘÍPAD KDY podmínka POTOM true_value ELSE false_value END Podívejme se na příklad: VYBERTE ID, jméno, plat, IIF (plat> = 2500, "plat> = 2500", "plat."< 2500") DemoIIF, CASE WHEN Salary>= 2500 POTÉ „RFP> = 2500„ JINÉ “RFP< 2500" END DemoCASE FROM Employees CASE, konstrukce IIF mohou být vnořeny do sebe navzájem. Uvažujme o abstraktním příkladu: VYBERTE ID, jméno, plat, PŘÍPAD, KDYŽ ODDĚLENÍ V (1,2) POTOM „A“ KDYŽ ODDĚLENÍ = 3 PAK PŘÍPAD PositionID - vnořený PŘÍPAD KDYKOLI 3 POTOM „B-1“ KDYŽ 4 POTOM „B-2“ KONEC JINÉ „C „END Demo1, IIF (DepartmentID IN (1,2),„ A “, IIF (DepartmentID = 3, CASE PositionID KDY 3 POTOM„ B-1 “KDY 4 POTOM„ B-2 “END,„ C “)) Demo2 OD zaměstnanců Protože konstrukce CASE a IIF jsou výrazy, které vracejí výsledek, můžeme je použít nejen v bloku SELECT, ale také v jiných blocích, které umožňují použití výrazů, například v klauzulích WHERE nebo ORDER BY. Například nám bude svěřen úkol vytvořit seznam pro rozdávání platů, a to následovně:
Pokusme se tento problém vyřešit přidáním výrazu CASE do bloku ORDER BY: VYBERTE ID, jméno, plat od zaměstnanců OBJEDNÁVKA PODLE PŘÍPADU, KDYŽ Plat> = 2500 POTOM 1 JINÉ 0 KONEC, - nejdříve vystavte plat těm, kteří jej mají pod 2500 Jméno - dále seřaďte seznam v pořadí podle celého jména A abstraktní příklad použití CASE v klauzuli WHERE: VYBERTE ID, jméno, plat OD zaměstnanců, KDE PŘÍPAD KDYŽ plat> = 2500 PAK 1 JINÉ 0 KONEC = 1 - všechny záznamy s výrazem rovným 1 Můžete se pokusit zopakovat poslední 2 příklady pomocí funkce IIF sami. A nakonec si znovu připomeňme hodnoty NULL: VYBERTE ID, jméno, plat, ID oddělení, PŘÍPAD KDY DepartmentID = 2 POTOM „10%“ - 10% z platu, který bude vystaven účetním KDY DepartmentID = 3 POTOM „15%“ - vydat 15% platu zaměstnancům IT KDY DepartmentID JE NULL POTOM "-" - nedáváme bonusy nezávislým pracovníkům (používáme IS NULL) JINÉ "5%" - všichni ostatní mají po 5% KONEC NewYearBonusPercent1, - ale nemůžete zkontrolovat NULL, pamatujte si, co bylo o NULL řečeno ve druhé části CASE DepartmentID - - zkontrolovaná hodnota KDY 2 POTOM „10%“ KDY 3 POTOM „15%“ KDY NULL POTOM “-„ - !!! v tomto případě použití druhého CASE formuláře není vhodné JINÉ "5%" KONEC NewYearBonusPercent2 OD zaměstnanců VYBERTE ID, jméno, plat, ID oddělení, CASE ISNULL (DepartmentID, -1) - použijte náhradu v případě NULL o -1 KDYŽ 2 POTOM "10%" KDY 3 POTOM "15%" KDY -1 POTOM "-" - pokud jsme si jisti, že neexistuje žádné oddělení s ID rovným (-1) a NEBUDE JINÉ "5%" KONEC NewYearBonusPercent3 OD zaměstnanců Obecně platí, že let představivosti v tomto případě není omezen. Podívejme se například, jak lze funkci ISNULL modelovat pomocí CASE a IIF: VYBERTE ID, Jméno, Příjmení, ISNULL (Příjmení, "Nespecifikováno") DemoISNULL, PŘÍPAD, KDY JE Příjmení NULL POTOM "Nespecifikováno" JINÉ Příjmení KONEC DemoCASE, IIF (Příjmení JE NULL, "Nespecifikováno", Příjmení) DemoIIF OD zaměstnanců Konstrukce CASE je velmi výkonná funkce SQL, která umožňuje uložit další logiku pro výpočet hodnot sady výsledků. V této části bude vlastnictví konstrukce CASE pro nás stále užitečné, proto je v této části především věnována pozornost. Souhrnné funkceZde budeme uvažovat pouze o základních a nejčastěji používaných agregačních funkcích:
Agregační funkce nám umožňují vypočítat celkovou hodnotu pro sadu řádků získaných pomocí příkazu SELECT. Podívejme se na každou funkci s příkladem: VYBERTE POČET (*) [Celkový počet zaměstnanců], POČET (DISTINCT DepartmentID) [Počet jedinečných oddělení], POČET (DISTINCTID pozice) [Počet jedinečných pozic], POČET (BonusPercent) [Počet zaměstnanců s% bonusem], MAX (BonusPercent) [maximální procento bonusu], MIN (BonusPercent) [minimální procento bonusu], SUM (plat / 100 * BonusPercent) [součet všech bonusů], AVG (plat / 100 * BonusPercent) [průměrná velikost bonusu], AVG ( Plat) [Průměrný plat] OD zaměstnanců Pojďme se podívat na to, jak každá návratová hodnota vznikla, a zaprvé si připomeňme konstrukce základní syntaxe příkazu SELECT. Nejprve proto v dotazu jsme nezadali WHERE podmínky, pak se vypočítají součty pro podrobná data získaná dotazem: VYBERTE * OD zaměstnanců Ty. pro všechny řádky tabulky Zaměstnanci. Pro přehlednost vybereme pouze pole a výrazy, které se používají v agregačních funkcích: VYBERTE ID oddělení, ID pozice, BonusPercent, plat / 100 * BonusPercent, plat od zaměstnanců
Toto jsou počáteční data (podrobné řádky), podle kterých se vypočítají součty agregovaného dotazu. Nyní se podívejme na každou agregovanou hodnotu:
Shrňme některé z výsledků:
