CASE shartli ifodalar. CASE shartli ifodalari CASE ifodasi SQL tilining shartli bayonotidir
CASE ifodasi
DECODE funktsiyasi
Ikki usul qo'llaniladi:
SQL operatorida shartli ishlov berishni (IF-THEN-ELSE mantiqi) amalga oshirish uchun ikkita usul CASE ifodasi va DECODE funktsiyasidir.
Eslatma: CASE ifodasi ANSI SQL ga mos keladi. DECODE funksiyasi Oracle sintaksisiga xosdir.
CASE ifodasi
IF-THEN-ELSE operatorini ishlash orqali shartli so'rovlarni soddalashtiradi:
CASE ifodalari IF-THEN-ELSE mantiqidan SQL operatorlarida protseduralarni chaqirmasdan foydalanish imkonini beradi.
Oddiy qilib shartli ifoda CASE Oracle Server birinchi QAChON ... keyin juftlikni qidiradi, buning uchun ifoda solishtirma_ifodaga teng va return_exprni qaytaradi. Agar WHEN ... THEN juftliklaridan hech biri bu shartni qondirmasa va else bandi mavjud bo'lsa, Oracle else_expr ni qaytaradi. Aks holda, Oracle nullni qaytaradi. Barcha return_exprs va else_expr uchun NULLni belgilay olmaysiz.
Expr va comparison_expr bir xil maʼlumotlar turi boʻlishi kerak, ular CHAR, VARCHAR2, NCHAR yoki NVARCHAR2 boʻlishi mumkin. Barcha qaytish qiymatlari (return_expr) bir xil ma'lumotlar turiga ega bo'lishi kerak.
Ushbu sintaksisda Oracle kirish ifodasini (e) har bir taqqoslash ifodasi e1, e2, ..., en bilan solishtiradi.
Agar kirish ifodasi har qanday taqqoslash ifodasiga teng bo'lsa, CASE ifodasi mos keladigan natija ifodasini (r) qaytaradi.
Agar e kiritish ifodasi hech qanday taqqoslash ifodasiga mos kelmasa, CASE ifodasi ELSE bandi mavjud bo'lsa, ELSE bandidagi ifodani qaytaradi, aks holda u null qiymatni qaytaradi.
Oracle oddiy CASE ifodasi uchun qisqa tutashuvni baholashdan foydalanadi. Bu shuni anglatadiki, Oracle har bir taqqoslash ifodasini (e1, e2, .. en) faqat ulardan birini kirish ifodasi (e) bilan solishtirishdan oldin baholaydi. Oracle barcha taqqoslash iboralarini (e) ifodasi bilan solishtirishdan oldin baholamaydi. Natijada, Oracle hech qachon taqqoslash ifodasini baholamaydi, agar avvalgisi kirish ifodasiga (e) teng bo'lsa.
Oddiy CASE ifoda misoli
Namoyish uchun mahsulot jadvalidan foydalanamiz.
Quyidagi so‘rov har bir mahsulot toifasi uchun chegirmani hisoblash uchun CASE ifodasidan foydalanadi, ya’ni CPU 5%, video karta 10% va boshqa mahsulot toifalari 8%
TANLASH CASE turkumi_id QACHON 1 KEYIN ROUND (ro'yxat_narxi * 0.05,2) - CPU QACHON 2 KEYIN ROUND (Ro'yxat_narxi * 0.1,2) - Video karta BOSHQA ROUND (roʻyxat_narxi * 0.08,2) - boshqa toifalar END chegirma FROM Buyurtma berish |
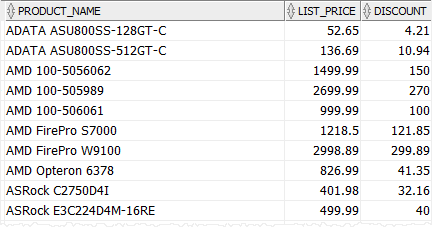
E'tibor bering, biz chegirmani ikki kasrgacha yaxlitlash uchun ROUND () funksiyasidan foydalanganmiz.
CASE ifodasi qidirildi
Oracle qidiruvi CASE ifodasi natijani aniqlash uchun mantiqiy ifodalar roʻyxatini baholaydi.
Qidirilgan CASE bayonoti quyidagi sintaksisga ega:
HOLDA QACHON e1Keyin r1 , COUNT (DISTINCT DepartamentID) [Noyob bo‘limlar soni], COUNT (DISTINCT PositionID) [Noyob lavozimlar soni], COUNT (BonusPercent) [Bonus% bo‘lgan xodimlar soni], MAX (BonusPercent) [Maksimal Bonus Foiz], MIN (Bonus foiz) BonusPercent) [Minimal bonus foizi], SUM (Ish haqi / 100 * BonusPercent) [Barcha bonuslar yig‘indisi], AVG (Ish haqi / 100 * Bonusfoiz) [O‘rtacha bonus], AVG (Ish haqi) [O‘rtacha ish haqi] Xodimlardan Keling, har bir qaytarish qiymati qanday paydo bo'lganini ko'rib chiqaylik va birinchi navbatda, SELECT iborasining asosiy sintaksisining konstruktsiyalarini eslaylik. Birinchidan, chunki biz so'rovda QAYER shartlarini belgilamadik, keyin so'rov orqali olingan batafsil ma'lumotlar uchun jami hisoblab chiqiladi: Xodimlardan * ni tanlang Bular. Xodimlar jadvalining barcha qatorlari uchun. Aniqlik uchun biz faqat agregat funktsiyalarda ishlatiladigan maydonlar va iboralarni tanlaymiz: Departament identifikatori, Lavozim identifikatori, BonusFoiz, Ish haqi / 100 * BonusFoiz, Xodimlardan ish haqi
Bu yig'ilgan so'rovning umumiy summasi hisoblab chiqiladigan dastlabki ma'lumotlar (batafsil chiziqlar). Endi har bir jamlangan qiymatni ko'rib chiqamiz:
Keling, ba'zi natijalarni umumlashtiramiz:
Shunga ko'ra, WHERE bandida agregat funktsiyalari bilan qo'shimcha shartni belgilashda faqat shartni qondiradigan qatorlar uchun yig'indisi hisoblanadi. Bular. agregat qiymatlarni hisoblash SELECT konstruktsiyasi yordamida olingan umumiy to'plam uchun amalga oshiriladi. Misol uchun, xuddi shunday qilaylik, lekin faqat IT bo'limi kontekstida: COUNT (*) [Xodimlarning umumiy soni], COUNT (DISTINCT Departament identifikatori) [Noyob bo‘limlar soni], COUNT (DISTINCT PositionID) [Noyob lavozimlar soni], COUNT (Bonus foiz) [Bonus %li xodimlar soni] , MAX. (BonusPercent) [Maksimal bonus foizi], MIN (BonusPercent) [Minimal bonus foizi], SUM (Ish haqi / 100 * BonusPercent) [Barcha bonuslar yig‘indisi], AVG (Ish haqi / 100 * BonusPercent) [O‘rtacha bonus hajmi], AVG ( Ish haqi) [O'rtacha ish haqi] QAYERDA bo'lgan xodimlardan ID = 3 - Faqat IT bo'limini ko'rib chiqing Departament identifikatori, Lavozim identifikatori, BonusFoiz, Ish haqi / 100 * BonusFoiz, Xodimlardan olingan maosh QAYERDA bo'limID = 3 - faqat IT bo'limini hisobga oling
