عبارات مشروط CASE. CASE عبارات شرط CASE بیان یک عبارت شرطی از زبان SQL است
عبارت CASE
عملکرد رمزگشایی
از دو روش استفاده می شود:
دو روشی که برای پیاده سازی شرطی (منطق IF-THEN-ELSE) در بیانیه SQL استفاده می شود عبارت CASE و تابع DECODE است.
توجه: عبارت CASE با ANSI SQL مطابقت دارد. عملکرد DECODE مختص نحو Oracle است.
عبارت CASE
با استفاده از دستور IF-THEN-ELSE ، سeriesالات شرطی را ساده می کند:
عبارات CASE به شما امکان می دهد بدون نیاز به فراخوانی رویه ها ، از منطق IF-THEN-ELSE در عبارات SQL استفاده کنید.
به زبان ساده بیان شرطی CASE سرور Oracle اولین جفت WHEN را جستجو می کند ... THEN که EXP برابر با Ex_Paction است و Return_expr را برمی گرداند. اگر هیچ یک از WHEN ... THEN جفتها این شرط را برآورده نمی کنند و اگر بند دیگری وجود داشته باشد ، Oracle else_expr را برمی گرداند. در غیر این صورت ، اوراکل صفر برمی گردد. نمی توانید NULL را برای همه return_exprs و else_expr تعیین کنید.
Expr و comparison_expr باید یک نوع داده باشد ، که می تواند CHAR ، VARCHAR2 ، NCHAR یا NVARCHAR2 باشد. تمام مقادیر بازگشتی (return_expr) باید از نوع داده یکسانی باشند.
در این نحو ، Oracle بیان ورودی (e) را با هر عبارت مقایسه ای e1 ، e2 ، ... ، en مقایسه می کند.
اگر عبارت ورودی برابر با هر عبارت مقایسه ای باشد ، عبارت CASE عبارت نتیجه مربوطه (r) را برمی گرداند.
اگر عبارت ورودی e با هیچ عبارت مقایسه ای مطابقت نداشته باشد ، اگر عبارت ELSE وجود داشته باشد ، عبارت CASE عبارت موجود در عبارت ELSE را برمی گرداند ، در غیر این صورت ، مقدار نول را برمی گرداند.
Oracle برای بیان ساده CASE از ارزیابی اتصال کوتاه استفاده می کند. این بدان معناست که Oracle هر عبارت مقایسه ای (e1، e2، .. en) را فقط قبل از مقایسه یکی از آنها با عبارت ورودی (e) ارزیابی می کند. Oracle قبل از مقایسه هر یک از عبارات مقایسه با عبارت (e) ، تمام عبارات مقایسه را ارزیابی نمی کند. در نتیجه ، اگر عبارت قبلی برابر با عبارت ورودی (e) باشد ، هرگز یک عبارت مقایسه را ارزیابی نمی کند.
مثال بیان ساده CASE
ما برای نمایش از جدول محصولات استفاده خواهیم کرد.
پرسش زیر از عبارت CASE برای محاسبه تخفیف برای هر دسته از محصولات یعنی CPU 5٪ ، کارت ویدیو 10٪ و سایر دسته های محصول 8٪ استفاده می کند.
انتخاب کنید CASE category_id وقتی 1 آنگاه دور (لیست_قیمت * 0.05،2) - پردازنده وقتی 2 آنگاه دور (لیست_قیمت * 0.1،2) - کارت ویدئو دور دیگر (لیست_قیمت * 0.08،2) - سایر دسته ها تخفیف پایان از جانب سفارش توسط |
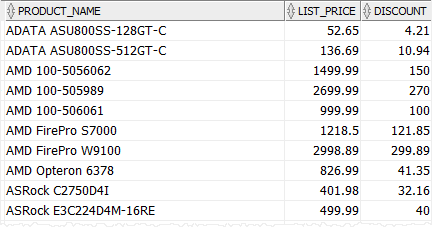
توجه داشته باشید که ما برای گرد کردن تخفیف به دو رقم اعشار از عملکرد ROUND () استفاده کردیم.
عبارت CASE جستجو شده
عبارت CASE جستجو شده Oracle لیستی از عبارات بولی را ارزیابی می کند تا نتیجه را تعیین کند.
عبارت CASE جستجو شده دارای دستور زیر است:
مورد وقتی e1THEN r1 ، COUNT (DISTINCT DepartmentID) [تعداد واحدهای منحصر به فرد] ، COUNT (DISTINCT PositionID) [تعداد موقعیت های منحصر به فرد] ، COUNT (BonusPercent) [تعداد کارمندان با٪ Bonus] ، MAX (BonusPercent) [حداکثر درصد پاداش] ، MIN ( BonusPercent) [حداقل درصد پاداش] ، SUM (حقوق / 100 * BonusPercent) [مجموع همه پاداش ها] ، AVG (حقوق / 100 * BonusPercent) [میانگین پاداش] ، AVG (حقوق) [متوسط حقوق] از کارمندان بیایید نگاهی به چگونگی پیدایش هر مقدار بازگشت بیاندازیم ، و برای مثال ، بیایید ساختارهای نحوی اساسی بیانیه SELECT را بیاد بیاوریم. اول ، به این دلیل ما شرایط مربوط به WHERE را در پرس و جو مشخص نکردیم ، سپس مجموع داده های مفصلی که توسط پرس و جو بدست می آید محاسبه می شود: * از بین کارمندان انتخاب کنید آنهایی که برای همه ردیف های جدول کارمندان. برای شفافیت ، ما فقط قسمتها و عباراتی را که در توابع جمع استفاده می شوند انتخاب می کنیم: SELECT DepartmentID، PositionID، BonusPercent، حقوق / 100 * BonusPercent، حقوق و دستمزد از کارمندان
این داده های اولیه (خطوط تفصیلی) است که به وسیله آنها کل پرس و جو جمع شده محاسبه می شود. حال بیایید نگاهی به هر مقدار جمع شده بیندازیم:
بیایید برخی از نتایج را خلاصه کنیم:
بر این اساس ، هنگام تعیین یک شرط اضافی با توابع جمع در بند WHERE ، فقط کل ردیف هایی که شرط را برآورده می کنند محاسبه می شود. آنهایی که محاسبه مقادیر جمع برای کل مجموعه انجام می شود ، که با استفاده از ساختار SELECT بدست می آید. به عنوان مثال ، بیایید همین کار را انجام دهیم ، اما فقط در زمینه بخش IT: COUNT را انتخاب کنید (*) [تعداد کل کارمندان] ، COUNT (DISTINCT DepartmentID) [تعداد بخشهای منحصر به فرد] ، COUNT (DISTINCT PositionID) [تعداد موقعیتهای منحصر به فرد] ، COUNT (BonusPercent) [تعداد کارمندان با٪ bonus] ، MAX (BonusPercent) [حداکثر درصد جایزه] ، MIN (BonusPercent) [حداقل درصد پاداش] ، SUM (حقوق / 100 * BonusPercent) [مجموع تمام پاداش ها] ، AVG (حقوق / 100 * BonusPercent) [اندازه متوسط پاداش] ، AVG ( حقوق) [میانگین حقوق] از کارمندان WHERE DepartmentID = 3 - فقط بخش IT را در نظر بگیرید SELECT DepartmentID، PositionID، BonusPercent، Salary / 100 * BonusPercent، حقوق و دستمزد از کارمندان WHERE DepartmentID = 3 - فقط شامل بخش IT است
برو جلو اگر تابع جمع NULL برگردد (به عنوان مثال ، همه کارمندان مقدار حقوق را مشخص نکرده اند) ، یا حتی یک رکورد در انتخاب گنجانده نشده است ، و در گزارش ، برای چنین موردی ، باید 0 را نشان دهیم ، سپس تابع ISNULL می تواند عبارت جمع را بپیچاند: SELECT SUM (حقوق) ، AVG (حقوق و دستمزد) ، - پردازش کل با استفاده از ISNULL ISNULL (SUM (حقوق و دستمزد) ، 0) ، ISNULL (AVG (حقوق و دستمزد) ، 0) از کارمندان WHERE DepartmentID = 10 - یک بخش موجود نیست به ویژه برای جلوگیری از بازگشت سوابق به سوابق ، در اینجا نشان داده شده است
من معتقدم که درک هدف هر تابع جمع و نحوه محاسبه آن بسیار مهم است ، زیرا در SQL ، این ابزار اصلی برای محاسبه کل است. در این حالت ، ما نحوه عملکرد هر یک از عملکردهای جمع را بررسی کردیم ، به عنوان مثال آن را به مقادیر کل مجموعه ضبط شده به دست آمده توسط دستور SELECT اعمال شد. در ادامه ، نحوه استفاده از همین توابع برای محاسبه کل گروهها با استفاده از بند GROUP BY را بررسی خواهیم کرد. GROUP BY - گروه بندی داده هاقبل از آن ، ما قبلاً مجموع مربوط به یک بخش خاص را محاسبه کرده ایم ، تقریباً به شرح زیر است:انتخاب تعداد (موقعیت متمایز) موقعیت ، تعداد ، تعداد (*) EmplCount ، مبلغ (حقوق و دستمزد) مبلغ مبلغ FROM از کارکنان WHERE DepartmentID = 3 - داده ها فقط برای بخش IT حال تصور کنید که از ما خواسته شده است که در متن هر بخش ، همان اعداد را بدست آوریم. البته ، ما می توانیم آستین بالا بزنیم و برای هر بخش درخواست مشابهی را برآورده کنیم. بنابراین ، زودتر از اتمام کار ، 4 درخواست می نویسیم: اطلاعات "اداره" را انتخاب کنید ، COUNT (موقعیت متمایز) PositionCount ، COUNT (*) EmplCount ، SUM (حقوق) حقوق و دستمزد مبلغ FROM از کارمندان WHERE DepartmentID = 1 - داده ها در مورد اداره اطلاعات "حسابداری" را انتخاب کنید ، COUNT (DISTINCT PositionID) PositionCount ، COUNT (* ) EmplCount ، SUM (حقوق و دستمزد) حقوق و دستمزد مبلغ FROM از کارکنان WHERE DepartmentID = 2 - داده های حسابداری اطلاعات "IT" را انتخاب کنید ، COUNT (DISTINCT PositionID) PositionCount ، COUNT (*) EmplCount ، SUM (حقوق) SalaryAmount FROM از کارکنان WHERE DepartmentID = 3 - داده ها در بخش IT اطلاعات "سایر" را انتخاب کنید ، COUNT (موقعیت DISTINCT) PositionCount ، COUNT (*) EmplCount ، SUM (حقوق) حقوق و دستمزد مبلغ FROM از کارمندان WHERE Departmentid NULL است - و داده های مربوط به فریلنسرها را فراموش نکنید در نتیجه ، ما 4 مجموعه داده دریافت می کنیم:
لطفا توجه داشته باشید که ما می توانیم از فیلدهای مشخص شده به عنوان ثابت استفاده کنیم - "اداره" ، "حسابداری" ، ... به طور کلی ، ما تمام اعدادی را که از ما خواسته شد استخراج کردیم ، ما همه چیز را در اکسل ترکیب می کنیم و به مدیر می دهیم. مدیر گزارش را پسندید ، و او می گوید: "و ستونی دیگر با اطلاعاتی در مورد میانگین حقوق اضافه کنید." و مثل همیشه ، این کار باید خیلی فوری انجام شود. هوم ، چه باید کرد؟! علاوه بر این ، بیایید تصور کنیم که ادارات ما 3 ، بلکه 15 نیستند. این دقیقاً همان چیزی است که بند GROUP BY برای چنین مواردی است: SELECT DepartmentID، COUNT (DISTINCT PositionID) PositionCount، COUNT (*) EmplCount، SUM (حقوق) SalaryAount، AVG (Salary) SalaryAgg - به علاوه ما خواسته های مدیر FROM Employees GROUP BY DepartmentID را برآورده می کنیم
ما همه داده های مشابه را بدست آوردیم ، اما اکنون فقط از یک درخواست استفاده می کنیم! در حال حاضر ، به این نکته توجه نکنید که بخشهای ما به صورت اعداد نمایش داده می شوند ، سپس یاد خواهیم گرفت که چگونه همه چیز را به زیبایی نمایش دهیم. در بند GROUP BY ، می توانید چندین فیلد "GROUP BY field1، field2، ...، fieldN" را تعیین کنید ، در این حالت گروه بندی توسط گروه هایی انجام می شود که مقادیر این فیلدها را تشکیل می دهند "field1، field2، .. .، fieldN ". به عنوان مثال ، بیایید داده ها را براساس گروه ها و گروه ها گروه بندی کنیم: SELECT DepartmentID ، PositionID ، COUNT (*) EmplCount ، SUM (حقوق) حقوق و دستمزد مبلغ FROM از کارکنان گروه توسط DepartmentID ، PositionID SELECT COUNT (*) EmplCount، SUM (حقوق) حقوق و دستمزد مبلغ FROM از کارمندانی که Departmentid NULL است و PositionID IS NULL است SELECT COUNT (*) EmplCount، SUM (حقوق) SalaAmount FROM از کارمندان WHERE DepartmentID = 1 و PositionID = 2 - ... انتخاب تعداد (*) EmplCount، SUM (حقوق) حقوق و دستمزد مبلغی از کارمندان WHERE DepartmentID = 3 AND PositionID = 4 و سپس همه این نتایج با هم ترکیب می شوند و به عنوان یک مجموعه در اختیار ما قرار می گیرند:
از مورد اصلی ، لازم به ذکر است که در مورد گروه بندی (GROUP BY) ، در لیست ستون ها در بلوک SELECT:
و نمایشی از همه آنچه گفته شد: انتخاب "رشته ثابت" Const1 ، - ثابت به شکل رشته 1 Const2 ، - ثابت به شکل یک عدد - عبارت با استفاده از زمینه های شرکت کننده در گروه CONCAT ("بخش شماره" ، DepartmentID) ConstAndGroupField ، CONCAT ("بخش شماره "، DepartmentID ،" ، Position No. "، PositionID) ConstAndGroupFields ، DepartmentID ، - فیلدی از لیست زمینه های شرکت کننده در گروه بندی - PositionID ، - فیلدی که در گروه بندی شرکت می کند ، لازم نیست در اینجا کپی کنید COUNT ( *) EmplCount ، - تعداد خطوط در هر گروه - از بقیه قسمتها فقط با توابع جمع می توان استفاده کرد: COUNT ، SUM ، MIN ، MAX ، ... SUM (حقوق) SalaryAmount ، MIN (ID) MinID از گروه کارمندان BY DepartmentID، PositionID - گروه بندی بر اساس قسمت ها DepartmentID، PositionID همچنین لازم به ذکر است که گروه بندی می تواند نه تنها توسط زمینه ها ، بلکه توسط عبارات نیز انجام شود. به عنوان مثال ، بیایید داده ها را براساس کارمندان ، براساس سال تولد گروه بندی کنیم: SELECT CONCAT ("سال تولد -" ، YEAR (روز تولد)) YearOfBirthday ، COUNT (*) EmplCount از گروه کارمندان براساس سال (تولد) بیایید به یک مثال با بیان پیچیده تر نگاه کنیم. به عنوان مثال ، اجازه دهید درجه کارکنان را براساس سال تولد دریافت کنیم: انتخاب پرونده WHEN YEAR (تولد)> = 2000 THEN "از 2000" WHEN YEAR (تولد)> = 1990 سپس "1999-1990" WHEN YEAR (تولد)> = 1980 سپس "1989-1980" WHEN YEAR (تولد)> = 1970 پس از آن "1979-1970" وقتی تولد آن بعد از آن خالی است "قبل از سال 1970" ELSE "مشخص نشده است" پایان دامنه نام ، تعداد (*) EmplCount از کارکنان گروه بر اساس مورد WHEN YEAR (تولد)> = 2000 THEN "از 2000" WHEN YEAN " (تولد)> = 1990 سپس "1999-1990" WHEN YEAR (تولد)> = 1980 سپس "1989-1980" WHEN YEAR (تولد)> = 1970 سپس "1979-1970" هنگامی که تولد پس از آن کامل نیست "قبل از 1970" دیگری "مشخص نشده" است پایان
آنهایی که در این حالت ، گروه بندی طبق عبارات CASE انجام می شود که قبلاً برای هر کارمند محاسبه شده است: شناسه را انتخاب کنید ، مورد WHEN YEAR (تولد)> = 2000 THEN "از 2000" WHEN YEAR (تولد)> = 1990 سپس "1999-1990" WHEN YEAR (تولد)> = 1980 سپس "1989-1980" WHEN YEAR (تولد) > = 1970 سپس "1979-1970" هنگامی که تولد آن بعد از آن تمام نمی شود "قبل از 1970" ELSE "مشخص نشده است" پایان کارمندان "
و البته ، می توانید عبارات را با فیلدها در بلوک GROUP BY ترکیب کنید: SELECT DepartmentID، CONCAT ("سال تولد -"، YEAR (تولد)) YearOfBirthday، COUNT (*) EmplCount از گروه کارکنان براساس سال (تولد)، DepartmentID - ممکن است این سفارش با ترتیب استفاده آنها در سفارش انتخاب منطبق نباشد با بلوک DepartmentID ، YearOfBirthday - سرانجام ، ما می توانیم مرتب سازی را برای نتیجه اعمال کنیم بیایید به کار اصلی خود برگردیم. همانطور که قبلاً می دانیم ، مدیر گزارش را بسیار پسندیده است ، و او از ما خواسته است که این کار را هفتگی انجام دهیم تا بتواند تغییرات شرکت را رصد کند. برای اینکه هر بار در Excel مقدار عددی دپارتمان را با نام آن قطع نکنیم ، ما از دانشی که در حال حاضر داریم استفاده خواهیم کرد و پرس و جو خود را بهبود می بخشیم: CASE را انتخاب کنید وقتی 1 بار "مدیریت" وقتی 2 "حساب" در صورت 3 "دیگر" دیگر "اطلاعات پایان ، تعداد (موقعیت متمایز) موقعیت ، تعداد ، تعداد (*) EmplCount ، مبلغ (حقوق) SalaAmount ، AVG (حقوق) ) SalaryAvg - به علاوه ما خواسته های مدیر FROM Employees GROUP BY DepartmentID ORDER BY Info را برآورده می کنیم - برای راحتی بیشتر مرتب سازی را بر اساس ستون Info اضافه کنید اما هیچ چیز ، با گذشت زمان ، ما یاد می گیریم که همه کارها را به زیبایی انجام دهیم ، به طوری که نمونه ما به ظاهر داده های جدید در پایگاه داده بستگی ندارد ، بلکه پویا است. من کمی جلوتر خواهم زد و نشان خواهم داد که چه نوع درخواست هایی را ارائه می دهیم: SELECT ISNULL (dep.Name، "Other") DepName، COUNT (DISTINCT emp.PositionID) PositionCount، COUNT (*) EmplCount، SUM (emp.Salary) SalaryAmount، AVG (emp.Salary) SalaryAvg - بعلاوه برآورده کردن خواسته های مدیر FROM Employees LEFT بپیوندید بخشهای بخش ON emp.DepartmentID = dep.ID GROUP BY emp.DepartmentID ، dep.Name ORDER BY DepName به طور کلی ، نگران نباشید - همه کار را ساده شروع کردند. در حال حاضر ، شما فقط باید اصل بند GROUP BY را درک کنید. در آخر ، بیایید ببینیم که چگونه می توانید گزارش های خلاصه را با استفاده از GROUP BY ایجاد کنید. به عنوان مثال ، بیایید یک جدول محوری را در متن بخش ها نمایش دهیم ، به طوری که کل حقوق دریافتی کارکنان بر اساس موقعیت محاسبه می شود: SELECT DepartmentID ، SUM (CASE WHEN PositionID = 1 THEN حقوق پایان یافته) [حسابداران] ، SUM (CASE WHEN PositionID = 2 THEN حقوق پس از پایان) [مدیران] ، SUM (CASE WHEN PositionID = 3 THEN حقوق پس از پایان) [برنامه نویسان] ، SUM ( CASE WHEN PositionID = 4 THEN حقوق و دستمزد پایان می یابد) [برنامه نویسان ارشد] ، SUM (حقوق و دستمزد) [مجموع بخش] از گروه کارمندان توسط DepartmentID البته می توانید با استفاده از IIF بازنویسی کنید: SELECT DepartmentID، SUM (IIF (PositionID = 1، حقوق، NULL)) [حسابدار]، SUM (IIF (PositionID = 2، حقوق، NULL)) [مدیران]، SUM (IIF (PositionID = 3، حقوق، NULL)) [برنامه نویسان] ، SUM (IIF (PositionID = 4 ، حقوق ، NULL))] [برنامه نویسان ارشد] ، SUM (حقوق و دستمزد) [مجموع بخش] از گروه کارمندان توسط DepartmentID اما در مورد IIF ، ما باید صریحاً NULL را مشخص كنیم كه در صورت عدم تحقق شرط بازگردانده می شود. در موارد مشابه ، من ترجیح می دهم از CASE بدون بلوک ELSE استفاده کنم تا اینکه یک بار دیگر NULL بنویسم. اما این مسلماً سلیقه ای است که در مورد آن بحث نمی شود. و بیاد داشته باشیم که مقادیر NULL در توابع تجمع در نظر گرفته نمی شوند. برای ادغام ، تجزیه و تحلیل مستقلی از داده های به دست آمده توسط درخواست توسعه یافته انجام دهید: SELECT DepartmentID، CASE WHEN PositionID = 1 THEN End End حقوق [حسابدار]، CASE WHE PositionID = 2 THEN حقوق پایان یافته [مدیران]، CASE WHEN PositionID = 3 THEN Salary End [برنامه نویسان]، CASE WHEN PositionID = 4 THEN Salary End [برنامه نویسان ارشد ] ، حقوق و دستمزد [مجموع بخش] از کارمندان
و همچنین بخاطر بسپاریم که اگر به جای NULL می خواهیم صفر ببینیم ، می توانیم مقدار برگردانده شده توسط تابع جمع را پردازش کنیم. مثلا: SELECT DepartmentID، ISNULL (SUM (IIF (PositionID = 1، حقوق، NULL))، 0) [حسابدار]، ISNULL (SUM (IIF (PositionID = 2، حقوق، NULL))، 0) [مدیران]، ISNULL (جمع) (IIF (PositionID = 3 ، حقوق ، NULL)) ، 0) [برنامه نویسان] ، ISNULL (SUM (IIF (PositionID = 4 ، حقوق ، NULL)) ، 0) [برنامه نویسان ارشد] ، ISNULL (جمع (حقوق) ، 0 ) [مجموع بخش] از گروه کارمندان توسط DepartmentID
GROUP BY در پراکنده با توابع جمع ، یکی از اصلی ترین ابزارهایی که برای بدست آوردن اطلاعات خلاصه از پایگاه داده استفاده می شود ، زیرا معمولاً داده ها در این فرم استفاده می شوند ، زیرا ما معمولاً ملزم به ارائه گزارش های خلاصه به جای داده های دقیق (ورق) هستیم. و البته ، همه اینها حول محور دانستن طرح اصلی است ، زیرا قبل از اینکه چیزی را خلاصه کنید (جمع کنید) ، ابتدا باید آن را با استفاده از "SELECT ... WHERE ..." به درستی انتخاب کنید. تمرین در اینجا نقش مهمی را ایفا می کند ، بنابراین ، اگر هدف خود را برای درک زبان SQL قرار دهید ، نه یادگیری ، بلکه درک آن - تمرین ، تمرین و تمرین ، گذراندن متفاوت ترین گزینه هایی که فکر می کنید. در مرحله اولیه ، اگر از صحت داده های جمع آوری شده به دست آمده مطمئن نیستید ، یک نمونه دقیق از جمله مقادیری را که تجمع برای آنها در حال انجام است ، تهیه کنید. و صحت محاسبات را با استفاده از این داده های دقیق به صورت دستی بررسی کنید. در این حالت استفاده از اکسل می تواند بسیار مفید باشد. بگذارید بگوییم شما به این مرحله رسیدیدبگذارید بگوییم شما یک حسابدار S. S. Sidorov هستید ، که تصمیم گرفته است نحوه نوشتن درخواستهای SELECT را بیاموزد.بگذارید بگوییم که شما قبلاً خواندن این آموزش را تا این مرحله به پایان رسانده اید ، و از قبل از استفاده از همه ساختارهای اساسی فوق اطمینان دارید ، یعنی تو می توانی:
بله ، اما آنها در نظر نگرفتند که شما هنوز نمی توانید از چندین جدول درخواست کنید ، اما فقط از یک جدول ، به عنوان مثال شما نمی دانید چطور چنین کاری انجام دهید: SELECT emp. * ، - تمام قسمتهای جدول Employees را برگردانید. نام DepartmentName ، - قسمت Name را از جدول Departments اضافه کنید. Name PositionName را به این قسمت ها اضافه کنید - و همچنین نام Name را از جدول Positions FROM Employees emp اضافه کنید LEFT JOIN دپارتمان های بخش ON emp.DepartmentID = dep.ID سمت چپ عضویت موقعیت های poz ON emp.PositionID = pos.ID بنابراین ، چگونه می توانید از دانش فعلی خود استفاده کرده و حتی نتایج پربارتری نیز بدست آورید؟! ما از قدرت ذهن جمعی استفاده خواهیم کرد - ما به سراغ برنامه نویسان می رویم که برای شما کار می کنند ، یعنی به Andreev A.A. ، Petrov P.P. یا Nikolayev N.N. ، و از یکی از آنها بخواهید که یک نمای برای شما بنویسد (VIEW یا به سادگی "View" ، بنابراین حتی سریعتر شما را درک می کنند) ، که علاوه بر زمینه های اصلی از جدول Employees ، زمینه ها را با "نام بخش" و "نام موقعیت" ، که اکنون برای گزارش هفتگی که ایوانف دوم برای شما بارگذاری کرده است ، فاقد آن هستید. زیرا شما همه چیز را به درستی توضیح دادید ، سپس متخصصان فناوری اطلاعات بلافاصله آنچه را که از آنها می خواهند فهمیدند و به ویژه برای شما دیدگاهی به نام ViewEmployeesInfo ایجاد کردند. ما نشان می دهیم که شما دستور بعدی را نمی بینید ، زیرا متخصصان فناوری اطلاعات این کار را انجام می دهند: ایجاد نمایی از ViewEmployeesInfo AS SELECT emp. * ، - تمام قسمتهای جدول Employees Dep را برگردانید. Name DepartmentName ، - قسمت Name را از قسمت Departments اضافه کنید. جدول Name Name Name نام را به این قسمت ها اضافه کنید - و همچنین نام Name را از جدول Positions FROM اضافه کنید Employees emp از سمت چپ بپیوندید به بخش ها در بخش emp.DepartmentID = dep.ID از سمت چپ بپیوندید موقعیت ها در ON emp.PositionID = pos.ID آنهایی که برای همه شما ، هرچند ترسناک و قابل درک نیست ، متن خارج از صفحه باقی می ماند و متخصصان فناوری اطلاعات فقط نام نمای "ViewEmployeesInfo" را به شما می دهند که تمام داده های فوق را برمی گرداند (یعنی آنچه شما از آنها خواسته اید). اکنون می توانید مانند این جدول منظم با این نمای کار کنید: انتخاب * از ViewEmployeesInfo SELECT DepartmentName، COUNT (DISTINCT PositionID) PositionCount، COUNT (*) EmplCount، SUM (حقوق) SalaryAmount، AVG (حقوق) حقوق Avg FROM ViewEmployeesInfo emp GROUP BY DepartmentID، DepartmentName ORDER BY DepartmentName آنهایی که برای شما در این حالت ، مثل اینکه چیزی تغییر نکرده باشد ، شما با یک جدول کار می کنید (اما گفتن با نمای ViewEmployeesInfo درست تر است) ، که تمام داده های شما را برمی گرداند. با تشکر از کمک متخصصان IT ، جزئیات استخراج DepartmentName و PositionName در یک جعبه سیاه برای شما باقی می ماند. آنهایی که نمای شما به عنوان یک جدول معمولی یکسان است ، آن را یک نسخه گسترده از جدول کارمندان بدانید. به عنوان مثال ، بیایید بیانیه ای تشکیل دهیم ، تا مطمئن شوید همه چیز همانطور که گفتم واقعاً است (که کل نمونه از یک نمای بدست می آید): شناسه ، نام ، حقوق و دستمزد را از طریق مشاهده کارمندان در مورد WHERE Salary is NULL AND حقوق و دستمزد انتخاب کنید> 0 سفارش به نام استفاده از نماها در بعضی موارد باعث می شود مرزهای کاربرانی که می دانند چگونه نوشتن درخواست های اساسی SELECT را انجام دهند ، به طور قابل توجهی گسترش یابد. در این حالت ، نمای یک جدول مسطح با تمام داده های مورد نیاز کاربر است (برای کسانی که OLAP را درک می کنند ، این را می توان با تقریب مکعب OLAP با حقایق و ابعاد مقایسه کرد). برش از ویکی پدیا.اگرچه SQL به عنوان ابزاری برای کاربر نهایی تصور می شد ، اما در نهایت چنان پیچیده شد که به ابزار برنامه نویس تبدیل شد. همانطور که مشاهده می کنید ، کاربران گرامی ، زبان SQL در ابتدا به عنوان ابزاری برای شما در نظر گرفته شده است. بنابراین ، همه چیز در دست شما و آرزو است ، رها نکنید. HAVING - تحمیل شرط انتخاب بر داده های گروه بندی شدهدر واقع ، اگر می فهمید که یک گروه چیست ، پس HAVING هیچ چیز پیچیده ای ندارد. HAVING تا حدی شبیه WHERE است ، فقط اگر شرط WHERE روی داده های دقیق اعمال شود ، سپس شرایط HAVING روی داده های قبلاً گروه بندی شده اعمال می شود. به همین دلیل ، در شرایط بلوک HAVING ، می توانیم از عبارات دارای فیلدهای موجود در گروه بندی یا عبارات محصور در توابع جمع استفاده کنیم.بیایید یک مثال را در نظر بگیریم: SELECT DepartmentID، SUM (حقوق) حقوق و دستمزد مبلغ FROM از کارکنان گروه توسط Departmentid با داشتن مبلغ (حقوق)> 3000
آنهایی که این درخواست داده های گروه بندی شده را فقط برای آن بخشهایی که کل حقوق و دستمزد همه کارمندان بیش از 3000 است ، به ما بازگردانده است. "SUM (حقوق)> 3000".
آنهایی که در اینجا ، اول از همه ، گروه بندی انجام می شود و داده های همه بخش ها محاسبه می شود: SELECT DepartmentID ، SUM (حقوق و دستمزد) حقوق و دستمزد مبلغ FROM از کارکنان گروه توسط DepartmentID - 1. دریافت داده های گروه بندی شده برای همه بخش ها و از قبل شرایط مشخص شده در بلوک HAVING روی این داده ها اعمال شده است: SELECT DepartmentID، SUM (حقوق) حقوق و دستمزد مبلغ FROM از کارکنان گروه توسط DepartmentID - 1. دریافت داده های گروه بندی شده برای همه بخش ها با داشتن SUM (حقوق)> 3000 - 2. شرط فیلتر کردن داده های گروه بندی شده در شرایط HAVING ، می توانید با استفاده از عملگرهای AND ، OR و NOT شرایط پیچیده ای نیز ایجاد کنید: SELECT DepartmentID ، SUM (حقوق) حقوق و دستمزد مبلغ FROM از کارکنان گروه توسط Departmentid با داشتن مبلغ (حقوق)> 3000 و تعداد (*)<2 -- и число людей меньше 2-х
همانطور که در اینجا مشاهده می کنید تابع جمع (به "COUNT (*)" مراجعه کنید) فقط در بلوک HAVING قابل تعیین است. بر این اساس ، ما فقط می توانیم تعداد دپارتمان هایی را که مطابق با شرایط HAVING است نمایش دهیم: SELECT DepartmentID از گروه کارمندان براساس Departmentid با داشتن مبلغ (حقوق)> 3000 و تعداد (*)<2 -- и число людей меньше 2-х نمونه ای از استفاده از شرط HAVING در فیلدی که در GROUP BY گنجانده شده است: SELECT DepartmentID، SUM (حقوق) حقوق و دستمزد مبلغ FROM از کارکنان گروه توسط DepartmentID - 1. گروه بندی کنید HAVING DepartmentID = 3 - 2. نتیجه گروه بندی را فیلتر کنید این فقط یک مثال است ، از در این مورد ، منطقی تر است که از طریق شرایط WHERE بررسی کنید: SELECT DepartmentID، SUM (حقوق) حقوق و دستمزد مبلغ FROM از کارکنان WHERE DepartmentID = 3 - 1. فیلتر کردن اطلاعات دقیق GROUP BY DepartmentID - 2. گروه بندی فقط با سوابق انتخاب شده آنهایی که ابتدا کارمندان را توسط بخش 3 فیلتر کنید و فقط پس از آن محاسبه کنید. توجه داشته باشید.در حقیقت ، حتی اگر دو پرس و جو متفاوت به نظر برسند ، بهینه ساز DBMS می تواند آنها را به همان روش اجرا کند. من فکر می کنم اینجاست که داستان درباره شرایط داشتن به پایان می رسد. بیایید خلاصه کنیمبیایید داده های بدست آمده در قسمت های دوم و سوم را خلاصه کنیم و موقعیت خاص هر سازه ای را که مورد مطالعه قرار دادیم در نظر بگیریم و ترتیب اجرای آنها را نشان دهیم:
البته می توانید بندهای DISTINCT و TOP را که در قسمت دوم آموخته اید نیز برای داده های گروه بندی شده اعمال کنید. این پیشنهادات در این مورد برای نتیجه نهایی اعمال می شود: TOP 1 - 6 را انتخاب کنید. 6 آخرین SUM (حقوق و دستمزد) را اعمال می کند مبلغ FROM از کارکنان گروه توسط Departmentid با داشتن مبلغ (حقوق)> 3000 سفارش توسط DepartmentID - 5. مرتب سازی بر اساس نتیجه چگونگی بدست آوردن این نتایج را خودتان تحلیل کنید. نتیجههدف اصلی که من در این قسمت تعیین کردم این است که ماهیت توابع و گروه بندی های کل را برای شما فاش کنم.اگر طراحی اصلی به ما امکان می داد داده های دقیق لازم را بدست آوریم ، پس استفاده از توابع و گروه بندی های کل روی این داده های دقیق این فرصت را به ما می دهد که داده های خلاصه ای را درباره آنها بدست آوریم. همانطور که می بینید ، اینجا همه چیز مهم است ، tk. یکی مبتنی بر دیگری است - بدون اطلاع از ساختار اساسی ، ما قادر نخواهیم بود به عنوان مثال ، داده هایی را که برای محاسبه کل آنها نیاز داریم به درستی انتخاب کنیم. در اینجا ، من عمدا سعی می کنم فقط اصول را نشان دهم ، بنابراین توجه مبتدی را به مهمترین ساختارها متمرکز می کنم و آنها را با اطلاعات غیر ضروری پر نمی کنم. درک صحیح از ساختارهای اساسی (که در بخشهای بعدی در مورد آنها صحبت خواهم کرد) به شما این امکان را می دهد که تقریباً هر مشکلی در واکشی داده ها از RDB را حل کنید. ساختارهای اساسی بیانیه SELECT تقریباً در همه DBMS به همان شکل قابل اجرا است (تفاوت ها عمدتا در جزئیات نهفته است ، به عنوان مثال در اجرای توابع - برای کار با رشته ها ، زمان و غیره). متعاقباً ، دانش کافی در مورد پایه به شما این فرصت را می دهد تا به راحتی و به تنهایی پسوندهای مختلف زبان SQL را یاد بگیرید ، مانند:
اگر اولین قدم های خود را در SQL برمی دارید ، ابتدا در یادگیری سازه های اصلی تمرکز کنید. داشتن پایگاه ، درک همه موارد دیگر برای شما بسیار آسان تر خواهد بود ، و علاوه بر این ، به تنهایی. اول از همه ، شما باید توانایی های زبان SQL را درک کنید ، یعنی چه نوع عملیاتی به طور کلی اجازه می دهد تا بر روی داده انجام شود. انتقال اطلاعات به افراد مبتدی به صورت گسترده یکی دیگر از دلایلی است که من فقط مهمترین ساختارها (آهن) را نشان می دهم. موفق باشید زبان SQL را یاد بگیرید و درک کنید. قسمت چهارم -