V souladu s tím se při nastavení další podmínky s agregačními funkcemi v klauzuli WHERE počítají pouze součty pro řádky, které splňují podmínku. Ty. výpočet agregovaných hodnot se provádí pro celkovou množinu, která se získá pomocí konstrukce SELECT. Udělejme například všechno stejně, ale pouze v kontextu IT oddělení: VYBERTE POČET (*) [Celkový počet zaměstnanců], POČET (DISTINCT DepartmentID) [Počet jedinečných oddělení], POČET (DISTINCTID pozice) [Počet jedinečných pozic], POČET (BonusPercent) [Počet zaměstnanců s% bonusem], MAX (BonusPercent) [maximální procento bonusu], MIN (BonusPercent) [minimální procento bonusu], SUM (plat / 100 * BonusPercent) [součet všech bonusů], AVG (plat / 100 * BonusPercent) [průměrná velikost bonusu], AVG ( Plat) [Průměrný plat] OD zaměstnanců WHERE DepartmentID = 3 - Zvažte pouze oddělení IT VYBERTE ID oddělení, ID pozice, BonusPercent, plat / 100 * BonusPercent, plat OD zaměstnanců WHERE DepartmentID = 3 - zahrňte pouze oddělení IT
Pokračuj. Pokud agregační funkce vrací NULL (například všichni zaměstnanci nemají hodnotu Plat), nebo nebyl do výběru zahrnut jediný záznam a v sestavě musíme v takovém případě ukázat 0, pak funkce ISNULL může zabalit agregovaný výraz: VYBRAT SUM (plat), AVG (plat), - zpracovat součet pomocí ISNULL ISNULL (SUM (plat), 0), ISNULL (AVG (plat), 0) OD zaměstnanců WHERE DepartmentID = 10 - neexistující oddělení je speciálně zde uvedeno, aby se zabránilo dotazu v návratu záznamů
Věřím, že je velmi důležité pochopit účel každé agregační funkce a jak ji vypočítat, protože v SQL je to hlavní nástroj pro výpočet součtů. V tomto případě jsme zkoumali, jak se každá agregační funkce chová nezávisle, tj. bylo aplikováno na hodnoty celé sady záznamů získané příkazem SELECT. Dále se podíváme na to, jak se tyto stejné funkce používají k výpočtu celkových skupin pomocí klauzule GROUP BY. GROUP BY - seskupení datPřed tím jsme již vypočítali součty pro konkrétní oddělení, zhruba takto:VYBERTE POČET (DISTINCT ID pozice) PositionCount, COUNT (*) EmplCount, SUMA (plat) SalaryAmount OD zaměstnanců WHERE DepartmentID = 3 - data pouze pro IT oddělení Nyní si představte, že jsme byli požádáni, abychom získali stejné údaje v kontextu každého oddělení. Samozřejmě si můžeme vyhrnout rukávy a splnit stejný požadavek pro každé oddělení. Takže hned, než to uděláme, napíšeme 4 žádosti: VYBERTE "Správa" Informace, POČET (DISTINCT ID pozice) PositionCount, POČET (*) EmplCount, SUM (Plat) SalaryAmount OD zaměstnanců WHERE DepartmentID = 1 - údaje o správě VYBERTE "Informace o účetnictví", POČET (DISTINCT PositionID) PositionCount, POČET (* ) EmplCount, SUM (plat) SalaryAmount FROM zaměstnanců WHERE DepartmentID = 2 - účetní data VYBRAT „IT“ informace, POČET (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (plat) SalaryAmount OD zaměstnanců WHERE DepartmentID = 3 - údaje o IT oddělení VYBERTE „Jiné“ informace, POČET (DISTINCTID pozice), POČET POČET, POČET (*) EmplCount, SUM (plat) SalaryAmount OD zaměstnanců, KDE JE ID ODDĚLENÍ NULL - a nezapomeňte na údaje o nezávislých Ve výsledku získáme 4 datové sady:
Vezměte prosím na vědomí, že můžeme použít pole uvedená jako konstanty - „Správa“, „Účetnictví“, ... Obecně jsme extrahovali všechna čísla, která byla od nás požadována, vše kombinujeme v aplikaci Excel a dáme to řediteli. Ředitelovi se zpráva líbila a říká: „a přidejte další sloupec s informacemi o průměrném platu.“ A jako vždy je třeba to udělat velmi naléhavě. Hmm, co dělat?! Navíc si představme, že naše oddělení nejsou 3, ale 15. Přesně to je klauzule GROUP BY pro takové případy: VYBERTE DepartmentID, COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (Salary) SalaryAmount, AVG (Salary) SalaryAvg - plus plníme přání ředitele FROM Zaměstnanci SKUPINA PODLE DepartmentID
Získali jsme všechna stejná data, ale nyní používáme pouze jeden požadavek! Zatím nevěnujte pozornost tomu, že se naše oddělení zobrazují ve formě čísel, pak se naučíme, jak vše krásně zobrazit. V klauzuli GROUP BY můžete zadat několik polí "GROUP BY pole1, pole2, ..., poleN", v tomto případě dojde ke seskupení podle skupin, které tvoří hodnoty těchto polí "pole1, pole2, .. ., poleN ". Pojďme například seskupit data podle oddělení a pozic: VYBERTE ID oddělení, ID pozice, POČET (*) EmplCount, SUMA (plat) SalaryAmount OD zaměstnanců SKUPINU PODLE ID oddělení, ID pozice VYBERTE POČET (*) EmplCount, SUM (plat) SalaryAmount FROM zaměstnanců KDE JE IDENTIFIKÁTOR NULL A PositionID JE NULL VYBERTE POČET (*) EmplCount, SUM (plat) SalaryAmount FROM zaměstnanců KDE JE IDENTIFIKÁTOR = 1 A PositionID = 2 - ... VYBERTE POČET (*) EmplCount, SUM (plat) SalaryAmount OD zaměstnanců WHERE DepartmentID = 3 AND PositionID = 4 A pak jsou všechny tyto výsledky spojeny dohromady a dány nám jako jednu sadu:
Z hlavní stojí za zmínku, že v případě seskupení (GROUP BY) v seznamu sloupců v bloku SELECT:
A ukázka všeho, co bylo řečeno: VYBERTE "Stringová konstanta" Const1, - konstanta ve formě řetězce 1 Const2, - konstanta ve formě čísla - výraz pomocí polí účastnících se ve skupině CONCAT ("Číslo oddělení", DepartmentID) ConstAndGroupField, CONCAT ("Oddělení Č. ", DepartmentID,", číslo pozice ", PositionID) ConstAndGroupFields, DepartmentID, - pole ze seznamu polí účastnících se seskupení - PositionID, - pole účastnící se seskupení, zde není nutné duplikovat COUNT ( *) EmplCount, - počet řádků v každé skupině - zbytek polí lze použít pouze s agregačními funkcemi: COUNT, SUM, MIN, MAX,… SUM (plat) SalaryAmount, MIN (ID) MINID OD zaměstnanců SKUPINU PODLE DepartmentID , PositionID - seskupení podle polí DepartmentID, PositionID Za zmínku stojí také to, že seskupování lze provést nejen podle polí, ale také podle výrazů. Pojďme například seskupit data podle zaměstnanců podle roku narození: VÝBĚR KONCATU ("Rok narození -", ROK (Narozeniny)) YearOfBirthday, POČET (*) EmplCount OD zaměstnanců SKUPINA DO ROKU (Narozeniny) Podívejme se na příklad se složitějším výrazem. Pojďme například získat hodnocení zaměstnanců podle roku narození: VYBERTE PŘÍPAD KDY ROK (Narozeniny)> = 2000 PAK "od roku 2000" KDY ROK (Narozeniny)> = 1990 POTOM "1999-1990" KDY ROK (Narozeniny)> = 1980 POTOM "1989-1980" KDY ROK (Narozeniny)> = 1970 POTOM „1979-1970“ KDY NAROZENINY NENÍ NULOVÁ “před 1970„ ELSE “nespecifikováno„ END RangeName, COUNT (*) EmplCount OD zaměstnanců SKUPINA PODLE PŘÍPADŮ KDY ROK (Narozeniny)> = 2000 POTOM “od roku 2000„ KDY ROK (Narozeniny)> = 1990 PAK "1999-1990" KDY ROK (Narozeniny)> = 1980 PAK "1989-1980" KDY ROK (Narozeniny)> = 1970 POTOM "1979-1970" KDY NARODENINY NENÍ NULL PAK "před rokem 1970" JINÉ „nespecifikováno“ KONEC
Ty. v tomto případě se seskupení provádí podle výrazu CASE, který byl dříve vypočítán pro každého zaměstnance: VYBERTE ID, PŘÍPAD KDY ROK (Narozeniny)> = 2000 PAK "od roku 2000" KDY ROK (Narozeniny)> = 1990 POTOM "1999-1990" KDY ROK (Narozeniny)> = 1980 POTOM "1989-1980" KDY ROK (Narozeniny) > = 1970 PAK
A samozřejmě můžete kombinovat výrazy s poli v bloku GROUP BY: SELECT DepartmentID, CONCAT ("Rok narození -", YEAR (Narozeniny)) YearOfBirthday, COUNT (*) EmplCount OD zaměstnanců SKUPINOVĚ DO ROKU (Narozeniny), DepartmentID - objednávka se nemusí shodovat s objednávkou jejich použití ve VÝBĚRU OBJEDNÁVKY BY DepartmentID block, YearOfBirthday - konečně můžeme na výsledek použít třídění Vraťme se k původnímu úkolu. Jak již víme, řediteli se zpráva velmi líbila a požádal nás, abychom to dělali každý týden, aby mohl sledovat změny ve společnosti. Abychom nepřerušili pokaždé v aplikaci Excel číselnou hodnotu oddělení jménem, použijeme znalosti, které již máme, a vylepšíme náš dotaz: VYBERTE CASE DepartmentID KDY 1 POTOM „Správa“ KDY 2 POTOM „Účetnictví“ KDY 3 POTOM „TO“ JINÉ „Jiné“ KONEC Info, POČET (DISTINCTID pozice) PositionCount, POČET (*) EmplCount, SUM (plat) SalaryAmount, AVG (plat ) SalaryAvg - plus plníme přání ředitele OD OD zaměstnanců SKUPINA PODLE ODDĚLENÍ OBJEDNÁVKA PODLE INFORMACE - pro větší pohodlí přidejte řazení podle sloupce Informace Ale nic se časem naučíme dělat všechno krásně, aby náš vzorek nezávisel na vzhledu nových dat v databázi, ale byl dynamický. Půjdu trochu dopředu, abych ukázal, jaké požadavky se snažíme přijít: VYBERTE ISNULL (dep.Name, "Other") DepName, COUNT (DISTINCT emp.PositionID) PositionCount, COUNT (*) EmplCount, SUM (emp.Salary) SalaryAmount, AVG (emp.Salary) SalaryAvg - plus splňte přání ředitel FROM Zaměstnanci emp LEFT JOIN Departments dep ON emp.DepartmentID = dep.ID GROUP BY emp.DepartmentID, dep.Name ORDER BY DepName Obecně se nebojte - každý začal jednoduše. Prozatím stačí pochopit podstatu klauzule GROUP BY. Nakonec se podívejme, jak můžete vytvářet souhrnné sestavy pomocí GROUP BY. Například si v kontextu oddělení zobrazíme kontingenční tabulku, takže se vypočítá celková mzda, kterou zaměstnanci dostanou podle pozice: VYBERTE ID oddělení, SUM (PŘÍPAD, KDY PositionID = 1 POTOM KONEC platu) [Účetní], SUM (PŘÍPAD, KDY PositionID = 2 POTOM KONEC platu) [Ředitelé], SUM (PŘÍPAD, KDY PositionID = 3 POTOM KONEC platu) [Programátoři], SUM ( PŘÍPAD KDYŽ ID pozice = 4 POTOM KONEC platu) [Senior Programmers], SUM (Plat) [Oddělení celkem] OD zaměstnanců SKUPINU PODLE Oddělení Můžete je samozřejmě přepsat pomocí IIF: VÝBĚR DepartmentID, SUMA (IIF (PositionID = 1, plat, NULL)) [účetní], SUM (IIF (PositionID = 2, plat, NULL)) [ředitelé], SUM (IIF (PositionID = 3, plat, NULL)) [Programátoři], SUM (IIF (PositionID = 4, Plat, NULL)) [Senior Programmers], SUM (Plat) [Oddělení celkem] OD zaměstnanců SKUPINU PODLE ODDĚLENÍ Ale v případě IIF musíme explicitně zadat NULL, který se vrátí, pokud podmínka není splněna. V podobných případech dávám přednost použití CASE bez bloku ELSE, než znovu zapsat NULL. Ale to je určitě věc vkusu, o které se nediskutuje. A pamatujme, že hodnoty NULL nejsou v agregačních funkcích brány v úvahu. Chcete-li konsolidovat, proveďte nezávislou analýzu dat získaných rozšířeným požadavkem: VYBERTE ID oddělení, PŘÍPAD KDY Pozice ID = 1 POTOM KONEC platu [Účetní], PŘÍPAD KDY Pozice ID = 2 POTOM KONEC platu [Ředitelé], PŘÍPAD KDY Pozice ID = 3 POTOM KONEC platu [Programátoři], PŘÍPAD KDY Pozice ID = 4 POTOM KONEC platu [Senior Programátoři ], Plat [Oddělení celkem] OD zaměstnanců
A také si zapamatujme, že pokud místo NULL chceme vidět nuly, můžeme zpracovat hodnotu vrácenou agregační funkcí. Například: VYBERTE ID oddělení, ISNULL (SUM (IIF (PositionID = 1, plat, NULL)), 0) [účetní], ISNULL (SUM (IIF (PositionID = 2, plat, NULL)), 0) [ředitelé], ISNULL (SUM (IIF (PositionID = 3, plat, NULL)), 0) [programátoři], ISNULL (SUM (IIF (PositionID = 4, plat, NULL)), 0) [starší programátoři], ISNULL (SUM (plat), 0) ) [Oddělení celkem] OD zaměstnanců SKUPINU PODLE ID oddělení
SKUPINA BY v řídkých agregačních funkcích, jeden z hlavních nástrojů používaných k získání souhrnných dat z databáze, protože data se obvykle používají v této formě, protože obvykle jsme povinni poskytovat spíše souhrnné zprávy než podrobné údaje (listy). A samozřejmě se to všechno točí kolem znalosti základního designu, protože než něco shrnete (agregujete), musíte to nejprve správně vybrat pomocí „VYBRAT ... KDE ...“. Praxe zde hraje důležitou roli, a proto, pokud si stanovíte cíl porozumět jazyku SQL, ne naučit se, ale porozumět - procvičovat, procvičovat a procvičovat, procházet nejrůznějšími možnostmi, které vás napadnou. Pokud si v počáteční fázi nejste jisti správností získaných agregovaných dat, vytvořte podrobný vzorek, včetně všech hodnot, pro které agregace probíhá. A pomocí těchto podrobných údajů zkontrolujte správnost výpočtů ručně. V tomto případě může být použití aplikace Excel velmi užitečné. Řekněme, že jste se dostali do tohoto boduŘekněme, že jste účetní S. S. Sidorov, který se rozhodl naučit se psát dotazy SELECT.Řekněme, že jste tento tutoriál dočetli až do tohoto okamžiku a už s jistotou používáte všechny výše uvedené základní konstrukce, tj. můžeš:
Ano, ale nezohlednili, že ještě nemůžete vytvářet dotazy z několika tabulek, ale pouze z jedné, tj. nevíš, jak něco takového udělat: VYBRAT emp. *, - vrátit všechna pole tabulky Zaměstnanci dep. Název DepartmentName, - přidat pole Název z tabulky Departments poz. Název Pozice Název do těchto polí - a také přidat pole Název z tabulky Pozice Z FROM Zaměstnanci emp LEVÉ PŘIPOJENÍ Departments dep ON emp.DepartmentID = dep.ID LEFT JOIN Pozice pos ON ON emp.PositionID = poz.ID Jak tedy můžete využít své současné znalosti a dosáhnout ještě produktivnějších výsledků současně?! Využijeme sílu kolektivní mysli - půjdeme k programátorům, kteří pro vás pracují, tj. Andreev A.A., Petrov P.P. nebo Nikolayev N.N. a požádejte jednoho z nich, aby vám napsal pohled (VIEW nebo jednoduše „View“, aby vám dokonce rychleji porozuměl), který kromě hlavních polí z tabulky Zaměstnanci vrátí také pole s „Název oddělení“ a „Název pozice“, které vám teď tak chybí pro týdenní report, který vám Ivanov II nahrál. Protože vysvětlili jste vše správně, pak IT specialisté okamžitě pochopili, co od nich chtějí, a vytvořili, speciálně pro vás, pohled s názvem ViewEmployeesInfo. Prohlašujeme, že další příkaz nevidíte, protože IT specialisté to dělají: VYTVOŘIT ZOBRAZENÍ ViewEmployeesInfo AS SELECT emp. *, - vrátit všechna pole tabulky Zaměstnanci dep. Název DepartmentName, - přidat do těchto polí pole Název z tabulky Oddělení Název pozice Název - a také přidat pole Název z tabulky Pozice OD Emp Employment LEFT JOIN Departments dep ON emp.DepartmentID = dep.ID LEFT JOIN Positions pos ON ON emp.PositionID = pos.ID Ty. pro vás to všechno, i když děsivé a nepochopitelné, text zůstává v zákulisí a IT specialisté vám poskytnou pouze název pohledu „ViewEmployeesInfo“, který vrací všechna výše uvedená data (tj. to, o co jste je požádali). S tímto pohledem nyní můžete pracovat jako s běžnou tabulkou: VYBERTE * Z FROM ViewEmployeesInfo VYBRAT