Davom etish. Agar agregat funktsiyasi NULL qiymatini qaytarsa (masalan, barcha xodimlarning ish haqi qiymati ko'rsatilgan bo'lmasa) yoki tanlovga bitta yozuv kiritilmagan bo'lsa va hisobotda bunday holat uchun biz 0 ni ko'rsatishimiz kerak, keyin ISNULL funktsiyasi agregat ifodani o'rashi mumkin: SUM (Ish haqi), AVG (ish haqi), - jami ma'lumotlarni ISNULL ISNULL (SUM (ish haqi), 0), ISNULL (AVG (ish haqi), 0) yordamida qayta ishlang. so'rovning yozuvlarni qaytarishiga yo'l qo'ymaslik uchun bu erda ko'rsatilgan
Men har bir agregat funktsiyasining maqsadini va uni qanday hisoblashini tushunish juda muhim deb hisoblayman, chunki SQL-da u umumiy miqdorlarni hisoblash uchun asosiy vositadir. Bunday holda, biz har bir agregat funktsiyaning mustaqil ravishda qanday harakat qilishini ko'rib chiqdik, ya'ni. u SELECT buyrug'i bilan olingan barcha yozuvlar to'plamining qiymatlariga qo'llaniladi. Keyinchalik, GROUP BY bandidan foydalanib, ushbu funksiyalar guruh yig'indisini hisoblash uchun qanday ishlatilishini ko'rib chiqamiz. GROUP BY - ma'lumotlarni guruhlashBundan oldin, biz ma'lum bir bo'lim bo'yicha umumiy summalarni taxminan quyidagicha hisoblab chiqdik:COUNT (DISTINCT Lavozim identifikatori) PositionCount, COUNT (*) Ishchilar soni, SO‘M (ish haqi) Xodimlardan maosh miqdori TANLASH QAYERDA Bo‘limID = 3 - faqat IT bo‘limi uchun ma’lumotlar Endi tasavvur qiling-a, bizdan har bir bo'lim kontekstida bir xil raqamlarni olish so'ralgan. Albatta, yeng shimarib, har bir bo‘lim uchun bir xil talabni bajara olamiz. Shunday qilib, bajarilgandan so'ng, biz 4 ta so'rov yozamiz: "Ma'muriyat" ma'lumotlarini, COUNT (alohida Lavozim identifikatori) PositionCount, COUNT (*) Ishchilar soni, SO'M (Ish haqi) Ish haqi miqdorini TANlang QAYERDA Bo'limID = 1 - ma'muriyat bo'yicha ma'lumotlar "Buxgalteriya" ma'lumotlarini, COUNT (DISTINCT PositionID) (COUNT) lavozimini tanlang ) Ishchilar soni, so'm (ish haqi) Xodimlardan maosh miqdori bo'limID = 2 - Buxgalteriya ma'lumotlari "IT" ma'lumotlarini, COUNT (alohida lavozim identifikatori) lavozim raqamini, COUNT (*) ish haqi miqdorini tanlang. IT bo'limi "Boshqa" ma'lumotni, COUNT (alohida Lavozim identifikatori) PositionCount, COUNT (*) Ishchilar soni, SO'M (ish haqi) Maosh miqdorini TANLANGAN QAYERDA departament ID NULL - va frilanserlar haqidagi ma'lumotlarni unutmang. Natijada biz 4 ta ma'lumotlar to'plamini olamiz:
E'tibor bering, biz doimiylar sifatida ko'rsatilgan maydonlardan foydalanishimiz mumkin - "Ma'muriyat", "Buxgalteriya", ... Umuman olganda, bizdan so'ralgan barcha raqamlarni chiqarib oldik, biz Excelda hamma narsani birlashtiramiz va direktorga beramiz. Direktorga hisobot yoqdi va u shunday deydi: "va o'rtacha ish haqi to'g'risidagi ma'lumotlar bilan yana bir ustun qo'shing." Va har doimgidek, buni juda zudlik bilan qilish kerak. Hm, nima qilish kerak ?! Bundan tashqari, bizning bo'limlarimiz 3 emas, balki 15 ta ekanligini tasavvur qilaylik. GROUP BY bandi bunday holatlar uchun aynan shunday: Bo‘lim identifikatori, COUNT (alohida lavozim identifikatori) Lavozim soni, COUNT (*) Ishchilar soni, SUM (ish haqi) Ish haqi miqdori, AVG (ish haqi) O‘rtacha ish haqi – bundan tashqari biz direktorning istaklarini bajaramiz.
Bizda bir xil ma'lumotlar bor, lekin hozir faqat bitta so'rovdan foydalanmoqdamiz! Hozircha bo'limlarimiz raqamlar ko'rinishida ko'rsatilishiga e'tibor bermang, keyin hamma narsani chiroyli ko'rsatishni o'rganamiz. GROUP BY bandida siz bir nechta maydonlarni belgilashingiz mumkin "GROUP BY" maydoni1, maydon2, ..., maydonN, bu holda guruhlash ushbu maydonlarning qiymatlarini tashkil etuvchi guruhlar bo'yicha amalga oshiriladi "maydon1, maydon2, .. ., maydonN". Masalan, ma'lumotlarni bo'limlar va lavozimlar bo'yicha guruhlaymiz: Bo'lim identifikatori, Lavozim identifikatori, COUNT (*) Ishchilar soni, so'm (ish haqi) Xodimlar guruxidan bo'lim identifikatori, lavozim identifikatori SOQANI (*) TANLASH, departamentID NO VA Lavozim identifikatori NULL BO‘LGAN Xodimlardan ish haqi miqdorini tanlang. (*) Ishchilar soni, so'm (ish haqi) bo'lim ID = 3 VA Lavozim ID = 4 bo'lgan xodimlardan olingan ish haqi miqdori Va keyin bu natijalarning barchasi birlashtirilib, bizga bitta to'plam sifatida beriladi:
Asosiy nuqtadan shuni ta'kidlash kerakki, guruhlashda (GROUP BY) SELECT blokidagi ustunlar ro'yxatida:
Va aytilganlarning hammasining namoyishi: "String doimiysi" ni tanlang Const1, - 1 qator ko'rinishidagi konstanta Const2, - doimiy raqam ko'rinishida - CONCAT ("Bo'lim No.", DepartamentID) guruhida ishtirok etuvchi maydonlar yordamida ifoda ConstAndGroupField, CONCAT ("Bo'lim" No.", DepartamentID , ", Position No.", PositionID) ConstAndGroupFields, DepartmentID, - guruhlashda ishtirok etuvchi maydonlar ro'yxatidan maydon - PositionID, - guruhlashda ishtirok etuvchi maydon, bu yerda COUNT ni takrorlash shart emas ( *) EmplCount, - har bir guruhdagi qatorlar soni - qolgan maydonlar faqat jamlangan funksiyalar bilan ishlatilishi mumkin: COUNT, SUM, MIN, MAX,… SUM (Ish haqi) Ish haqi miqdori, MIN (ID) MiniID. , PositionID - DepartamentID, PositionID maydonlari bo'yicha guruhlash Shuni ham ta'kidlash joizki, guruhlash faqat maydonlar bo'yicha emas, balki ifodalar bo'yicha ham amalga oshirilishi mumkin. Masalan, ma'lumotlarni xodimlar bo'yicha, tug'ilgan yili bo'yicha guruhlaymiz: SELECT CONCAT ("Tug'ilgan yili -", YEAR (Tug'ilgan kun)) Tug'ilgan yili, COUNT (*) Xodimlar soni YIL BO'YICHA (tug'ilgan kun) Keling, murakkabroq ifodali misolni ko'rib chiqaylik. Masalan, tug'ilgan yili bo'yicha xodimlarning gradatsiyasini olaylik: QAChON YIL (Tug'ilgan kun)> = 2000 KEYIN "2000 YILDAN" QAChON YIL (Tug'ilgan kun)> = 1990 KEYIN "1999-1990" QAChON YIL (Tug'ilgan kun)> = 1980 KEYIN "1989-1980 YIL" (Tug'ilgan kun) 1970 KEYIN "1979-1970" QACHON Tug'ilgan kun NULL EMAS KEYIN "1970-yildan oldin" BOSHQA "belgilanmagan" END RangeName, COUNT (*) Xodimlar soni GURUH BO'YICHA YIL (Tug'ilgan kun)> YIL BO'YICHA = "2000 2000" (Tug'ilgan kun)> = 1990 KEYIN "1999-1990" QACHON YIL (Tug'ilgan kun)> = 1980 KEYIN "1989-1980" QACHON YIL (Tug'ilgan kun)> = 1970 KEYIN "1979-1970" QAChON "1979-1970" Tug'ilgan kun 79 BO'LMAYDI ELSE "belgilanmagan" END
Bular. bu holda guruhlash har bir xodim uchun oldindan hisoblab chiqilgan CASE ifodasiga muvofiq amalga oshiriladi: ID NI TANlang, ISHLAB CHIQISH QAChON YIL (Tug'ilgan kun)> = 2000 KEYIN "2000 dan" QAChON YIL (Tug'ilgan kun)> = 1990 KEYIN "1999-1990" QACHON YIL (Tug'ilgan kun)> = 1980 KEYIN "1989-1980 YIL" > = 1970 KEYIN "1979-1970" QACHON TUG'G'ILGAN KUNI BO'LGAN EMAS KEYIN "1970-yildan oldin" BOSHQA "belgilanmagan" Xodimlardan
Va, albatta, siz iboralarni GROUP BY blokidagi maydonlar bilan birlashtira olasiz: SELECT DepartamentID, CONCAT ("Tug'ilgan yili -", YEAR (Tug'ilgan kun)) Tug'ilgan yili, COUNT (*) Xodimlar soni YIL BO'YICHA GURUH (Tug'ilgan kun), DepartamentID - tartib SELECT ORDERda ulardan foydalanish tartibiga to'g'ri kelmasligi mumkin. BY DepartmentID bloki, YearOfBirthday - nihoyat, natijaga saralashni qo'llashimiz mumkin Keling, asl vazifamizga qaytaylik. Biz allaqachon bilganimizdek, direktorga hisobot juda yoqdi va u kompaniyadagi o'zgarishlarni kuzatib borishimiz uchun bizdan buni har hafta qilishimizni so'radi. Excelda har safar bo'limning raqamli qiymatini uning nomi bilan to'xtatmaslik uchun biz allaqachon mavjud bo'lgan bilimlardan foydalanamiz va so'rovimizni yaxshilaymiz: ISHLAB CHIQARISH Bo‘limi ID QAChON 1 SO‘NG “Ma’muriyat” QAChON 2 SO‘NG 3 KEYIN “Buxgalteriya” BOSHQA “Boshqa” TUGARISh ma’lumot, COUNT (*) Ishchilar soni, SUM (Ish haqi) Ish haqi miqdori, AVG ) MaoshAvg - qo'shimcha ravishda biz direktorning istaklarini bajaramiz Xodimlar GURUHIDAN BO'LIM BO'YICHA BUYURTMA BO'YICHA Ma'lumot bo'yicha - ko'proq qulaylik uchun Ma'lumot ustuniga saralashni qo'shing Lekin hech narsa, vaqt o'tishi bilan biz hamma narsani chiroyli qilishni o'rganamiz, shunda bizning tanlovimiz ma'lumotlar bazasida yangi ma'lumotlar paydo bo'lishiga bog'liq emas, balki dinamik bo'ladi. Men qanday so'rovlar bilan chiqishga harakat qilayotganimizni ko'rsatish uchun biroz oldinga yuguraman: SELECT ISNULL (dep.Name, "Other") DepName, COUNT (DISTINCT emp.PozitionID) PositionCount, COUNT (*) EmplCount, SUM (emp.Slary) MaoshAmount, AVG (emp.Slary) SaaryAvg - plyus istaklarini bajaring direktor FROM Xodimlar emp CHAP QO'SHILMA Bo'limlar dep ON emp.DepartmentID = dep.ID GROUP BY emp.DepartmentID, dep.Name BUYURT BY DepName Umuman olganda, tashvishlanmang - hamma oddiy boshladi. Hozircha siz faqat GROUP BY bandining mohiyatini tushunishingiz kerak. Nihoyat, GROUP BY yordamida qanday qilib xulosa hisobotlarini tuzish mumkinligini ko'rib chiqamiz. Masalan, bo'limlar kontekstida pivot jadvalini ko'rsatamiz, shunda xodimlarning lavozim bo'yicha olgan umumiy ish haqi hisoblab chiqiladi: Bo'lim ID, SO'M (ILODA ISHLAB CHIQISH ISHLATISH = 1 KEYIN ish haqi tugaydi) [Buxgalterlar], SUM (Lavozim ID = 2 BO'LSA KEYIN ish haqi tugaydi) [Direktorlar], SUM (Lavozim ID = 3 KEYIN ish haqi tugaydi) [Dasturchilar], sum ( HOZIR QACHON LavozimID = 4 KEYIN ish haqi tugaydi) [Yuqori dasturchilar], SUM (ish haqi) [Boʻlim jami] Xodimlar GURUHIDAN Departament identifikatoriga koʻra Siz, albatta, IIF yordamida qayta yozishingiz mumkin: Departament identifikatori, SUM (IIF (Lavozim identifikatori = 1, ish haqi, NULL)) [Buxgalter], SUM (IIF (Lavozim ID = 2, ish haqi, NULL)) [Direktorlar], SUM (IIF (Lavozim ID = 3, ish haqi, NULL)) [Dasturchilar], SUM (IIF (Lavozim identifikatori = 4, ish haqi, NULL)) [Katta dasturchilar], SUM (ish haqi) [Bo'lim jami] Xodimlar GURUHIDAN Bo'lim identifikatori Ammo IIF holatida biz NULLni aniq ko'rsatishimiz kerak, agar shart bajarilmasa qaytariladi. Shunga o'xshash holatlarda men yana bir marta NULL yozishdan ko'ra CASE dan ELSE blokisiz foydalanishni afzal ko'raman. Lekin bu, albatta, ta'm masalasidir, bu haqda bahslashmaydi. Va esda tutingki, NULL qiymatlari yig'ish funktsiyalarida hisobga olinmaydi. Birlashtirish uchun kengaytirilgan so'rov orqali olingan ma'lumotlarni mustaqil tahlil qiling: Bo'lim identifikatorini tanlang, Lavozim ID = 1 bo'lsa, ish haqi tugaydi [Buxgalter], Lavozim ID = 2 bo'lsa, ish haqi tugaydi [Direktorlar], Lavozim ID = 3 bo'lsa, ish haqi tugaydi [Dasturchilar], Lavozim ID = 4 BO'LSA. ], Ish haqi [Bo'lim jami] Xodimlardan