آنچه در این قسمت مورد بحث قرار خواهد گرفتدر این بخش ما خواهیم شناخت:
عبارت CASE - عبارت شرطی SQLاین اپراتور به شما امکان می دهد بسته به تحقق یک شرایط خاص ، شرایط را بررسی کرده و نتیجه یا نتیجه دیگری را برگردانید.دستور CASE دارای 2 فرم است: بیایید مثالی از اولین فرم CASE بگیریم: شناسه را انتخاب کنید ، نام ، حقوق و دستمزد ، CASE WHEN حقوق و دستمزد> = 3000 سپس "RFP> = 3000" وقتی حقوق> = 2000 سپس "2000<= ЗП < 3000"
ELSE "ЗП < 2000"
END SalaryTypeWithELSE,
CASE
WHEN Salary>= 3000 THEN "حقوق و دستمزد> = 3000" WHEN حقوق و دستمزد> = 2000 THEN "2000<= ЗП < 3000"
END SalaryTypeWithoutELSE
FROM Employees
اگر هیچ یک از شرایط WHEN برآورده نشود ، پس از تعیین مقدار پس از کلمه ELSE ، مقدار مشخص شده برگردانده می شود (که در این حالت به معنی "بازگشت دیگر است ..."). اگر هیچ بلوک ELSE مشخص نشده باشد و شرایط WHEN برآورده نشود ، NULL بازگردانده می شود. در هر دو شکل اول و دوم ، بلوک ELSE در انتهای ساختار CASE قرار می گیرد ، یعنی بعد از همه شرایط بیایید مثالی از فرم CASE دوم بیاوریم: فرض کنید ، برای سال جدید ، آنها تصمیم گرفتند به همه کارمندان پاداش دهند و از آنها خواستند که مقدار پاداش ها را طبق طرح زیر محاسبه کنند:
برای این کار ، از کوئری با عبارت CASE استفاده می کنیم: شناسه ، نام ، حقوق و دستمزد را انتخاب کنید ، برای شفافیت ، ما درصد را به صورت یک خط CASE DepartmentID نشان می دهیم - مقدار علامت گذاری شده WHEN 2 THEN "10٪" - 10٪ حقوق پرداختی به حسابداران هنگامی که 3 پس "15٪" - 15٪ از حقوق برای پرداخت آن به کارمندان IT "5٪" - به دیگران 5٪ پایان NewYearBonusPercent ، - بیایید با استفاده از CASE یک عبارت بسازیم تا میزان پاداش را ببینیم / 100 * CASE DepartmentID WHEN 2 THEN 10 - 10 of از حقوق برای صدور حسابداران هنگامی که 3 سپس 15 - 15 of از حقوق برای صدور کارمندان فناوری اطلاعات دیگر 5 - بقیه 5 each هر پاداش پایان مبلغ از کارمندان بر این اساس ، اگر DepartmentID با هیچ مقدار WHEN مطابقت نداشته باشد ، مقدار بلاک ELSE بازگردانده می شود. اگر هیچ بلوک ELSE وجود نداشته باشد ، اگر DepartmentID با هیچ مقدار WHEN مطابقت نداشته باشد ، NULL بازگردانده می شود. فرم CASE دوم با استفاده از فرم اول به راحتی نمایش داده می شود: ID را انتخاب کنید ، نام ، حقوق و دستمزد ، DepartmentID ، مورد WHEN DepartmentID = 2 سپس "10٪" - 10٪ از حقوق برای حسابداران صادر می شود WHE DepartmentID = 3 سپس "15٪" - 15٪ از حقوق برای IT صادر می شود کارمندان ELSE "5٪" - بقیه 5٪ END NewYearBonusPercent ، - با استفاده از CASE یک عبارت بسازید تا مبلغ جایزه را ببینید حقوق / 100 * CASE WHEN DepartmentID = 2 سپس 10 - 10٪ حقوق برای حسابداران WHEN DepartmentID = 3 سپس 15 - 15 of از حقوق برای صدور کارمندان فناوری اطلاعات ELSE 5 - بقیه 5 each هر کس پاداش پایان مبلغ از کارمندان بنابراین فرم دوم فقط یک علامت ساده برای مواردی است که ما باید مقایسه برابری همان مقدار آزمون را با هر مقدار / عبارت WHEN انجام دهیم. توجه داشته باشید.شکل اول و دوم CASE در استاندارد زبان SQL گنجانده شده است ، بنابراین به احتمال زیاد باید در بسیاری از DBMS قابل اجرا باشد. با نسخه MS SQL نسخه 2012 ، یک فرم نمادگذاری IIF ساده ظاهر شده است. هنگامی که فقط 2 مقدار برگردانده می شود می تواند برای ساده کردن دستور CASE استفاده شود. طراحی IIF به شرح زیر است: IIF (شرط ، ارزش واقعی) ، ارزش غلط) آنهایی که در واقع ، این یک بسته بندی برای ساخت مورد CASE زیر است: CASE WHEN شرط THEN true_value ELSE false_value END بیایید یک مثال ببینیم: شناسه SELECT ، نام ، حقوق و دستمزد ، IIF (حقوق و دستمزد> = 2500 ، "حقوق و دستمزد> = 2500" ، "حقوق و دستمزد"< 2500") DemoIIF, CASE WHEN Salary>= 2500 THEN "RFP> = 2500" ELSE "RFP< 2500" END DemoCASE FROM Employees سازه های CASE ، IIF می توانند درون یکدیگر قرار بگیرند. بیایید یک مثال انتزاعی را در نظر بگیریم: شناسه ، نام ، حقوق و دستمزد را انتخاب کنید ، هنگامی که وزارت (1،2) سپس "A" WHEN DepartmentID = 3 پس از آن PositionID - پرونده تو در تو هنگامی که 3 سپس "B-1" هنگامی که 4 سپس "B-2" پایان دیگر "C "END Demo1، IIF (DepartmentID IN (1،2)،" A "، IIF (DepartmentID = 3، CASE PositionID WHEN 3 THEN" B-1 "WHEN 4 THEN" B-2 "END،" C ")) Demo2 از کارمندان از آنجا که سازه های CASE و IIF عباراتی هستند که نتیجه را برمی گردانند ، ما می توانیم از آنها نه تنها در بلوک SELECT بلکه در بلوک های دیگری که اجازه استفاده از عبارات را می دهند ، به عنوان مثال در بندهای WHERE یا ORDER BY ، استفاده کنیم. به عنوان مثال ، به ما وظیفه ایجاد لیستی برای توزیع حقوق به ما داده می شود ، به شرح زیر:
بیایید سعی کنیم این مسئله را با اضافه کردن یک عبارت CASE به بلوک ORDER BY حل کنیم: شناسه ، نام ، حقوق و دستمزد را از بین کارمندان انتخاب کنید با توجه به پرونده هنگامی که حقوق>> 2500 سپس 1 دیگر 0 پایان ، - ابتدا برای کسانی که آن را زیر 2500 نام دارند حقوق دریافت کنید - لیست را به ترتیب نام کامل مرتب کنید و یک مثال انتزاعی از استفاده از CASE در بند WHERE: شناسه ، نام ، حقوق و دستمزد را از بین کارمندان WHERE CENE WHENE Salary> = 2500 THEN 1 ELSE 0 END = 1 انتخاب کنید - تمام سوابق بیان 1 می توانید سعی کنید 2 نمونه آخر را با عملکرد IIF خودتان دوباره انجام دهید. و در آخر ، بیایید دوباره در مورد مقادیر NULL به یاد بیاوریم: ID را انتخاب کنید ، نام ، حقوق و دستمزد ، DepartmentID ، مورد WHEN DepartmentID = 2 سپس "10٪" - 10٪ از حقوق برای صدور حسابداران هنگامی که DepartmentID = 3 سپس "15٪" - برای صدور 15٪ حقوق برای کارمندان IT هنگامی که DepartmentID پس از آن NULL "-" - ما به فریلنسرها پاداش نمی دهیم (ما از IS NULL استفاده می کنیم) "5٪" - همه افراد دیگر 5٪ دارند NEWYEarBonusPercent1 ، - اما شما نمی توانید NULL را بررسی کنید ، به یاد داشته باشید در مورد NULL در قسمت دوم CASE DepartmentID - - مقدار علامت زده شده WHEN 2 THEN "10٪" WHEN 3 THEN "15٪" WHEN NULL THEN "-" - !!! در این حالت ، استفاده از فرم CASE دوم مناسب نیست ELSE "5٪" END NewYearBonusPercent2 از کارمندان SELECT ID ، نام ، حقوق و دستمزد ، DepartmentID ، CASE ISNULL (DepartmentID ، -1) - در صورت NULL با استفاده از جایگزین با -1 وقتی که 2 "سپس" 10٪ "WHEN 3 THEN" 15٪ "WHEN -1 THEN" - "- اگر اطمینان داشته باشیم که هیچ دپارتمان با شناسه برابر با (-1) وجود ندارد و "5٪" دیگر پایان یابد NewYearBonusPercent3 از کارمندان به طور کلی ، پرواز تخیل در این مورد محدود نیست. به عنوان مثال ، بیایید ببینیم چگونه می توان تابع ISNULL را با استفاده از CASE و IIF مدل سازی کرد: SELECT ID ، نام ، نام خانوادگی ، ISNULL (نام خانوادگی ، "نامشخص") DemoISNULL ، مورد هنگامی که نام خانوادگی NULL است سپس "نامشخص" ELSE LastName END DemoCASE ، IIF (نام خانوادگی IS NULL ، "مشخص نشده" ، نام خانوادگی) DemoIIF از کارمندان سازه CASE یک ویژگی SQL بسیار قدرتمند است که به شما امکان می دهد منطق اضافی را برای محاسبه مقادیر مجموعه نتیجه تحمیل کنید. در این قسمت ، در اختیار داشتن ساخت CASE هنوز برای ما مفید خواهد بود ، بنابراین ، در این قسمت ، اول از همه ، به آن توجه می شود. توابع جمعدر اینجا ما فقط توابع اصلی و معمولاً مورد استفاده را پوشش خواهیم داد:
توابع جمع به ما امکان می دهد مقدار کل مجموعه ای از ردیف های بدست آمده با استفاده از دستور SELECT را محاسبه کنیم. بیایید هر یک از عملکردها را با یک مثال بررسی کنیم: COUNT را انتخاب کنید (*) [تعداد کل کارمندان] ، COUNT (DISTINCT DepartmentID) [تعداد بخشهای منحصر به فرد] ، COUNT (DISTINCT PositionID) [تعداد موقعیتهای منحصر به فرد] ، COUNT (BonusPercent) [تعداد کارمندان با٪ bonus] ، MAX (BonusPercent) [حداکثر درصد جایزه] ، MIN (BonusPercent) [حداقل درصد پاداش] ، SUM (حقوق / 100 * BonusPercent) [مجموع تمام پاداش ها] ، AVG (حقوق / 100 * BonusPercent) [اندازه متوسط پاداش] ، AVG ( حقوق) [متوسط حقوق] از کارمندان بیایید نگاهی به چگونگی پیدایش هر مقدار بازگشت بیاندازیم ، و برای مثال ، بیایید ساختارهای نحوی اساسی بیانیه SELECT را بیاد بیاوریم. اول ، به این دلیل ما شرایط مربوط به WHERE را در پرس و جو مشخص نکردیم ، سپس مجموع داده های مفصلی که توسط پرس و جو بدست می آید محاسبه می شود: * از بین کارمندان انتخاب کنید آنهایی که برای همه ردیف های جدول کارمندان. برای شفافیت ، ما فقط قسمتها و عباراتی را که در توابع جمع استفاده می شوند انتخاب می کنیم: SELECT DepartmentID، PositionID، BonusPercent، حقوق / 100 * BonusPercent، حقوق و دستمزد از کارمندان
این داده های اولیه (خطوط تفصیلی) است که به وسیله آنها کل پرس و جو جمع شده محاسبه می شود. حال بیایید نگاهی به هر مقدار جمع شده بیندازیم:
بیایید برخی از نتایج را خلاصه کنیم:
بر این اساس ، هنگام تعیین یک شرط اضافی با توابع جمع در بند WHERE ، فقط کل ردیف هایی که شرط را برآورده می کنند محاسبه می شود. آنهایی که محاسبه مقادیر جمع برای کل مجموعه انجام می شود ، که با استفاده از ساختار SELECT بدست می آید. به عنوان مثال ، بیایید همین کار را انجام دهیم ، اما فقط در زمینه بخش IT: COUNT را انتخاب کنید (*) [تعداد کل کارمندان] ، COUNT (DISTINCT DepartmentID) [تعداد بخشهای منحصر به فرد] ، COUNT (DISTINCT PositionID) [تعداد موقعیتهای منحصر به فرد] ، COUNT (BonusPercent) [تعداد کارمندان با٪ bonus] ، MAX (BonusPercent) [حداکثر درصد جایزه] ، MIN (BonusPercent) [حداقل درصد پاداش] ، SUM (حقوق / 100 * BonusPercent) [مجموع تمام پاداش ها] ، AVG (حقوق / 100 * BonusPercent) [اندازه متوسط پاداش] ، AVG ( حقوق) [میانگین حقوق] از کارمندان WHERE DepartmentID = 3 - فقط بخش IT را در نظر بگیرید SELECT DepartmentID، PositionID، BonusPercent، Salary / 100 * BonusPercent، حقوق و دستمزد از کارمندان WHERE DepartmentID = 3 - فقط شامل بخش IT است
برو جلو اگر تابع جمع NULL برگردد (به عنوان مثال ، همه کارمندان مقدار حقوق را مشخص نکرده اند) ، یا حتی یک رکورد در انتخاب گنجانده نشده است ، و در گزارش ، برای چنین موردی ، باید 0 را نشان دهیم ، سپس تابع ISNULL می تواند عبارت جمع را بپیچاند: SELECT SUM (حقوق) ، AVG (حقوق و دستمزد) ، - پردازش کل با استفاده از ISNULL ISNULL (SUM (حقوق و دستمزد) ، 0) ، ISNULL (AVG (حقوق و دستمزد) ، 0) از کارمندان WHERE DepartmentID = 10 - یک بخش موجود نیست به ویژه برای جلوگیری از بازگشت سوابق به سوابق ، در اینجا نشان داده شده است
من معتقدم که درک هدف هر تابع جمع و نحوه محاسبه آن بسیار مهم است ، زیرا در SQL ، این ابزار اصلی برای محاسبه کل است. در این حالت ، ما نحوه عملکرد هر یک از عملکردهای جمع را بررسی کردیم ، به عنوان مثال آن را به مقادیر کل مجموعه ضبط شده به دست آمده توسط دستور SELECT اعمال شد. در ادامه ، نحوه استفاده از همین توابع برای محاسبه کل گروهها با استفاده از بند GROUP BY را بررسی خواهیم کرد. GROUP BY - گروه بندی داده هاقبل از آن ، ما قبلاً مجموع مربوط به یک بخش خاص را محاسبه کرده ایم ، تقریباً به شرح زیر است:انتخاب تعداد (موقعیت متمایز) موقعیت ، تعداد ، تعداد (*) EmplCount ، مبلغ (حقوق و دستمزد) مبلغ مبلغ FROM از کارکنان WHERE DepartmentID = 3 - داده ها فقط برای بخش IT حال تصور کنید که از ما خواسته شده است که در متن هر بخش ، همان اعداد را بدست آوریم. البته ، ما می توانیم آستین بالا بزنیم و برای هر بخش درخواست مشابهی را برآورده کنیم. بنابراین ، زودتر از اتمام کار ، 4 درخواست می نویسیم: اطلاعات "اداره" را انتخاب کنید ، COUNT (موقعیت متمایز) PositionCount ، COUNT (*) EmplCount ، SUM (حقوق) حقوق و دستمزد مبلغ FROM از کارمندان WHERE DepartmentID = 1 - داده ها در مورد اداره اطلاعات "حسابداری" را انتخاب کنید ، COUNT (DISTINCT PositionID) PositionCount ، COUNT (* ) EmplCount ، SUM (حقوق و دستمزد) حقوق و دستمزد مبلغ FROM از کارکنان WHERE DepartmentID = 2 - داده های حسابداری اطلاعات "IT" را انتخاب کنید ، COUNT (DISTINCT PositionID) PositionCount ، COUNT (*) EmplCount ، SUM (حقوق) SalaryAmount FROM از کارکنان WHERE DepartmentID = 3 - داده ها در بخش IT اطلاعات "سایر" را انتخاب کنید ، COUNT (موقعیت DISTINCT) PositionCount ، COUNT (*) EmplCount ، SUM (حقوق) حقوق و دستمزد مبلغ FROM از کارمندان WHERE Departmentid NULL است - و داده های مربوط به فریلنسرها را فراموش نکنید در نتیجه ، ما 4 مجموعه داده دریافت می کنیم:
لطفا توجه داشته باشید که ما می توانیم از فیلدهای مشخص شده به عنوان ثابت استفاده کنیم - "اداره" ، "حسابداری" ، ... به طور کلی ، ما تمام اعدادی را که از ما خواسته شد استخراج کردیم ، ما همه چیز را در اکسل ترکیب می کنیم و به مدیر می دهیم. مدیر گزارش را پسندید ، و او می گوید: "و ستونی دیگر با اطلاعاتی در مورد میانگین حقوق اضافه کنید." و مثل همیشه ، این کار باید خیلی فوری انجام شود. هوم ، چه باید کرد؟! علاوه بر این ، بیایید تصور کنیم که ادارات ما 3 ، بلکه 15 نیستند. این دقیقاً همان چیزی است که بند GROUP BY برای چنین مواردی است: SELECT DepartmentID، COUNT (DISTINCT PositionID) PositionCount، COUNT (*) EmplCount، SUM (حقوق) SalaryAount، AVG (Salary) SalaryAgg - به علاوه ما خواسته های مدیر FROM Employees GROUP BY DepartmentID را برآورده می کنیم
ما همه داده های مشابه را بدست آوردیم ، اما اکنون فقط از یک درخواست استفاده می کنیم! در حال حاضر ، به این نکته توجه نکنید که بخشهای ما به صورت اعداد نمایش داده می شوند ، سپس یاد خواهیم گرفت که چگونه همه چیز را به زیبایی نمایش دهیم. در بند GROUP BY ، می توانید چندین فیلد "GROUP BY field1، field2، ...، fieldN" را تعیین کنید ، در این حالت گروه بندی توسط گروه هایی انجام می شود که مقادیر این فیلدها را تشکیل می دهند "field1، field2، .. .، fieldN ". به عنوان مثال ، بیایید داده ها را براساس گروه ها و گروه ها گروه بندی کنیم: SELECT DepartmentID ، PositionID ، COUNT (*) EmplCount ، SUM (حقوق) حقوق و دستمزد مبلغ FROM از کارکنان گروه توسط DepartmentID ، PositionID SELECT COUNT (*) EmplCount، SUM (حقوق) حقوق و دستمزد مبلغ FROM از کارمندانی که Departmentid NULL است و PositionID IS NULL است SELECT COUNT (*) EmplCount، SUM (حقوق) SalaAmount FROM از کارمندان WHERE DepartmentID = 1 و PositionID = 2 - ... انتخاب تعداد (*) EmplCount، SUM (حقوق) حقوق و دستمزد مبلغی از کارمندان WHERE DepartmentID = 3 AND PositionID = 4 و سپس همه این نتایج با هم ترکیب می شوند و به عنوان یک مجموعه در اختیار ما قرار می گیرند:
از مورد اصلی ، لازم به ذکر است که در مورد گروه بندی (GROUP BY) ، در لیست ستون ها در بلوک SELECT:
و نمایشی از همه آنچه گفته شد: انتخاب "رشته ثابت" Const1 ، - ثابت به شکل رشته 1 Const2 ، - ثابت به شکل یک عدد - عبارت با استفاده از زمینه های شرکت کننده در گروه CONCAT ("بخش شماره" ، DepartmentID) ConstAndGroupField ، CONCAT ("بخش شماره "، DepartmentID ،" ، Position No. "، PositionID) ConstAndGroupFields ، DepartmentID ، - فیلدی از لیست زمینه های شرکت کننده در گروه بندی - PositionID ، - فیلدی که در گروه بندی شرکت می کند ، لازم نیست در اینجا کپی کنید COUNT ( *) EmplCount ، - تعداد خطوط در هر گروه - از بقیه قسمتها فقط با توابع جمع می توان استفاده کرد: COUNT ، SUM ، MIN ، MAX ، ... SUM (حقوق) SalaryAmount ، MIN (ID) MinID از گروه کارمندان BY DepartmentID، PositionID - گروه بندی بر اساس قسمت ها DepartmentID، PositionID همچنین لازم به ذکر است که گروه بندی می تواند نه تنها توسط زمینه ها ، بلکه توسط عبارات نیز انجام شود. به عنوان مثال ، بیایید داده ها را براساس کارمندان ، براساس سال تولد گروه بندی کنیم: SELECT CONCAT ("سال تولد -" ، YEAR (روز تولد)) YearOfBirthday ، COUNT (*) EmplCount از گروه کارمندان براساس سال (تولد) بیایید به یک مثال با بیان پیچیده تر نگاه کنیم. به عنوان مثال ، اجازه دهید درجه کارکنان را براساس سال تولد دریافت کنیم: انتخاب پرونده WHEN YEAR (تولد)> = 2000 THEN "از 2000" WHEN YEAR (تولد)> = 1990 سپس "1999-1990" WHEN YEAR (تولد)> = 1980 سپس "1989-1980" WHEN YEAR (تولد)> = 1970 پس از آن "1979-1970" وقتی تولد آن بعد از آن خالی است "قبل از سال 1970" ELSE "مشخص نشده است" پایان دامنه نام ، تعداد (*) EmplCount از کارکنان گروه بر اساس مورد WHEN YEAR (تولد)> = 2000 THEN "از 2000" WHEN YEAN " (تولد)> = 1990 سپس "1999-1990" WHEN YEAR (تولد)> = 1980 سپس "1989-1980" WHEN YEAR (تولد)> = 1970 سپس "1979-1970" هنگامی که تولد پس از آن کامل نیست "قبل از 1970" دیگری "مشخص نشده" است پایان
آنهایی که در این حالت ، گروه بندی طبق عبارات CASE انجام می شود که قبلاً برای هر کارمند محاسبه شده است: شناسه را انتخاب کنید ، مورد WHEN YEAR (تولد)> = 2000 THEN "از 2000" WHEN YEAR (تولد)> = 1990 سپس "1999-1990" WHEN YEAR (تولد)> = 1980 سپس "1989-1980" WHEN YEAR (تولد) > = 1970 سپس "1979-1970" هنگامی که تولد آن بعد از آن تمام نمی شود "قبل از 1970" ELSE "مشخص نشده است" پایان کارمندان "
و البته ، می توانید عبارات را با فیلدها در بلوک GROUP BY ترکیب کنید: SELECT DepartmentID، CONCAT ("سال تولد -"، YEAR (تولد)) YearOfBirthday، COUNT (*) EmplCount از گروه کارکنان براساس سال (تولد)، DepartmentID - ممکن است این سفارش با ترتیب استفاده آنها در سفارش انتخاب منطبق نباشد با بلوک DepartmentID ، YearOfBirthday - سرانجام ، ما می توانیم مرتب سازی را برای نتیجه اعمال کنیم بیایید به کار اصلی خود برگردیم. همانطور که قبلاً می دانیم ، مدیر گزارش را بسیار پسندیده است ، و او از ما خواسته است که این کار را هفتگی انجام دهیم تا بتواند تغییرات شرکت را رصد کند. برای اینکه هر بار در Excel مقدار عددی دپارتمان را با نام آن قطع نکنیم ، ما از دانشی که در حال حاضر داریم استفاده خواهیم کرد و پرس و جو خود را بهبود می بخشیم: CASE را انتخاب کنید وقتی 1 بار "مدیریت" وقتی 2 "حساب" در صورت 3 "دیگر" دیگر "اطلاعات پایان ، تعداد (موقعیت متمایز) موقعیت ، تعداد ، تعداد (*) EmplCount ، مبلغ (حقوق) SalaAmount ، AVG (حقوق) ) SalaryAvg - به علاوه ما خواسته های مدیر FROM Employees GROUP BY DepartmentID ORDER BY Info را برآورده می کنیم - برای راحتی بیشتر مرتب سازی را بر اساس ستون Info اضافه کنید اما هیچ چیز ، با گذشت زمان ، ما یاد می گیریم که همه کارها را به زیبایی انجام دهیم ، به طوری که نمونه ما به ظاهر داده های جدید در پایگاه داده بستگی ندارد ، بلکه پویا است. من کمی جلوتر خواهم زد و نشان خواهم داد که چه نوع درخواست هایی را ارائه