DepartmentName, COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (plat) SalaryAmount, AVG (plat) SalaryAvg FROM ViewEmployeesInfo emp GROUP BY DepartmentID, DepartmentName ORDER BY DepartmentName Ty. pro vás v tomto případě, jako by se nic nezměnilo, budete pokračovat v práci s jednou tabulkou stejným způsobem (ale správnější je to říci v pohledu ViewEmployeesInfo), která vrátí všechna data, která potřebujete. Díky pomoci IT specialistů pro vás podrobnosti těžby DepartmentName a PositionName zůstávají v černé skříňce. Ty. pohled pro vás vypadá stejně jako běžná tabulka, považujte ji za rozšířenou verzi tabulky Zaměstnanci. Například vytvořme prohlášení jako příklad, abyste se ujistili, že vše je opravdu tak, jak jsem řekl (že celý vzorek pochází z jednoho pohledu): VYBERTE ID, jméno, plat FROM ViewEmployeesInfo KDE PLAT NENÍ NULL A plat> 0 OBJEDNAT PODLE JMÉNA Použití pohledů v některých případech umožňuje výrazně rozšířit hranice uživatelů, kteří vědí, jak psát základní dotazy SELECT. V tomto případě je to pohled plochá tabulka se všemi daty, která uživatel potřebuje (pro ty, kteří rozumějí OLAP, to lze přirovnat k aproximaci krychle OLAP s fakty a dimenzemi). Výřez z Wikipedie. Ačkoli byl SQL koncipován jako nástroj pro koncového uživatele, nakonec se stal tak složitým, že se stal nástrojem programátora. Jak vidíte, vážení uživatelé, jazyk SQL byl původně koncipován jako nástroj pro vás. Takže vše je ve vašich rukou a touze, nepouštějte to. HAVING - uložení podmínky výběru seskupeným datůmVe skutečnosti, pokud rozumíte tomu, co je seskupení, není s HAVINGEM nic složitého. HAVING je poněkud podobný WHERE, pouze pokud je podmínka WHERE aplikována na podrobná data, pak je podmínka HAVING použita na již seskupená data. Z tohoto důvodu můžeme v podmínkách bloku HAVING použít buď výrazy s poli zahrnutými do seskupení, nebo výrazy uzavřené v agregačních funkcích.Zvažme příklad: VYBERTE ID oddělení, SUM (plat) Mzda částka od SKUPINY PODLE ODDÍLŮ MÁ SUM (plat)> 3000
Ty. Tento požadavek nám vrátil seskupené údaje pouze za ta oddělení, u nichž celkový plat všech zaměstnanců přesahuje 3000, tj. „SUM (plat)> 3000“.
Ty. zde nejdříve proběhne seskupení a vypočítají se údaje za všechna oddělení: VYBERTE ID oddělení, SUM (plat) SalaryAmount FROM zaměstnanců SKUPINU PODLE ID oddělení - 1. získejte seskupená data pro všechna oddělení Na tato data je již použita podmínka uvedená v bloku HAVING: VYBERTE ID oddělení, SUM (plat) SalaryAmount FROM zaměstnanců SKUPIT PODLE DepartmentID - 1. získejte seskupená data pro všechna oddělení MÁ SUM (plat)> 3000 - 2. podmínka pro filtrování seskupených dat Ve stavu HAVING můžete také vytvořit složité podmínky pomocí operátorů AND, OR a NOT: VYBERTE ID oddělení, SUM (plat) SalaryAmount FROM zaměstnanců SKUPINU PODLE DepartmentID HAVING SUM (plat)> 3000 A POČET (*)<2 -- и число людей меньше 2-х
Jak vidíte zde, agregační funkci (viz „POČET (*)“) lze zadat pouze v bloku HAVING. Podle toho můžeme zobrazit pouze číslo oddělení, které odpovídá podmínce HAVING: VYBERTE ID oddělení OD zaměstnanců SKUPINU PODLE JEDNOTEK ODDĚLENÍ SEM (plat)> 3000 A POČET (*)<2 -- и число людей меньше 2-х Příklad použití podmínky HAVING na poli zahrnutém do GROUP BY: VYBERTE ID oddělení, SUM (plat) SalaryAmount FROM zaměstnanců SKUPINU PODLE DepartmentID - 1. proveďte seskupení HAVING DepartmentID = 3 - 2. filtrujte výsledek seskupení Toto je jen příklad, protože v tomto případě by bylo logičtější zkontrolovat podmínku WHERE: VYBERTE ID oddělení, SUM (plat) SalaryAmount OD zaměstnanců WHERE DepartmentID = 3 - 1. filtrovat podrobná data SKUPINU PODLE DepartmentID - 2. vytvořit seskupení pouze podle vybraných záznamů Ty. nejprve filtrujte zaměstnance podle oddělení 3 a teprve poté proveďte výpočet. Poznámka. Ve skutečnosti, i když tyto dva dotazy vypadají odlišně, optimalizátor DBMS je může provádět stejným způsobem. Myslím, že tím končí příběh o HAVINGOVÝCH podmínkách. Pojďme to shrnoutShrňme data získaná ve druhé a třetí části a zvažte konkrétní umístění každé struktury, kterou jsme studovali, a označme pořadí jejich implementace:
Samozřejmě můžete také použít seskupené údaje klauzule DISTINCT a TOP, které jste se naučili v druhé části. Tyto návrhy se v tomto případě vztahují na konečný výsledek: VYBERTE NEJLEPŠÍ 1 - 6. použije poslední SUM (plat) SalaryAmount FROM zaměstnanců SKUPINA PODLE DepartmentID MÁ SUM (plat)> 3000 OBJEDNAT PODLE DepartmentID - 5. roztřídit výsledek Analyzujte, jak byly tyto výsledky získány sami. ZávěrHlavním cílem, který jsem si v této části stanovil, je odhalit pro vás podstatu agregačních funkcí a seskupení.Pokud nám základní design umožnil získat potřebná podrobná data, aplikace agregačních funkcí a seskupení na tato podrobná data nám poskytla příležitost získat o nich souhrnná data. Jak tedy vidíte, vše je zde důležité, tk. jeden je založen na druhém - bez znalosti základní struktury nebudeme schopni například správně vybrat data, pro která potřebujeme vypočítat součty. Zde se záměrně snažím ukázat pouze základy, abych soustředil pozornost začátečníka na nejdůležitější struktury a nepřetěžoval je zbytečnými informacemi. Solidní porozumění základním strukturám (o kterých budu dále hovořit v dalších částech) vám dá příležitost vyřešit téměř jakýkoli problém načítání dat z RDB. Základní konstrukce příkazu SELECT jsou použitelné ve stejné formě téměř ve všech DBMS (rozdíly spočívají hlavně v detailech, například v implementaci funkcí - pro práci s řetězci, čas atd.). Následná solidní znalost základny vám dá příležitost snadno se samostatně naučit různá rozšíření jazyka SQL, například:
Pokud provádíte své první kroky v SQL, nejprve se zaměřte na učení základních konstrukcí. když vlastníte základnu, vše ostatní vám bude mnohem snazší pochopit, a kromě toho na vlastní pěst. Nejprve musíte do hloubky porozumět schopnostem jazyka SQL, tj. jaký druh operace obecně umožňuje provádět na datech. Předávat informace začátečníkům v objemné formě je dalším z důvodů, proč ukážu jen ty nejdůležitější (železné) struktury. Hodně štěstí při učení a porozumění jazyku SQL. Část čtvrtá - tým CASE vám umožní vybrat si jeden z více příkazových sekvencí... Tento konstrukt je ve standardu SQL přítomen od roku 1992, ačkoli nebyl podporován v Oracle SQL až do Oracle8i a v PL / SQL do Oracle9i Release 1. Počínaje touto verzí jsou podporovány následující varianty příkazů CASE:
NULL nebo UNKNOWN?V článku o příkazu IF jste se možná dozvěděli, že výsledek logického výrazu může být TRUE, FALSE nebo NULL. V PL / SQL je to pravda, ale v širším kontextu relační teorie se považuje za nesprávné hovořit o návratu NULL z booleovského výrazu. Relační teorie říká, že srovnání s NULL jsou taková: 2 < NULL dává logický výsledek NEZNÁMÝ a UNKNOWN není NULL. Neměli byste se však příliš starat o to, jak PL / SQL používá NULL pro NEZNÁMÉ. Měli byste si však být vědomi, že třetí hodnota v logice se 3 hodnotami je NEZNÁMÁ. A doufám, že se nikdy (jak jsem to udělal!) Při diskusi o 3hodnotové logice s odborníky v oblasti relační teorie nechytíte do nesprávného termínu. Kromě příkazů CASE podporuje PL / SQL také výrazy CASE. Tento výraz je velmi podobný příkazu CASE, umožňuje vybrat jeden nebo více výrazů pro vyhodnocení. Výsledkem výrazu CASE je jedna hodnota, zatímco výsledkem příkazu CASE je provedení posloupnosti příkazů PL / SQL. Jednoduché příkazy CASEJednoduchý příkaz CASE umožňuje vybrat jednu z několika sekvencí příkazů PL / SQL, které se mají provést na základě výsledku vyhodnocení výrazu. Je napsán takto: CASE výraz KDY result_1 PAK příkaz_1 KDY result_2 THEN command_2 ... ELSE command_else END CASE; Pobočka ELSE je zde volitelná. Při provádění takového příkazu PL / SQL nejprve vyhodnotí výraz a poté porovná výsledek s výsledkem_1. Pokud se shodují, budou provedeny příkazy_1. Jinak se zkontroluje hodnota result_2 atd. Zde je příklad jednoduchého příkazu CASE, ve kterém se bonus počítá v závislosti na hodnotě proměnné employee_type: PŘÍPAD zaměstnanec_typ KDY „S“ POTOM award_salary_bonus (employee_id); KDY „H“ POTOM award_hourly_bonus (employee_id); KDY „C“ POTOM award_commissioned_bonus (employee_id); ELSE RAISE invalid_employee_type; KONEC PŘÍPADU; V tomto příkladu existuje explicitní klauzule ELSE, ale obecně se nevyžaduje. Bez klauzule ELSE kompilátor PL / SQL implicitně nahrazuje následující kód: ELSE RAISE CASE_NOT_FOUND; Jinými slovy, pokud nezadáte klíčové slovo ELSE a pokud žádný z výsledků v klauzulích WHEN neodpovídá výsledku výrazu v příkazu CASE, vyvolá PL / SQL výjimku CASE_NOT_FOUND. To je rozdíl mezi tímto příkazem a IF. Když klíčové slovo ELSE v příkazu IF chybí, nic se nestane, pokud podmínka není splněna, zatímco v příkazu CASE vede podobná situace k chybě. Bude zajímavé sledovat, jak implementovat logiku výpočtu bonusu popsanou na začátku kapitoly pomocí jednoduchého příkazu CASE. Na první pohled se to zdá nemožné, ale kreativně se pustit do podnikání, přicházíme k následujícímu řešení: PŘÍPAD PRAVDA, KDY plat> = 10 000 A plat<=20000 THEN give_bonus(employee_id, 1500); WHEN salary >20 000 A plat<= 40000 THEN give_bonus(employee_id, 1000); WHEN salary >40000 THEN give_bonus (employee_id, 500); JINÉ give_bonus (employee_id, 0); KONEC PŘÍPADU; Důležité je, že prvky výrazu a výsledku mohou být buď skalární hodnoty, nebo výrazy, jejichž výsledky jsou skalární hodnoty. Po návratu k příkazu IF ... THEN ... ELSIF, který implementuje stejnou logiku, uvidíte, že část ELSE je definována v příkazu CASE, zatímco klíčové slovo ELSE chybí v příkazu IF - THEN - ELSIF. Důvod přidání ELSE je jednoduchý: pokud nejsou splněny žádné podmínky bonusu, příkaz IF nedělá nic a bonus je nulový. V tomto případě příkaz CASE generuje chybu, takže situace s nulovou prémií musí být naprogramována explicitně. Chcete-li zabránit chybám CASE_NOT_FOUND, ujistěte se, že u jakékoli hodnoty testovaného výrazu bude splněna alespoň jedna z podmínek. Výše uvedený příkaz CASE TRUE může pro některé znít jako trik, ale ve skutečnosti implementuje pouze vyhledávací příkaz CASE, o kterém si povíme v další části. Příkaz hledání CASEPříkaz CASE prohledá seznam booleovských výrazů; po nalezení výrazu rovného TRUE provede sekvenci přidružených příkazů. Příkaz CASE search je v podstatě analogický s příkazem CASE TRUE zobrazeným v předchozí části. Příkaz CASE search má následující zápis: PŘÍPAD KDY výraz_1 POTOM příkaz1 KDY výraz_2 PAK příkaz_2 ... JINÝ příkaz_else KONEC PŘÍPADU; Je ideální pro implementaci logiky přírůstku bonusu: PŘÍPAD KDYŽ plat> = 10 000 A plat<=20000 THEN give_bonus(employee_id, 1500); WHEN salary >20 000 A plat<= 40000 THEN give_bonus(employee_id, 1000); WHEN salary >40000 THEN give_bonus (employee_id, 500); JINÉ give_bonus (employee_id, 0); KONEC PŘÍPADU; Vyhledávací příkaz CASE se stejně jako jednoduchý příkaz řídí následujícími pravidly:
Zvažte další implementaci logiky výpočtu bonusu, která využívá skutečnosti, že KDY jsou podmínky kontrolovány v pořadí, ve kterém jsou zapsány. Jednotlivé výrazy jsou jednodušší, ale můžeme říci, že význam celého příkazu je jasnější? PŘÍPAD, KDY plat> 40000 POTOM give_bonus (employee_id, 500); KDY plat> 20000 POTOM give_bonus (employee_id, 1000); KDY plat> = 10 000 POTOM give_bonus (employee_id, 1500); JINÉ give_bonus (employee_id, 0); KONEC PŘÍPADU; Pokud má určitý zaměstnanec plat 20 000, jsou první dvě podmínky NEPRAVDA a třetí je PRAVDA, takže zaměstnanec obdrží bonus 1 500 USD. Pokud je plat 21 000, bude výsledek druhé podmínky TRUE a bonus bude 1 000 $. Provádění příkazu CASE bude ukončeno na druhé větvi WHEN a třetí podmínka nebude ani zkontrolována. To, zda by měl být tento přístup použit při psaní příkazů CASE, je diskutabilní. Ať je to jakkoli, mějte na paměti, že je možné takový příkaz napsat, a při ladění a úpravách programů, ve kterých výsledek závisí na pořadí výrazů, je nutná zvláštní péče. Logika, která závisí na uspořádání homogenních větví KDYŽ je potenciálním zdrojem chyb vyplývajících z jejich přeskupení. Jako příklad zvažte následující příkaz CASE lookup, ve kterém s platem 20 000 bude test stavu v obou klauzulích WHEN vyhodnocen na TRUE: PŘÍPAD, KDYŽ plat MEZI 10 000 A 20 000 POTOM give_bonus (employee_id, 1500); KDY mzda MEZI 20000 A 40000 POTOM give_bonus (employee_id, 1000); ... Představte si, jak správce tohoto programu uštěpačně přeuspořádává klauzule KDY, aby jim nařídil sestupný platový řád. Nezavrhujte tuto možnost! Programátoři mají často tendenci „vylepšovat“ krásně fungující kód na základě jakési interní objednávky. Příkaz CASE s přeuspořádanými klauzulemi KDY vypadá takto: PŘÍPAD KDY plat mezitím 20000 A 40000 POTOM give_bonus (employee_id, 1000); KDY mzda MEZI 10000 A 20000 POTOM give_bonus (employee_id, 1500); ... Na první pohled je vše v pořádku, že? Bohužel v důsledku překrývání dvou větví WHEN se v programu objeví zákeřná chyba. Zaměstnanec s platem 20 000 nyní obdrží bonus 1 000 místo požadovaných 1 500. V některých situacích může být žádoucí překrývat se mezi KDYŽ pobočkami, ale pokud je to možné, měli byste se mu stále vyhýbat. Vždy pamatujte, že pořadí větví je důležité, a omezte nutkání upravit již fungující kód - „neopravujte, co není rozbité“. Vzhledem k tomu, že když jsou podmínky testovány v pořadí, můžete mírně zlepšit účinnost svého kódu umístěním větví s nejpravděpodobnějšími podmínkami na začátek seznamu. Kromě toho, pokud máte větev s „drahými“ výrazy (například vyžadující značný čas a paměť procesoru), můžete je umístit na konec, abyste minimalizovali pravděpodobnost jejich testování. Podrobnosti najdete v části Vnořené příkazy IF. Příkazy hledání CASE se používají, když jsou příkazy, které mají být provedeny, definovány sadou logických výrazů. Jednoduchý příkaz CASE se používá, když se rozhoduje na základě výsledku jediného výrazu.