Va shuni ham eslaylikki, agar NULL o'rniga biz nollarni ko'rmoqchi bo'lsak, u holda agregat funktsiyasi tomonidan qaytarilgan qiymatni qayta ishlashimiz mumkin. Masalan: Departament identifikatori, ISNULL (SUM (IIF (lavozim identifikatori = 1, ish haqi, NULL)), 0) [Buxgalter], ISNULL (SUM (IIF (Lavozim ID = 2, ish haqi, NULL)), 0) [Direktorlar], ISNULL (SUM) (IIF (PositionID = 3, Maosh, NULL)), 0) [Dasturchilar], ISNULL (SUM (IIF (LavozimID = 4, Maosh, NULL)), 0) [Katta dasturchilar], ISNULL (SUM (ish haqi), 0 ) [Bo'lim jami] Xodimlar GURUHIDAN Bo'lim identifikatori
GROUP BY, agregat funktsiyalariga qaramay, ma'lumotlar bazasidan yig'ma ma'lumotlarni olish uchun ishlatiladigan asosiy vositalardan biridir, chunki odatda ma'lumotlar ushbu shaklda ishlatiladi, chunki bizdan odatda batafsil ma'lumotlar (varaqlar) emas, balki umumlashtirilgan hisobotlarni taqdim etishimiz talab qilinadi. Va, albatta, hamma narsa asosiy dizaynni bilish atrofida aylanadi, chunki biror narsani umumlashtirishdan (jamlashdan) oldin, avval uni "SELECT ... WHERE ..." yordamida to'g'ri tanlashingiz kerak. Amaliyot bu erda muhim o'rin tutadi, shuning uchun siz SQL tilini o'rganishni emas, balki tushunishni maqsad qilib qo'ysangiz - o'ylashingiz mumkin bo'lgan eng xil variantlardan o'tib, amaliyot, amaliyot va amaliyot. Dastlabki bosqichda, agar siz olingan jamlangan ma'lumotlarning to'g'riligiga ishonchingiz komil bo'lmasa, yig'ish davom etayotgan barcha qiymatlarni o'z ichiga olgan batafsil namunani tuzing. Va ushbu batafsil ma'lumotlardan foydalanib, hisob-kitoblarning to'g'riligini qo'lda tekshiring. Bunday holda, Excel-dan foydalanish juda foydali bo'lishi mumkin. Aytaylik, siz shu darajaga yetdingizAytaylik, siz buxgalter S. S. Sidorovsiz, u SELECT so'rovlarini yozishni o'rganishga qaror qildi.Aytaylik, siz ushbu qo'llanmani shu paytgacha o'qib chiqdingiz va yuqoridagi barcha asosiy konstruktsiyalardan ishonch bilan foydalaning, ya'ni. Siz .. qila olasiz; siz ... mumkin:
Ha, lekin ular hali bir nechta jadvallardan so'rovlar tuza olmasligingizni hisobga olishmadi, faqat bittadan, ya'ni. siz shunga o'xshash narsani qanday qilishni bilmayapsiz: SELECT emp *, - Xodimlar jadvalining barcha maydonlarini qaytaring.Name BoʻlimName, - Boʻlimlar jadvalining pos.Name PositionName nomi maydonini ushbu maydonlarga qoʻshing - shuningdek, Lavozimlar jadvalidan “Ism” maydonini FROM Employees emp LEFT JOIN qoʻshing. Bo'limlar dep ON emp.DepartmentID = dep.ID CHAP JOIN Lavozimlar pos ON emp.PositionID = pos.ID Xo'sh, qanday qilib hozirgi bilimlaringizdan foydalanishingiz va yanada samarali natijalarga erishishingiz mumkin ?! Biz kollektiv aqlning kuchidan foydalanamiz - biz siz uchun ishlaydigan dasturchilarga boramiz, ya'ni. Andreev A.A.ga, Petrov P.P. yoki Nikolayev N.N., va ulardan kimdir siz uchun ko'rinish yozishni so'rang (KO'RING yoki shunchaki "Ko'rish", shuning uchun ular sizni tezroq tushunishlari uchun), bu "Xodimlar" jadvalidagi asosiy maydonlarga qo'shimcha ravishda, maydonlarni ham qaytaradi. "Bo'lim nomi" va "Lavozim nomi" sizga hozir Ivanov II yuklagan haftalik hisobot uchun etishmayotgan. Chunki siz hamma narsani to'g'ri tushuntirdingiz, keyin IT mutaxassislari ulardan nimani xohlashlarini darhol tushunishdi va ayniqsa siz uchun ViewEmployeesInfo nomli ko'rinishni yaratdilar. Biz keyingi buyruqni ko'rmasligingizni bildiramiz, chunki IT mutaxassislari buni amalga oshiradilar: CREATE VIEWEmployeesInfo AS SELECT emp. Xodimlar emp LEFT JOIN Bo'limlar dep ON emp.DepartmentID = dep.ID LEFT JOIN Positions pos ON emp.PositionID = pos.ID Bular. Bularning barchasi siz uchun qo'rqinchli va tushunarsiz bo'lsa-da, matn ekrandan tashqarida qoladi va IT mutaxassislari sizga faqat yuqoridagi barcha ma'lumotlarni (ya'ni siz so'ragan narsa) qaytaradigan "ViewEmployeesInfo" ko'rinishi nomini beradi. Endi siz oddiy jadvaldagi kabi ushbu ko'rinish bilan ishlashingiz mumkin: ViewEmployeesInfo-dan *-ni tanlang Bo‘lim nomi, COUNT (alohida lavozim identifikatori) Lavozim soni, COUNT (*) Ishchilar soni, so‘m (ish haqi) Ish haqi miqdori, AVG (ish haqi) O‘rtacha ish haqiO‘rtacha. Bular. siz uchun bu holatda, go'yo hech narsa o'zgarmagandek, bitta jadval bilan xuddi shu tarzda ishlashni davom ettirasiz (lekin ViewEmployeesInfo ko'rinishida aytish to'g'riroq bo'lar edi), bu sizga barcha kerakli ma'lumotlarni qaytaradi. IT-mutaxassislarining yordami tufayli DepartamentName va PositionName qazib olish tafsilotlari siz uchun qora qutida qoladi. Bular. ko'rinish sizga oddiy jadval kabi ko'rinadi, uni Xodimlar jadvalining kengaytirilgan versiyasi deb hisoblang. Misol uchun, keling, hamma