می دهیم: SELECT ISNULL (dep.Name، "Other") DepName، COUNT (DISTINCT emp.PositionID) PositionCount، COUNT (*) EmplCount، SUM (emp.Salary) SalaryAmount، AVG (emp.Salary) SalaryAvg - بعلاوه برآورده کردن خواسته های مدیر FROM Employees LEFT بپیوندید بخشهای بخش ON emp.DepartmentID = dep.ID GROUP BY emp.DepartmentID ، dep.Name ORDER BY DepName به طور کلی ، نگران نباشید - همه کار را ساده شروع کردند. در حال حاضر ، شما فقط باید اصل بند GROUP BY را درک کنید. در آخر ، بیایید ببینیم که چگونه می توانید گزارش های خلاصه را با استفاده از GROUP BY ایجاد کنید. به عنوان مثال ، بیایید یک جدول محوری را در متن بخش ها نمایش دهیم ، به طوری که کل حقوق دریافتی کارکنان بر اساس موقعیت محاسبه می شود: SELECT DepartmentID ، SUM (CASE WHEN PositionID = 1 THEN حقوق پایان یافته) [حسابداران] ، SUM (CASE WHEN PositionID = 2 THEN حقوق پس از پایان) [مدیران] ، SUM (CASE WHEN PositionID = 3 THEN حقوق پس از پایان) [برنامه نویسان] ، SUM ( CASE WHEN PositionID = 4 THEN حقوق و دستمزد پایان می یابد) [برنامه نویسان ارشد] ، SUM (حقوق و دستمزد) [مجموع بخش] از گروه کارمندان توسط DepartmentID البته می توانید با استفاده از IIF بازنویسی کنید: SELECT DepartmentID، SUM (IIF (PositionID = 1، حقوق، NULL)) [حسابدار]، SUM (IIF (PositionID = 2، حقوق، NULL)) [مدیران]، SUM (IIF (PositionID = 3، حقوق، NULL)) [برنامه نویسان] ، SUM (IIF (PositionID = 4 ، حقوق ، NULL))] [برنامه نویسان ارشد] ، SUM (حقوق و دستمزد) [مجموع بخش] از گروه کارمندان توسط DepartmentID اما در مورد IIF ، ما باید صریحاً NULL را مشخص كنیم كه در صورت عدم تحقق شرط بازگردانده می شود. در موارد مشابه ، من ترجیح می دهم از CASE بدون بلوک ELSE استفاده کنم تا اینکه یک بار دیگر NULL بنویسم. اما این مسلماً سلیقه ای است که در مورد آن بحث نمی شود. و بیاد داشته باشیم که مقادیر NULL در توابع تجمع در نظر گرفته نمی شوند. برای ادغام ، تجزیه و تحلیل مستقلی از داده های به دست آمده توسط درخواست توسعه یافته انجام دهید: SELECT DepartmentID، CASE WHEN PositionID = 1 THEN End End حقوق [حسابدار]، CASE WHE PositionID = 2 THEN حقوق پایان یافته [مدیران]، CASE WHEN PositionID = 3 THEN Salary End [برنامه نویسان]، CASE WHEN PositionID = 4 THEN Salary End [برنامه نویسان ارشد ] ، حقوق و دستمزد [مجموع بخش] از کارمندان
و همچنین بخاطر بسپاریم که اگر به جای NULL می خواهیم صفر ببینیم ، می توانیم مقدار برگردانده شده توسط تابع جمع را پردازش کنیم. مثلا: SELECT DepartmentID، ISNULL (SUM (IIF (PositionID = 1، حقوق، NULL))، 0) [حسابدار]، ISNULL (SUM (IIF (PositionID = 2، حقوق، NULL))، 0) [مدیران]، ISNULL (جمع) (IIF (PositionID = 3 ، حقوق ، NULL)) ، 0) [برنامه نویسان] ، ISNULL (SUM (IIF (PositionID = 4 ، حقوق ، NULL)) ، 0) [برنامه نویسان ارشد] ، ISNULL (جمع (حقوق) ، 0 ) [مجموع بخش] از گروه کارمندان توسط DepartmentID
GROUP BY در پراکنده با توابع جمع ، یکی از اصلی ترین ابزارهایی که برای بدست آوردن اطلاعات خلاصه از پایگاه داده استفاده می شود ، زیرا معمولاً داده ها در این فرم استفاده می شوند ، زیرا ما معمولاً ملزم به ارائه گزارش های خلاصه به جای داده های دقیق (ورق) هستیم. و البته ، همه اینها حول محور دانستن طرح اصلی است ، زیرا قبل از اینکه چیزی را خلاصه کنید (جمع کنید) ، ابتدا باید آن را با استفاده از "SELECT ... WHERE ..." به درستی انتخاب کنید. تمرین در اینجا نقش مهمی را ایفا می کند ، بنابراین ، اگر هدف خود را برای درک زبان SQL قرار دهید ، نه یادگیری ، بلکه درک آن - تمرین ، تمرین و تمرین ، گذراندن متفاوت ترین گزینه هایی که فکر می کنید. در مرحله اولیه ، اگر از صحت داده های جمع آوری شده به دست آمده مطمئن نیستید ، یک نمونه دقیق از جمله مقادیری را که تجمع برای آنها در حال انجام است ، تهیه کنید. و صحت محاسبات را با استفاده از این داده های دقیق به صورت دستی بررسی کنید. در این حالت استفاده از اکسل می تواند بسیار مفید باشد. بگذارید بگوییم شما به این مرحله رسیدیدبگذارید بگوییم شما یک حسابدار S. S. Sidorov هستید ، که تصمیم گرفته است نحوه نوشتن درخواستهای SELECT را بیاموزد.بگذارید بگوییم که شما قبلاً خواندن این آموزش را تا این مرحله به پایان رسانده اید ، و از قبل از استفاده از همه ساختارهای اساسی فوق اطمینان دارید ، یعنی تو می توانی:
بله ، اما آنها در نظر نگرفتند که شما هنوز نمی توانید از چندین جدول درخواست کنید ، اما فقط از یک جدول ، به عنوان مثال شما نمی دانید چطور چنین کاری انجام دهید: SELECT emp. * ، - تمام قسمتهای جدول Employees را برگردانید. نام DepartmentName ، - قسمت Name را از جدول Departments اضافه کنید. Name PositionName را به این قسمت ها اضافه کنید - و همچنین نام Name را از جدول Positions FROM Employees emp اضافه کنید LEFT JOIN دپارتمان های بخش ON emp.DepartmentID = dep.ID سمت چپ عضویت موقعیت های poz ON emp.PositionID = pos.ID بنابراین ، چگونه می توانید از دانش فعلی خود استفاده کرده و حتی نتایج پربارتری نیز بدست آورید؟! ما از قدرت ذهن جمعی استفاده خواهیم کرد - ما به سراغ برنامه نویسان می رویم که برای شما کار می کنند ، یعنی به Andreev A.A. ، Petrov P.P. یا Nikolayev N.N. ، و از یکی از آنها بخواهید که یک نمای برای شما بنویسد (VIEW یا به سادگی "View" ، بنابراین حتی سریعتر شما را درک می کنند) ، که علاوه بر زمینه های اصلی از جدول Employees ، زمینه ها را با "نام بخش" و "نام موقعیت" ، که اکنون برای گزارش هفتگی که ایوانف دوم برای شما بارگذاری کرده است ، فاقد آن هستید. زیرا شما همه چیز را به درستی توضیح دادید ، سپس متخصصان فناوری اطلاعات بلافاصله آنچه را که از آنها می خواهند فهمیدند و به ویژه برای شما دیدگاهی به نام ViewEmployeesInfo ایجاد کردند. ما نشان می دهیم که شما دستور بعدی را نمی بینید ، زیرا متخصصان فناوری اطلاعات این کار را انجام می دهند: ایجاد نمایی از ViewEmployeesInfo AS SELECT emp. * ، - تمام قسمتهای جدول Employees Dep را برگردانید. Name DepartmentName ، - قسمت Name را از قسمت Departments اضافه کنید. جدول Name Name Name نام را به این قسمت ها اضافه کنید - و همچنین نام Name را از جدول Positions FROM اضافه کنید Employees emp از سمت چپ بپیوندید به بخش ها در بخش emp.DepartmentID = dep.ID از سمت چپ بپیوندید موقعیت ها در ON emp.PositionID = pos.ID آنهایی که برای همه شما ، هرچند ترسناک و قابل درک نیست ، متن خارج از صفحه باقی می ماند و متخصصان فناوری اطلاعات فقط نام نمای "ViewEmployeesInfo" را به شما می دهند که تمام داده های فوق را برمی گرداند (یعنی آنچه شما از آنها خواسته اید). اکنون می توانید مانند این جدول منظم با این نمای کار کنید: انتخاب * از ViewEmployeesInfo SELECT DepartmentName، COUNT (DISTINCT PositionID) PositionCount، COUNT (*) EmplCount، SUM (حقوق) SalaryAmount، AVG (حقوق) حقوق Avg FROM ViewEmployeesInfo emp GROUP BY DepartmentID، DepartmentName ORDER BY DepartmentName آنهایی که برای شما در این حالت ، مثل اینکه چیزی تغییر نکرده باشد ، شما با یک جدول کار می کنید (اما گفتن با نمای ViewEmployeesInfo درست تر است) ، که تمام داده های شما را برمی گرداند. با تشکر از کمک متخصصان IT ، جزئیات استخراج DepartmentName و PositionName در یک جعبه سیاه برای شما باقی می ماند. آنهایی که نمای شما به عنوان یک جدول معمولی یکسان است ، آن را یک نسخه گسترده از جدول کارمندان بدانید. به عنوان مثال ، بیایید بیانیه ای تشکیل دهیم ، تا مطمئن شوید همه چیز همانطور که گفتم واقعاً است (که کل نمونه از یک نمای بدست می آید): شناسه ، نام ، حقوق و دستمزد را از طریق مشاهده کارمندان در مورد WHERE Salary is NULL AND حقوق و دستمزد انتخاب کنید> 0 سفارش به نام استفاده از نماها در بعضی موارد باعث می شود مرزهای کاربرانی که می دانند چگونه نوشتن درخواست های اساسی SELECT را انجام دهند ، به طور قابل توجهی گسترش یابد. در این حالت ، نمای یک جدول مسطح با تمام داده های مورد نیاز کاربر است (برای کسانی که OLAP را درک می کنند ، این را می توان با تقریب مکعب OLAP با حقایق و ابعاد مقایسه کرد). برش از ویکی پدیا.اگرچه SQL به عنوان ابزاری برای کاربر نهایی تصور می شد ، اما در نهایت چنان پیچیده شد که به ابزار برنامه نویس تبدیل شد. همانطور که مشاهده می کنید ، کاربران گرامی ، زبان SQL در ابتدا به عنوان ابزاری برای شما در نظر گرفته شده است. بنابراین ، همه چیز در دست شما و آرزو است ، رها نکنید. HAVING - تحمیل شرط انتخاب بر داده های گروه بندی شدهدر واقع ، اگر می فهمید که یک گروه چیست ، پس HAVING هیچ چیز پیچیده ای ندارد. HAVING تا حدی شبیه WHERE است ، فقط اگر شرط WHERE روی داده های دقیق اعمال شود ، سپس شرایط HAVING روی داده های قبلاً گروه بندی شده اعمال می شود. به همین دلیل ، در شرایط بلوک HAVING ، می توانیم از عبارات دارای فیلدهای موجود در گروه بندی یا عبارات محصور در توابع جمع استفاده کنیم.بیایید یک مثال را در نظر بگیریم: SELECT DepartmentID، SUM (حقوق) حقوق و دستمزد مبلغ FROM از کارکنان گروه توسط Departmentid با داشتن مبلغ (حقوق)> 3000
آنهایی که این درخواست داده های گروه بندی شده را فقط برای آن بخشهایی که کل حقوق و دستمزد همه کارمندان بیش از 3000 است ، به ما بازگردانده است. "SUM (حقوق)> 3000".