Vnořené příkazy CASEPříkazy CASE, stejně jako příkazy IF, lze vnořit. Například vnořený příkaz CASE se objeví v následující (poněkud matoucí) implementaci bonusové logiky: PŘÍPAD KDYŽ plat> = 10 000 PAK PŘÍPAD KDYŽ plat<= 20000 THEN give_bonus(employee_id, 1500); WHEN salary >40000 THEN give_bonus (employee_id, 500); KDY plat> 20000 POTOM give_bonus (employee_id, 1000); KONEC PŘÍPADU; KDY plat< 10000 THEN give_bonus(employee_id,0); END CASE; V příkazu CASE lze použít jakýkoli příkaz, takže interní příkaz CASE lze snadno nahradit příkazem IF. Podobně lze vnořit jakýkoli příkaz do příkazu IF, včetně CASE. Výrazy CASEVýrazy CASE plní stejnou úlohu jako příkazy CASE, ale ne pro spustitelné příkazy, ale pro výrazy. Jednoduchý CASE výraz vybere jeden z několika výrazů pro vyhodnocení na základě zadané skalární hodnoty. Vyhledávací výraz CASE vyhodnocuje výrazy v seznamu postupně, dokud jeden z nich nevyhodnotí TRUE a poté vrátí výsledek přidruženého výrazu. Syntaxe pro tyto dvě varianty výrazů CASE je: Simple_Case_expression: = CASE výraz WHEN result_1 THEN result_expression_1 KDY result_2 THEN result_expression_2 ... ELSE result_expression_else END; Search_Case_expression: = PŘÍPAD KDY výraz_1 POTOM výsledek_výraz1 KDY výraz_2 POTOM výsledek_výraz_2 ... JINÝ výsledek_výraz_končí KONEC; Výraz CASE vrací jednu hodnotu - výsledek výrazu vybraného pro vyhodnocení. Každá klauzule WHEN musí být spojena s jedním výrazem výsledku (ale nikoli s příkazem). Na konci výrazu CASE není středník ani END CASE. Výraz CASE končí klíčovým slovem END. Následuje příklad jednoduchého výrazu CASE použitého ve spojení s procedurou PUT_LINE balíčku DBMS_OUTPUT k zobrazení hodnoty logické proměnné. DECLARE boolean_true BOOLEAN: = PRAVDA; boolean_false BOOLEAN: = FALSE; boolean_null BOOLEAN; FUNKCE boolean_to_varchar2 (příznak V BOOLEANU) RETURN VARCHAR2 JE ZAČÁTEK PŘÍPADU RETURN KDYŽ PRAVDA POTOM „PRAVDA“ KDYŽ FALSE POTOM „Falešné“ JINÉ „NULL“ KONEC; KONEC; BEGIN DBMS_OUTPUT.PUT_LINE (boolean_to_varchar2 (boolean_true)); DBMS_OUTPUT.PUT_LINE (boolean_to_varchar2 (boolean_false)); DBMS_OUTPUT.PUT_LINE (boolean_to_varchar2 (boolean_null)); KONEC; K implementaci logiky pro výpočet bonusů můžete použít vyhledávací výraz CASE, který vrací hodnotu bonusu pro daný plat: ČÍSLO PROHLÁŠENÍ o platu: = 20 000; identifikační číslo zaměstnance: = 36325; POSTUP give_bonus (emp_id IN NUMBER, bonus_amt IN NUMBER) JE BEGIN DBMS_OUTPUT.PUT_LINE (emp_id); DBMS_OUTPUT.PUT_LINE (bonus_amt); KONEC; ZAČNĚTE give_bonus (employee_id, PŘÍPAD KDYŽ plat> = 10 000 A plat<= 20000 THEN 1500 WHEN salary >20 000 A plat<= 40000 THEN 1000 WHEN salary >40 000 PAK 500 JINÉ 0 KONEC); KONEC; Výraz CASE lze použít všude tam, kde lze použít výrazy jakéhokoli jiného typu. V následujícím příkladu se výraz CASE používá k výpočtu prémie, vynásobení 10 a přiřazení výsledku k proměnné zobrazené pomocí DBMS_OUTPUT: ČÍSLO PROHLÁŠENÍ o platu: = 20 000; identifikační číslo zaměstnance: = 36325; bonus_mount ČÍSLO; BEGIN bonus_amount: = PŘÍPAD, KDYž plat> = 10 000 A plat<= 20000 THEN 1500 WHEN salary >20 000 A plat<= 40000 THEN 1000 WHEN salary >40000 PAK 500 JINÉ 0 KONEC * 10; DBMS_OUTPUT.PUT_LINE (bonus_mount); KONEC; Na rozdíl od příkazu CASE, pokud není splněna žádná klauzule WHEN, výraz CASE nevyvolá chybu, ale jednoduše vrátí NULL. Populární
Novinka na webu
|