آنهایی که در اینجا ، اول از همه ، گروه بندی انجام می شود و داده های همه بخش ها محاسبه می شود: SELECT DepartmentID ، SUM (حقوق و دستمزد) حقوق و دستمزد مبلغ FROM از کارکنان گروه توسط DepartmentID - 1. دریافت داده های گروه بندی شده برای همه بخش ها و از قبل شرایط مشخص شده در بلوک HAVING روی این داده ها اعمال شده است: SELECT DepartmentID، SUM (حقوق) حقوق و دستمزد مبلغ FROM از کارکنان گروه توسط DepartmentID - 1. دریافت داده های گروه بندی شده برای همه بخش ها با داشتن SUM (حقوق)> 3000 - 2. شرط فیلتر کردن داده های گروه بندی شده در شرایط HAVING ، می توانید با استفاده از عملگرهای AND ، OR و NOT شرایط پیچیده ای نیز ایجاد کنید: SELECT DepartmentID ، SUM (حقوق) حقوق و دستمزد مبلغ FROM از کارکنان گروه توسط Departmentid با داشتن مبلغ (حقوق)> 3000 و تعداد (*)<2 -- и число людей меньше 2-х
همانطور که در اینجا مشاهده می کنید تابع جمع (به "COUNT (*)" مراجعه کنید) فقط در بلوک HAVING قابل تعیین است. بر این اساس ، ما فقط می توانیم تعداد دپارتمان هایی را که مطابق با شرایط HAVING است نمایش دهیم: SELECT DepartmentID از گروه کارمندان براساس Departmentid با داشتن مبلغ (حقوق)> 3000 و تعداد (*)<2 -- и число людей меньше 2-х نمونه ای از استفاده از شرط HAVING در فیلدی که در GROUP BY گنجانده شده است: SELECT DepartmentID، SUM (حقوق) حقوق و دستمزد مبلغ FROM از کارکنان گروه توسط DepartmentID - 1. گروه بندی کنید HAVING DepartmentID = 3 - 2. نتیجه گروه بندی را فیلتر کنید این فقط یک مثال است ، از در این مورد ، منطقی تر است که از طریق شرایط WHERE بررسی کنید: SELECT DepartmentID، SUM (حقوق) حقوق و دستمزد مبلغ FROM از کارکنان WHERE DepartmentID = 3 - 1. فیلتر کردن اطلاعات دقیق GROUP BY DepartmentID - 2. گروه بندی فقط با سوابق انتخاب شده آنهایی که ابتدا کارمندان را توسط بخش 3 فیلتر کنید و فقط پس از آن محاسبه کنید. توجه داشته باشید.در حقیقت ، حتی اگر دو پرس و جو متفاوت به نظر برسند ، بهینه ساز DBMS می تواند آنها را به همان روش اجرا کند. من فکر می کنم اینجاست که داستان درباره شرایط داشتن به پایان می رسد. بیایید خلاصه کنیمبیایید داده های بدست آمده در قسمت های دوم و سوم را خلاصه کنیم و موقعیت خاص هر سازه ای را که مورد مطالعه قرار دادیم در نظر بگیریم و ترتیب اجرای آنها را نشان دهیم:
البته می توانید بندهای DISTINCT و TOP را که در قسمت دوم آموخته اید نیز برای داده های گروه بندی شده اعمال کنید. این پیشنهادات در این مورد برای نتیجه نهایی اعمال می شود: TOP 1 - 6 را انتخاب کنید. 6 آخرین SUM (حقوق و دستمزد) را اعمال می کند مبلغ FROM از کارکنان گروه توسط Departmentid با داشتن مبلغ (حقوق)> 3000 سفارش توسط DepartmentID - 5. مرتب سازی بر اساس نتیجه چگونگی بدست آوردن این نتایج را خودتان تحلیل کنید. نتیجههدف اصلی که من در این قسمت تعیین کردم این است که ماهیت توابع و گروه بندی های کل را برای شما فاش کنم.اگر طراحی اصلی به ما امکان می داد داده های دقیق لازم را بدست آوریم ، پس استفاده از توابع و گروه بندی های کل روی این داده های دقیق این فرصت را به ما می دهد که داده های خلاصه ای را درباره آنها بدست آوریم. همانطور که می بینید ، اینجا همه چیز مهم است ، tk. یکی مبتنی بر دیگری است - بدون اطلاع از ساختار اساسی ، ما قادر نخواهیم بود به عنوان مثال ، داده هایی را که برای محاسبه کل آنها نیاز داریم به درستی انتخاب کنیم. در اینجا ، من عمدا سعی می کنم فقط اصول را نشان دهم ، بنابراین توجه مبتدی را به مهمترین ساختارها متمرکز می کنم و آنها را با اطلاعات غیر ضروری پر نمی کنم. درک صحیح از ساختارهای اساسی (که در بخشهای بعدی در مورد آنها صحبت خواهم کرد) به شما این امکان را می دهد که تقریباً هر مشکلی در واکشی داده ها از RDB را حل کنید. ساختارهای اساسی بیانیه SELECT تقریباً در همه DBMS به همان شکل قابل اجرا است (تفاوت ها عمدتا در جزئیات نهفته است ، به عنوان مثال در اجرای توابع - برای کار با رشته ها ، زمان و غیره). متعاقباً ، دانش کافی در مورد پایه به شما این فرصت را می دهد تا به راحتی و به تنهایی پسوندهای مختلف زبان SQL را یاد بگیرید ، مانند:
اگر اولین قدم های خود را در SQL برمی دارید ، ابتدا در یادگیری سازه های اصلی تمرکز کنید. داشتن پایگاه ، درک همه موارد دیگر برای شما بسیار آسان تر خواهد بود ، و علاوه بر این ، به تنهایی. اول از همه ، شما باید توانایی های زبان SQL را درک کنید ، یعنی چه نوع عملیاتی به طور کلی اجازه می دهد تا بر روی داده انجام شود. انتقال اطلاعات به افراد مبتدی به صورت گسترده یکی دیگر از دلایلی است که من فقط مهمترین ساختارها (آهن) را نشان می دهم. موفق باشید زبان SQL را یاد بگیرید و درک کنید. قسمت چهارم - تیم CASE به شما امکان انتخاب می دهد یکیاز توالی دستورات متعدد... این سازه از سال 1992 در استاندارد SQL وجود دارد ، اگرچه در Oracle SQL تا زمان Oracle8i و در PL / SQL تا زمان انتشار Oracle9i پشتیبانی نمی شد. با شروع این نسخه ، انواع زیر دستورات CASE پشتیبانی می شوند:
NULL یا ناشناخته؟در مقاله بیانیه IF ، ممکن است یاد گرفته باشید که نتیجه عبارت Boolean می تواند درست ، نادرست یا NULL باشد. در PL / SQL ، این درست است ، اما در زمینه گسترده تر نظریه رابطه ای ، صحبت در مورد بازگشت NULL از یک عبارت بولی نادرست تلقی می شود. تئوری رابطه می گوید که مقایسه با NULL به این صورت است: 2 < NULL نتیجه منطقی را "ناشناخته" می دهد و "ناشناخته" NULL نیست. با این حال ، شما نباید زیاد نگران استفاده PL / SQL از NULL برای ناشناخته باشید. با این حال ، باید توجه داشته باشید که سومین مقدار در منطق 3-ارزش ناشناخته است. و امیدوارم که هرگز (مانند من!) هنگام بحث در مورد منطق 3-ارزشمند با متخصصان حوزه تئوری رابطه ، خود را در اصطلاح غلط گیر ندهید. علاوه بر دستورات CASE ، PL / SQL از عبارات CASE نیز پشتیبانی می کند. این عبارت بسیار شبیه دستور CASE است ، به شما امکان می دهد یک یا چند عبارت را برای ارزیابی انتخاب کنید. نتیجه عبارت CASE یک مقدار است ، در حالی که نتیجه دستور CASE اجرای دنباله ای از دستورات PL / SQL است. دستورات CASE سادهیک دستور ساده CASE به شما امکان می دهد یکی از چندین توالی دستورات PL / SQL را انتخاب کنید تا براساس نتیجه ارزیابی یک عبارت اجرا شود. به شرح زیر نوشته شده است: CASE عبارت WHEN result_1 THEN command_1 WHEN result_2 THEN command_2 ... ELSE command_else پایان پرونده ؛ شعبه ELSE در اینجا اختیاری است. هنگام اجرای چنین دستوری ، PL / SQL ابتدا عبارت را ارزیابی می کند و سپس نتیجه را با result_1 مقایسه می کند. در صورت مطابقت ، دستورات_1 اجرا می شوند. در غیر این صورت مقدار value_2 علامت گذاری می شود و موارد دیگر. در اینجا مثالی از دستور CASE ساده آورده شده است که در آن پاداش بسته به مقدار متغیر نوع_کارمند محاسبه می شود: CASE نوع کارمند WHEN "S" THEN Award_salary_bonus (ID_کارمند)؛ WHEN "H" THEN Award_hourly_bonus (کارمند_id) WHEN "C" THEN Award_commissioned_bonus (کارمند_id) نوع دیگر RAIDE invalid_employee_؛ پرونده پایان؛ در این مثال ، یک بند ELSE صریح وجود دارد ، اما به طور کلی لازم نیست. بدون بند ELSE ، کامپایلر PL / SQL به طور ضمنی کد زیر را جایگزین می کند: مورد دیگر افزایش :_NOT_FOUND؛ به عبارت دیگر ، اگر کلمه کلیدی ELSE را حذف کنید و اگر هیچ یک از نتایج بندهای WHEN با نتیجه عبارت در دستور CASE مطابقت نداشته باشد ، PL / SQL یک استثنا CASE_NOT_FOUND را مطرح می کند. این تفاوت این دستور با IF است. وقتی کلمه کلیدی ELSE در دستور IF وجود ندارد ، در صورت عدم تحقق شرط هیچ اتفاقی نمی افتد ، در حالی که در دستور CASE ، وضعیت مشابه منجر به خطا می شود. جالب است که ببینید چگونه می توان منطق محاسبه پاداش را که در ابتدای فصل توصیف شده است با استفاده از یک دستور CASE ساده پیاده سازی کرد. در نگاه اول ، این امر غیرممکن به نظر می رسد ، اما با خلاقیت وارد کار می شویم ، به راه حل زیر می رسیم: CASE TRUE WHEN حقوق و دستمزد> = 10000 و حقوق و دستمزد<=20000 THEN give_bonus(employee_id, 1500); WHEN salary >20،000 و حقوق و دستمزد<= 40000 THEN give_bonus(employee_id, 1000); WHEN salary >40000 THEN give_bonus (کارمند_id ، 500) ELSE give_bonus (کارمند_id ، 0) ؛ پرونده پایان؛ نکته مهم در اینجا این است که عناصر بیان و نتیجه می توانند مقادیر مقیاسی یا عباراتی باشند که نتایج آنها مقیاس مقیاسی هستند. بازگشت به دستور IF ... THEN ... ELSIF ، که همان منطق را پیاده سازی می کند ، خواهید دید که بخش ELSE در دستور CASE تعریف شده است ، در حالی که کلمه کلیدی ELSE در دستور IF - THEN - ELSIF وجود ندارد. دلیل اضافه کردن ELSE ساده است: اگر هیچ یک از شرایط جایزه برآورده نشود ، دستور IF هیچ کاری انجام نمی دهد و پاداش صفر است. در این حالت ، دستور CASE خطایی ایجاد می کند ، بنابراین وضعیت با حق بیمه صفر باید به طور صریح برنامه ریزی شود. برای جلوگیری از خطاهای CASE_NOT_FOUND ، اطمینان حاصل کنید که حداقل یکی از شرایط برای هر مقدار از عبارتی که در حال آزمایش است برآورده شده است. دستور CASE TRUE فوق العاده ممکن است برای برخی مانند یک حیله باشد ، اما در واقع فقط دستور جستجوی CASE را پیاده سازی می کند ، که در بخش بعدی در مورد آن صحبت خواهیم کرد. دستور جستجوی CASEدستور CASE لیستی از عبارات بولی را بررسی می کند. با یافتن عبارتی برابر با TRUE ، توالی دستورات مرتبط با آن را اجرا می کند. در اصل ، دستور CASE مشابه دستور CASE TRUE است که در قسمت قبل نشان داده شده است. دستور جستجوی CASE دارای نشانه زیر است: CASE WHEN expression_1 THEN command_1 WHEN expression_2 THEN command_2 ... ELSE command_else پایان پرونده ؛ این برای اجرای منطق تعهد پاداش ایده آل است: CASE WHEN حقوق و دستمزد> = 10000 و حقوق<=20000 THEN give_bonus(employee_id, 1500); WHEN salary >20،000 و حقوق و دستمزد<= 40000 THEN give_bonus(employee_id, 1000); WHEN salary >40000 THEN give_bonus (کارمند_id ، 500) ELSE give_bonus (کارمند_id ، 0) ؛ پرونده پایان؛ دستور CASE جستجو ، مانند یک دستور ساده ، از قوانین زیر پیروی می کند:
اجرای دیگری از منطق محاسبه پاداش را در نظر بگیرید که از این واقعیت استفاده می کند که شرایط WHEN به ترتیب نوشته شده بررسی می شود. عبارات فردی ساده ترند ، اما آیا می توانیم بگوییم که معنی کل دستور روشن تر شده است؟ CASE WHEN حقوق و دستمزد> 40000 THEN give_bonus (پیشنهاد کارمند ، 500)؛ WHEN حقوق و دستمزد> 20000 THEN give_bonus (کارت کاربری ، 1000) WHEN حقوق> = 10000 THEN give_bonus (کارمند_id ، 1500) ELSE give_bonus (کارمند_id ، 0) ؛ پرونده پایان؛ اگر یک کارمند خاص 20،000 حقوق و دستمزد داشته باشد ، دو شرط اول نادرست و سوم شرط واقعی است ، بنابراین کارمند پاداش 1500 دلار دریافت می کند. اگر حقوق 21000 باشد ، نتیجه شرط دوم واقعی خواهد بود و پاداش 1000 دلار خواهد بود. اجرای دستور CASE در شاخه WHEN دوم خاتمه می یابد و شرط سوم حتی بررسی نمی شود. اینکه آیا هنگام نوشتن دستورات CASE باید از این روش استفاده شود یا خیر ، یک بحث است. به همین ترتیب ، به خاطر داشته باشید که نوشتن چنین دستوری امکان پذیر است و هنگام اشکال زدایی و ویرایش برنامه هایی که نتیجه آنها به ترتیب عبارات بستگی دارد ، مراقبت ویژه ای لازم است. منطقی که به ترتیب تقسیم شاخه های WHEN بستگی دارد منبع احتمالی خطاهایی است که از چینش مجدد آنها ناشی می شود. به عنوان مثال ، دستور CASE زیر را در نظر بگیرید ، که در آن ، با حقوق 20،000 ، بررسی شرایط هر دو بند WHEN به TRUE ارزیابی می شود: CASE WHEN حقوق و دستمزد بین 10000 و 20000 THEN give_bonus (آگهی کارمند ، 1500) وقتی حقوق و دستمزد بین 20000 و 40000 THEN give_bonus (کارمند_id ، 1000) ... تصور کنید که نگهدارنده این برنامه با مرتباً بندهای WHEN را مرتب می کند تا آنها را به ترتیب نزولی حقوق تعیین کند. این احتمال را رد نکنید! برنامه نویسان غالباً تمایل دارند که بر اساس نوعی از سفارش داخلی ، به راحتی کد کار کنند. یک دستور CASE با تنظیم مجدد بندهای WHEN به این شکل است: CASE WHEN حقوق و دستمزد بین 20000 و 40000 THEN give_bonus (شناسنامه کارمند ، 1000)؛ هنگامی که حقوق بین 10000 و 20000 THEN give_bonus (کارمند_id ، 1500) ... در نگاه اول همه چیز درست است ، نه؟ متأسفانه ، به دلیل همپوشانی دو شاخه WHEN ، یک خطای موذی در برنامه ظاهر می شود. اکنون یک کارمند با حقوق 20،000 به جای 1500 مورد نیاز ، پاداش 1000 دریافت خواهد کرد. ممکن است در برخی شرایط مطلوب باشد که بین شعب WHEN هم پوشانی داشته باشد ، اما در هر صورت امکان از این کار خودداری شود. همیشه بخاطر بسپارید که سفارش شعبه مهم است و اشتیاق خود را برای تغییر کد موجود از کار بازدارید - "آنچه خراب نشده را اصلاح نکنید". از آنجا که شرایط WHEN به ترتیب آزمایش شده است ، می توانید با قرار دادن شاخه های دارای بیشترین شرایط در بالای لیست ، کارایی کد خود را کمی بهبود ببخشید. علاوه بر این ، اگر شاخه ای با عبارات "گران" دارید (مثلاً به CPU و حافظه قابل توجهی نیاز دارید) ، می توانید آنها را در انتها قرار دهید تا احتمال آزمایش آنها به حداقل برسد. برای جزئیات به بخش دستورات Nested IF مراجعه کنید. دستورات جستجوی CASE هنگامی استفاده می شوند که دستوراتی که باید توسط مجموعه ای از عبارات منطقی تعریف شوند. وقتی تصمیم بر اساس نتیجه یک عبارت واحد گرفته می شود ، از یک دستور ساده CASE استفاده می شود.
دستورات تو در تودستورات CASE مانند دستورات IF می توانند تو در تو قرار بگیرند. به عنوان مثال ، دستور تو در تو CASE در پیاده سازی زیر (نسبتاً گیج کننده) منطق پاداش ظاهر می شود: CASE WHEN حقوق و دستمزد> = 10000 THEN CENE WHEN حقوق<= 20000 THEN give_bonus(employee_id, 1500); WHEN salary >40000 THEN give_bonus (کارمند_id ، 500) WHEN حقوق و دستمزد> 20000 THEN give_bonus (کارت کاربری ، 1000) پرونده پایان؛ حقوق کی< 10000 THEN give_bonus(employee_id,0); END CASE; از هر دستوری می توان در دستور CASE استفاده کرد ، بنابراین دستور CASE داخلی به راحتی با دستور IF جایگزین می شود. به همین ترتیب ، هر دستوری می تواند درون یک دستور IF قرار گیرد ، از جمله CASE. عبارات CASEعبارات CASE وظیفه مشابه دستورات CASE را انجام می دهند ، اما نه برای دستورات اجرایی ، بلکه برای عبارات. یک عبارت ساده CASE بر اساس مقدار مقیاس مشخص شده ، یکی از چندین عبارت را برای ارزیابی انتخاب می کند. یک عبارت جستجو CASE عبارات موجود در لیست را به ترتیب ارزیابی می کند تا زمانی که یکی از آنها به TRUE ارزیابی شود و سپس نتیجه عبارت مرتبط را برمی گرداند. نحو این دو طعم عبارت CASE به شرح زیر است: Simple_Case_expression: = CASE عبارت WHEN result_1 THEN result_expression_1 WHEN result_2 THEN result_expression_2 ... ELSE result_expression_else END؛ Search_Case_expression: = CASE WHEN expression_1 THEN result_expression_1 WHEN expression_2 THEN result_expression_2 ... ELSE result_expression_else END؛ یک عبارت CASE یک مقدار برمی گرداند - نتیجه عبارتی که برای ارزیابی انتخاب شده است. هر بند WHEN باید با یک عبارت نتیجه همراه باشد (اما نه یک دستور). در انتهای عبارت CASE هیچ نقطه ویرگول یا END CASE وجود ندارد. عبارت CASE با کلمه کلیدی END به پایان می رسد. در زیر مثالی از یک عبارت CASE ساده به کار رفته است که همراه با رویه PUT_LINE بسته DBMS_OUTPUT برای نمایش مقدار متغیر Boolean است. اعلام Boolean_true BOOLEAN: = TRUE؛ boolean_false BOOLEAN: = FALSE؛ boolean_null BOOLEAN؛ FUNCTION boolean_to_varchar2 (پرچم در BOOLEAN) بازگشت VARCHAR2 آغاز می شود بازگشت پرونده پرچم WHEN TRUE THEN "درست" هنگامی که نادرست سپس "False" ELSE "NULL" پایان؛ پایان؛ BEGIN DBMS_OUTPUT.PUT_LINE (boolean_to_varchar2 (boolean_true)) ؛ DBMS_OUTPUT.PUT_LINE (boolean_to_varchar2 (boolean_false)) ؛ DBMS_OUTPUT.PUT_LINE (boolean_to_varchar2 (boolean_null)) ؛ پایان؛ برای پیاده سازی منطق محاسبه پاداش ها ، می توانید از عبارت جستجوی CASE استفاده کنید که مقدار پاداش یک حقوق معین را برمی گرداند: اعلام شماره حقوق و دستمزد: = 20000؛ تعداد کارمندان_ شماره: = 36325؛ PROCEDURE give_bonus (emp_id به تعداد ، جایزه_بعد به تعداد) شروع می شود DBMS_OUTPUT.PUT_LINE (emp_id) ؛ DBMS_OUTPUT.PUT_LINE (جایزه_امت)؛ پایان؛ BEGIN give_bonus (کارمند_id ، CASE WHEN حقوق> = 10000 و حقوق و دستمزد<= 20000 THEN 1500 WHEN salary >20،000 و حقوق و دستمزد<= 40000 THEN 1000 WHEN salary >40،000 THEN 500 ELSE 0 END) ؛ پایان؛ در هر کجا که عبارات از هر نوع دیگری استفاده شود ، می توان از عبارت CASE استفاده کرد. مثال زیر برای محاسبه حق بیمه ، ضرب آن در 10 و انتساب نتیجه به متغیری که توسط DBMS_OUTPUT نمایش داده می شود ، از عبارت CASE استفاده می کند: اعلام شماره حقوق و دستمزد: = 20000؛ تعداد کارمندان_کاربر: = 36325؛ مبلغ_نمایش NUMBER؛ مبنای bonus_amount: = CASE WHEN حقوق> = 10000 و حقوق<= 20000 THEN 1500 WHEN salary >20،000 و حقوق و دستمزد<= 40000 THEN 1000 WHEN salary >40000 THEN 500 ELSE 0 END * 10 ؛ DBMS_OUTPUT.PUT_LINE (مقدار جایزه) پایان؛ برخلاف دستور CASE ، در صورت عدم رعایت بند WHEN ، عبارت CASE خطایی ایجاد نمی کند ، بلکه به سادگی NULL را برمی گرداند. محبوب
جدید در سایت
|