narsa men aytganimdek ekanligiga ishonch hosil qilish uchun bayonot tuzamiz (butun namuna bir nuqtai nazardan kelib chiqadi): ID, ism, maoshni ViewEmployeesInfo dan TANLASH QAYERDA ish haqi NOL BO'LMAYDI VA oylik> 0 ismga ko'ra BUYURT Ba'zi hollarda ko'rinishlardan foydalanish asosiy SELECT so'rovlarini qanday yozishni biladigan foydalanuvchilarning chegaralarini sezilarli darajada kengaytirish imkonini beradi. Bunday holda, ko'rinish foydalanuvchiga kerak bo'lgan barcha ma'lumotlarga ega bo'lgan tekis jadvaldir (OLAPni tushunadiganlar uchun buni faktlar va o'lchamlar bilan OLAP kubining yaqinlashuvi bilan solishtirish mumkin). Vikipediyadan qirqish. Garchi SQL oxirgi foydalanuvchi uchun vosita sifatida yaratilgan bo'lsa-da, u oxir-oqibat juda murakkab bo'lib, dasturchining asbobiga aylandi. Ko'rib turganingizdek, aziz foydalanuvchilar, SQL tili dastlab siz uchun vosita sifatida yaratilgan. Shunday qilib, hamma narsa sizning qo'lingizda va xohishingizda, qo'llaringizni qo'yib yubormang. HAVING - guruhlangan ma'lumotlarga tanlash shartini qo'yishAslida, agar siz guruhlash nima ekanligini tushunsangiz, HAVING bilan hech qanday murakkab narsa yo'q. HAVING WHERE ga biroz o'xshaydi, faqat batafsil ma'lumotlarga WHERE sharti qo'llanilsa, HAVING sharti allaqachon guruhlangan ma'lumotlarga qo'llaniladi. Shu sababli, HAVING bloki sharoitida biz guruhlash tarkibiga kiritilgan maydonlar bilan ifodalangan yoki agregat funktsiyalarga kiritilgan ifodalardan foydalanishimiz mumkin.Keling, bir misolni ko'rib chiqaylik: TANLASH bo'limi ID, so'm (ish haqi) SO'M (ish haqi) BO'LGAN bo'lim GURUHIDAN SO'M (ish haqi)> 3000
Bular. Ushbu so'rov bizga guruhlangan ma'lumotlarni faqat barcha xodimlarning umumiy ish haqi 3000 dan oshadigan bo'limlar uchun qaytardi, ya'ni. "SUM (ish haqi)> 3000".
Bular. Bu erda, birinchi navbatda, guruhlash amalga oshiriladi va barcha bo'limlar uchun ma'lumotlar hisoblanadi: Bo'lim identifikatorini, so'mni (ish haqi) Xodimlar GURUHIDAN bo'lim identifikatori bo'yicha maosh miqdorini tanlang - 1. barcha bo'limlar uchun guruhlangan ma'lumotlarni oling Va allaqachon HAVING blokida ko'rsatilgan shart ushbu ma'lumotlarga nisbatan qo'llaniladi: TANLASH bo'limi ID, SUM (ish haqi) Xodimlar GURUHIDAN bo'lim ID - 1. barcha bo'limlar uchun guruhlangan ma'lumotlarni olish SUM (ish haqi)> 3000 - 2. guruhlangan ma'lumotlarni filtrlash sharti HAVING holatida siz AND, OR va NOT operatorlari yordamida ham murakkab shartlarni yaratishingiz mumkin: Bo'lim ID, SO'M (ish haqi) SO'MGA BO'LGAN bo'lim ID BO'YICHA GURUHIDAN (ish haqi) Ish haqi miqdori> 3000 VA SON (*)<2 -- и число людей меньше 2-х
Bu erda ko'rib turganingizdek, yig'ish funktsiyasi ("COUNT (*)" ga qarang) faqat HAVING blokida ko'rsatilishi mumkin. Shunga ko'ra, biz faqat HAVING shartiga mos keladigan bo'lim raqamini ko'rsatishimiz mumkin: SUM (Ish haqi)> 3000 VA SON (*) BO'LGAN bo'lim ID BO'LIMLARI BO'YICHA Xodimlar GURUHIDAN TANLASH<2 -- и число людей меньше 2-х GROUP BY tarkibiga kiritilgan maydonda HAVING shartidan foydalanishga misol: Bo'lim ID, SO'M (ish haqi) Xodimlar GURUHIDAN bo'lim ID NI TANLASH - 1. bo'lim ID ga ega bo'lgan guruhlash = 3 - 2. guruhlash natijasini filtrlash Bu faqat bir misol, chunki bu holda, WHERE sharti orqali tekshirish mantiqiyroq bo'ladi: TANLASH bo'limi ID, SO'M (ish haqi) Xodimlardan ish haqi miqdori QAYERDA Bo'limID = 3 - 1. batafsil ma'lumotlarni filtrlash Bo'lim identifikatori bo'yicha GURUHLASH - 2. faqat tanlangan yozuvlar bo'yicha guruhlash Bular. birinchi navbatda, xodimlarni 3-bo'lim bo'yicha filtrlang va shundan keyingina hisob-kitob qiling. Eslatma. Aslida, ikkita so'rov boshqacha ko'rinishga ega bo'lsa ham, DBMS optimallashtiruvchisi ularni bir xil tarzda bajarishi mumkin. O'ylaymanki, HAVING shartlari haqidagi hikoya shu erda tugaydi. Keling, xulosa qilaylikKeling, ikkinchi va uchinchi qismlarda olingan ma'lumotlarni umumlashtiramiz va biz o'rgangan har bir tuzilmaning o'ziga xos joylashuvini ko'rib chiqamiz va ularni amalga oshirish tartibini ko'rsatamiz:
Albatta, siz ikkinchi qismda o'rgangan DISTINCT va TOP bandlarini guruhlangan ma'lumotlarga ham qo'llashingiz mumkin. Bu holda ushbu takliflar yakuniy natijaga taalluqlidir: TOP 1 - 6. Oxirgi so'm (ish haqi) qo'llaniladi Ish haqi miqdori bo'lim ID BO'YICHA GURUHIDAN SO'M (ish haqi) BO'YICHA> 3000 BUYURTMA BO'LIMIDAN - 5. natijani saralash Ushbu natijalar qanday olinganligini o'zingiz tahlil qiling. XulosaUshbu qismda men qo'ygan asosiy maqsad siz uchun agregat funktsiyalar va guruhlarning mohiyatini ochib berishdir.Agar asosiy dizayn bizga kerakli batafsil ma'lumotlarni olishga imkon bergan bo'lsa, unda ushbu batafsil ma'lumotlarga agregat funktsiyalar va guruhlarni qo'llash bizga ular bo'yicha umumlashtirilgan ma'lumotlarni olish imkoniyatini berdi. Shunday qilib, siz ko'rib turganingizdek, bu erda hamma narsa muhim, tk. biri ikkinchisiga asoslanadi - asosiy tuzilmani bilmasdan, biz, masalan, jami hisoblashimiz kerak bo'lgan ma'lumotlarni to'g'ri tanlay olmaymiz. Bu erda men ataylab faqat asosiy narsalarni ko'rsatishga harakat qilaman, shunda boshlang'ichning e'tiborini eng muhim tuzilmalarga qaratish va ularni keraksiz ma'lumotlar bilan ortiqcha yuklamaslik kerak. Asosiy tuzilmalarni yaxshi tushunish (bu haqda keyingi qismlarda gapirishni davom ettiraman) sizga RDB dan ma'lumotlarni olishning deyarli har qanday muammosini hal qilish imkoniyatini beradi. SELECT bayonotining asosiy konstruktsiyalari deyarli barcha ma'lumotlar bazasida bir xil shaklda qo'llaniladi (farqlar asosan tafsilotlarda, masalan, funktsiyalarni bajarishda - satrlar, vaqt va boshqalar bilan ishlash uchun). Keyinchalik, bazani yaxshi bilish sizga SQL tilining turli kengaytmalarini osongina o'rganish imkoniyatini beradi, masalan:
Agar siz SQL-da birinchi qadamlaringizni qo'yayotgan bo'lsangiz, unda birinchi navbatda asosiy konstruktsiyalarni o'rganishga e'tibor qarating Bazaga ega bo'lgan holda, qolgan hamma narsani o'zingiz tushunishingiz osonroq bo'ladi va bundan tashqari. Avvalo, siz SQL tilining imkoniyatlarini chuqur tushunishingiz kerak, ya'ni. odatda ma'lumotlarda qanday operatsiyani bajarishga imkon beradi. Yangi boshlanuvchilarga ma'lumotni hajmli shaklda etkazish men faqat eng muhim (temir) tuzilmalarni ko'rsatishimning sabablaridan biridir. SQL tilini o'rganish va tushunishda omad tilaymiz. To'rtinchi qism -
Ushbu qismda nima muhokama qilinadiUshbu qismda biz quyidagilarni bilib olamiz:
CASE ifodasi - SQL shartli bayonotiBu operator muayyan shartning bajarilishiga, u yoki bu natijaga qarab shartlarni tekshirish va qaytarish imkonini beradi.CASE bayonoti 2 shaklga ega: Birinchi CASE shakliga misol keltiramiz: ID, Ism, ish haqi, HOLAT QACHON Ish haqi> = 3000 KEYIN "RFP> = 3000" QACHON ish haqi> = 2000 KEYIN "2000 NI TANLASH.<= ЗП < 3000"
ELSE "ЗП < 2000"
END SalaryTypeWithELSE,
CASE
WHEN Salary>= 3000 KEYIN "ish haqi> = 3000" QACHON Ish haqi> = 2000 KEYIN "2000"<= ЗП < 3000"
END SalaryTypeWithoutELSE
FROM Employees
Agar WHEN shartlaridan hech biri bajarilmasa, ELSE so'zidan keyin ko'rsatilgan qiymat qaytariladi (bu holda "ALSE RETURN ..." degan ma'noni anglatadi). Agar ELSE bloki belgilanmagan bo'lsa va WHEN shartlari bajarilmasa, NULL qaytariladi. Birinchi va ikkinchi shakllarda ELSE bloki CASE strukturasining eng oxirida joylashgan, ya'ni. barcha WHEN shartlaridan keyin. Ikkinchi CASE shakliga misol keltiramiz: Aytaylik, yangi yil uchun ular barcha xodimlarni mukofotlashga qaror qilishdi va quyidagi sxema bo'yicha bonuslar miqdorini hisoblashni so'rashdi:
Ushbu vazifa uchun biz CASE ifodasi bilan so'rovdan foydalanamiz: SELECT ID, Ism, Maosh, DepartamentID, - aniqlik uchun biz foizni qator sifatida ko'rsatamiz CASE DepartmentID - tekshirilgan qiymat QAChON 2 KEYIN "10%" - 10% Buxgalterlarga QAChON 3 KEYIN "15%" - maoshdan 15% IT xodimlariga berish uchun BOSHQA "5%" - qolganlarga 5% END NewYearBonusPercent, - bonus miqdorini ko'rish uchun CASE yordamida ifoda tuzamiz Maosh / 100 * CASE DepartamentiID QACHON 2 KEYIN 10 - beriladigan ish haqining 10% Buxgalterlar uchun 3 QACHON KEYIN 15 - 15% IT xodimlariga beriladi BOSHQA 5 - qolganlar har biriga 5% Yakuniy bonus Xodimlardan olingan miqdor Shunga ko'ra, Departament identifikatori WHEN qiymatiga mos kelmasa, ELSE blokining qiymati qaytariladi. Agar ELSE bloki bo'lmasa, Departament identifikatori WHEN qiymatiga mos kelmasa, NULL qaytariladi. Ikkinchi CASE shaklini birinchi shakl yordamida ifodalash oson: ID, Ism, ish haqi, Departament ID, HOLAT QACHON bo‘lim ID = 2 BO‘LGAN KEYIN “10%” - buxgalterlarga ish haqining 10% QAChON bo‘lim ID = 3 bo‘lsa, “15%” - IT xodimlariga ish haqining 15% BOSHQA “ 5% "- qolgan har bir kishi 5% Yangi YilBonusPercentini tugatadi, - bonus miqdorini ko'rish uchun CASE yordamida ifoda tuzing Maosh / 100 * CASE QAChON Departament ID = 2 KEYIN 10 - 10% maoshi Buxgalterlarga QAChON Departament ID = 3 KEYIN 15 - Ish haqining 15% IT xodimlarini berish uchun BOSHQA 5 - qolganlar uchun har biriga 5% SOʻYGAN bonus summasi Xodimlardan Shunday qilib, ikkinchi shakl har bir WHEN qiymati/iborasi bilan bir xil test qiymatini tenglik bilan taqqoslashimiz kerak bo'lgan holatlar uchun soddalashtirilgan belgidir. Eslatma. CASE ning birinchi va ikkinchi shakllari SQL tili standartiga kiritilgan, shuning uchun ular ko'p ma'lumotlar bazasida qo'llanilishi mumkin. MS SQL 2012 versiyasi bilan soddalashtirilgan IIF yozuv shakli paydo bo'ldi. U faqat 2 ta qiymat qaytarilganda CASE bayonotini soddalashtirish uchun ishlatilishi mumkin. IIF dizayni quyidagicha: IIF (shart, haqiqiy_qiymat, noto'g'ri_qiymat) Bular. Aslida, bu quyidagi CASE konstruktsiyasi uchun o'ram: CASE WHEN sharti THEN true_value ALSE false_value END Keling, misolni ko'rib chiqaylik: SELECT ID, Ism, ish haqi, IIF (Ish haqi> = 2500, "Ish haqi> = 2500", "Ish haqi< 2500") DemoIIF, CASE WHEN Salary>= 2500 KEYIN "RFP> = 2500" BOSHQA "RFP< 2500" END DemoCASE FROM Employees CASE, IIF konstruksiyalari bir-birining ichiga joylashtirilishi mumkin. Keling, mavhum misolni ko'rib chiqaylik: ID, Ism, ish haqi, HOLDNI TANLANGAN QACHON bo‘lim ID (1,2) SO‘Y “A” QAChON Bo‘limID = 3 BO‘LGAN SO‘NG ISHLAB CHIQISH POSITIONID – ichki REAL QACHON 3 SO‘NG “B-1” QAChON 4 KEYIN “B-2” BOSHQA OXARI “ C "END Demo1, IIF (Bo'lim identifikatori (1,2)," A ", IIF (Bo'limID = 3, CASE PositionID QAChON 3" B-1 "When 4 KEYIN" B-2 "END," C ")) Demo2 Xodimlardan CASE va IIF konstruksiyalari natijani qaytaruvchi ifodalar bo‘lganligi uchun biz ulardan nafaqat SELECT blokida, balki ifodalardan foydalanishga ruxsat beruvchi boshqa bloklarda ham, masalan, WHERE yoki ORDER BY bandlarida foydalanishimiz mumkin. Misol uchun, bizga ish haqini taqsimlash uchun ro'yxatni yaratish vazifasi topshirilsin:
Keling, ORDER BY blokiga CASE ifodasini qo'shish orqali ushbu muammoni hal qilishga harakat qilaylik: ID, Ism, Xodimlardan Maosh TANLASH HOLAT BO'YICHA TARTIB Ish haqi> = 2500 KEYIN 1 BOSHQA 0 OXIR, - 2500 dan past bo'lganlarga birinchi navbatda maosh bering Ism - ro'yxatni to'liq ism bo'yicha tartiblang Va WHERE bandida CASE dan foydalanishning mavhum misoli: ID, Ism, Xodimlardan Maosh TANLASH QAYERDA QACHON ish haqi> = 2500 KEYIN 1 BOSHQA 0 END = 1 - ifodasi 1 boʻlgan barcha yozuvlar Oxirgi 2 ta misolni IIF funksiyasi bilan oʻzingiz takrorlashga urinib koʻrishingiz mumkin. Va nihoyat, NULL qiymatlari haqida yana bir bor eslaylik: ID, Ism, ish haqi, Departament ID, HOL QACHON QACHON Bo‘limID = 2 BO‘LGAN KEYIN “10%” – ish haqining 10%i Buxgalterlarga QAChON QAChON: 3 bo‘lsa “15%” - IT xodimlariga ish haqining 15 foizini TANLASH IS NULL KEYIN "-" - biz frilanserlarga bonuslar bermaymiz (biz IS NULL dan foydalanamiz) BOSHQA "5%" - qolganlarda har bir END NewYearBonusPercent1 5% bor, - lekin siz NULLni tekshira olmaysiz, NULL haqida nima deyilganini eslang. CASE DepartmentID ning ikkinchi qismida - - tekshirilgan qiymat QAChON 2 KEYIN "10%" QAChON 3 KEYIN "15%" QAChON NULL KEYIN "-" - !!! bu holda, ikkinchi CASE shaklidan foydalanish mos emas BOSHQA "5%" END NewYearBonusPercent2 FROM Xodimlar ID, Ism, ish haqi, bo‘lim identifikatori, CASE ISNULL (Bo‘lim identifikatori, -1) ni tanlang - NULL holatini -1 ga almashtirishdan foydalaning. QAChON 2 KEYIN "10%" QAChON 3 KEYIN “15%” QAChON -1 KEYIN “-” - agar biz ID (-1) ga teng bo'lim yo'qligiga ishonch hosil qilsak va BOSHQA "5%" bo'lmaydi. Umuman olganda, bu holda tasavvurning parvozi cheklanmagan. Masalan, ISNULL funktsiyasini CASE va IIF yordamida qanday modellashtirish mumkinligini ko'rib chiqamiz: SELECT ID, Ism, Familiya, ISNULL (Familiya, “Aniqlanmagan”) DemoISNULL, Familiya NULL BOʻLSA SOʻNG “Aniqlanmagan” BOSHQA Familiya END DemoCASE, IIF (Familiya NULL, “Aniqlanmagan”, Familiya) Namoz IIF CASE konstruktsiyasi juda kuchli SQL xususiyati bo'lib, natija to'plamining qiymatlarini hisoblash uchun qo'shimcha mantiqni kiritish imkonini beradi. Ushbu qismda CASE-konstruktsiyasiga egalik qilish biz uchun hali ham foydali bo'ladi, shuning uchun bu qismda, birinchi navbatda, unga e'tibor qaratiladi. Agregat funktsiyalariBu erda biz faqat asosiy va eng ko'p ishlatiladigan agregat funktsiyalarni ko'rib chiqamiz:
Agregat funktsiyalari SELECT iborasi yordamida olingan qatorlar to'plamining umumiy qiymatini hisoblash imkonini beradi. Keling, har bir funktsiyani misol bilan ko'rib chiqaylik: COUNT (*) [Xodimlarning umumiy soni], COUNT (DISTINCT Departament identifikatori) [Noyob bo‘limlar soni], COUNT (DISTINCT PositionID) [Noyob lavozimlar soni], COUNT (Bonus foiz) [Bonus %li xodimlar soni] , MAKS. (BonusPercent) [Maksimal bonus foizi], MIN (BonusPercent) [Minimal bonus foizi], SUM (Ish haqi / 100 * BonusPercent) [Barcha bonuslar yig‘indisi], AVG (Ish haqi / 100 * BonusPercent) [O‘rtacha bonus hajmi], AVG ( Ish haqi) [O'rtacha ish haqi] Xodimlardan Keling, har bir qaytarish qiymati qanday paydo bo'lganini ko'rib chiqaylik va birinchi navbatda, SELECT iborasining asosiy sintaksisining konstruktsiyalarini eslaylik. Birinchidan, chunki biz so'rovda QAYER shartlarini belgilamadik, keyin so'rov orqali olingan batafsil ma'lumotlar uchun jami hisoblab chiqiladi: Xodimlardan * ni tanlang Bular. Xodimlar jadvalining barcha qatorlari uchun. Aniqlik uchun biz faqat agregat funktsiyalarda ishlatiladigan maydonlar va iboralarni tanlaymiz: Departament identifikatori, Lavozim identifikatori, BonusFoiz, Ish haqi / 100 * BonusFoiz, Xodimlardan ish haqi
Bu yig'ilgan so'rovning umumiy summasi hisoblab chiqiladigan dastlabki ma'lumotlar (batafsil chiziqlar). Endi har bir jamlangan qiymatni ko'rib chiqamiz:
Keling, ba'zi natijalarni umumlashtiramiz:
Shunga ko'ra, WHERE bandida agregat funktsiyalari bilan qo'shimcha shartni belgilashda faqat shartni qondiradigan qatorlar uchun yig'indisi hisoblanadi. Bular. agregat qiymatlarni hisoblash SELECT konstruktsiyasi yordamida olingan umumiy to'plam uchun amalga oshiriladi. Misol uchun, xuddi shunday qilaylik, lekin faqat IT bo'limi kontekstida: COUNT (*) [Xodimlarning umumiy soni], COUNT (DISTINCT Departament identifikatori) [Noyob bo‘limlar soni], COUNT (DISTINCT PositionID) [Noyob lavozimlar soni], COUNT (Bonus foiz) [Bonus %li xodimlar soni] , MAX. (BonusPercent) [Maksimal bonus foizi], MIN (BonusPercent) [Minimal bonus foizi], SUM (Ish haqi / 100 * BonusPercent) [Barcha bonuslar yig‘indisi], AVG (Ish haqi / 100 * BonusPercent) [O‘rtacha bonus hajmi], AVG ( Ish haqi) [O'rtacha ish haqi] QAYERDA bo'lgan xodimlardan ID = 3 - Faqat IT bo'limini ko'rib chiqing Departament identifikatori, Lavozim identifikatori, BonusFoiz, Ish haqi / 100 * BonusFoiz, Xodimlardan olingan maosh QAYERDA bo'limID = 3 - faqat IT bo'limini hisobga oling
Davom etish. Agar agregat funktsiyasi NULL qiymatini qaytarsa (masalan, barcha xodimlarning ish haqi qiymati ko'rsatilgan bo'lmasa) yoki tanlovga bitta yozuv kiritilmagan bo'lsa va hisobotda bunday holat uchun biz 0 ni ko'rsatishimiz kerak, keyin ISNULL funktsiyasi agregat ifodani o'rashi mumkin: SUM (Ish haqi), AVG (ish haqi), - jami ma'lumotlarni ISNULL ISNULL (SUM (ish haqi), 0), ISNULL (AVG (ish haqi), 0) yordamida qayta ishlang. so'rovning yozuvlarni qaytarishiga yo'l qo'ymaslik uchun bu erda ko'rsatilgan
Men har bir agregat funktsiyasining maqsadini va uni qanday hisoblashini tushunish juda muhim deb hisoblayman, chunki SQL-da u umumiy miqdorlarni hisoblash uchun asosiy vositadir. Bunday holda, biz har bir agregat funktsiyaning mustaqil ravishda qanday harakat qilishini ko'rib chiqdik, ya'ni. u SELECT buyrug'i bilan olingan barcha yozuvlar to'plamining qiymatlariga qo'llaniladi. Keyinchalik, GROUP BY bandidan foydalanib, ushbu funksiyalar guruh yig'indisini hisoblash uchun qanday ishlatilishini ko'rib chiqamiz. GROUP BY - ma'lumotlarni guruhlashBundan oldin, biz ma'lum bir bo'lim bo'yicha umumiy summalarni taxminan quyidagicha hisoblab chiqdik:COUNT (DISTINCT Lavozim identifikatori) PositionCount, COUNT (*) Ishchilar soni, SO‘M (ish haqi) Xodimlardan maosh miqdori TANLASH QAYERDA Bo‘limID = 3 - faqat IT bo‘limi uchun ma’lumotlar Endi tasavvur qiling-a, bizdan har bir bo'lim kontekstida bir xil raqamlarni olish so'ralgan. Albatta, yeng shimarib, har bir bo‘lim uchun bir xil talabni bajara olamiz. Shunday qilib, bajarilgandan so'ng, biz 4 ta so'rov yozamiz: "Ma'muriyat" ma'lumotlarini, COUNT (alohida Lavozim identifikatori) PositionCount, COUNT (*) Ishchilar soni, SO'M (Ish haqi) Ish haqi miqdorini TANlang QAYERDA Bo'limID = 1 - ma'muriyat bo'yicha ma'lumotlar "Buxgalteriya" ma'lumotlarini, COUNT (DISTINCT PositionID) (COUNT) lavozimini tanlang ) Ishchilar soni, so'm (ish haqi) Xodimlardan maosh miqdori bo'limID = 2 - Buxgalteriya ma'lumotlari "IT" ma'lumotlarini, COUNT (alohida lavozim identifikatori) lavozim raqamini, COUNT (*) ish haqi miqdorini tanlang. IT bo'limi "Boshqa" ma'lumotni, COUNT (alohida Lavozim identifikatori) PositionCount, COUNT (*) Ishchilar soni, SO'M (ish haqi) Maosh miqdorini TANLANGAN QAYERDA departament ID NULL - va frilanserlar haqidagi ma'lumotlarni unutmang. Natijada biz 4 ta ma'lumotlar to'plamini olamiz:
E'tibor bering, biz doimiylar sifatida ko'rsatilgan maydonlardan foydalanishimiz mumkin - "Ma'muriyat", "Buxgalteriya", ... Umuman olganda, bizdan so'ralgan barcha raqamlarni chiqarib oldik, biz Excelda hamma narsani birlashtiramiz va direktorga beramiz. Direktorga hisobot yoqdi va u shunday deydi: "va o'rtacha ish haqi to'g'risidagi ma'lumotlar bilan yana bir ustun qo'shing." Va har doimgidek, buni juda zudlik bilan qilish kerak. Hm, nima qilish kerak ?! Bundan tashqari, bizning bo'limlarimiz 3 emas, balki 15 ta ekanligini tasavvur qilaylik. GROUP BY bandi bunday holatlar uchun aynan shunday: Bo‘lim identifikatori, COUNT (alohida lavozim identifikatori) Lavozim soni, COUNT (*) Ishchilar soni, SUM (ish haqi) Ish haqi miqdori, AVG (ish haqi) O‘rtacha ish haqi – bundan tashqari biz direktorning istaklarini bajaramiz.
Bizda bir xil ma'lumotlar bor, lekin hozir faqat bitta so'rovdan foydalanmoqdamiz! Hozircha bo'limlarimiz raqamlar ko'rinishida ko'rsatilishiga e'tibor bermang, keyin hamma narsani chiroyli ko'rsatishni o'rganamiz. GROUP BY bandida siz bir nechta maydonlarni belgilashingiz mumkin "GROUP BY" maydoni1, maydon2, ..., maydonN, bu holda guruhlash ushbu maydonlarning qiymatlarini tashkil etuvchi guruhlar bo'yicha amalga oshiriladi "maydon1, maydon2, .. ., maydonN". Masalan, ma'lumotlarni bo'limlar va lavozimlar bo'yicha guruhlaymiz: Bo'lim identifikatori, Lavozim identifikatori, COUNT (*) Ishchilar soni, so'm (ish haqi) Xodimlar guruxidan bo'lim identifikatori, lavozim identifikatori SOQANI (*) TANLASH, departamentID NO VA Lavozim identifikatori NULL BO‘LGAN Xodimlardan ish haqi miqdorini tanlang. (*) Ishchilar soni, so'm (ish haqi) bo'lim ID = 3 VA Lavozim ID = 4 bo'lgan xodimlardan olingan ish haqi miqdori Va keyin bu natijalarning barchasi birlashtirilib, bizga bitta to'plam sifatida beriladi:
Asosiy nuqtadan shuni ta'kidlash kerakki, guruhlashda (GROUP BY) SELECT blokidagi ustunlar ro'yxatida:
Va aytilganlarning hammasining namoyishi: "String doimiysi" ni tanlang Const1, - 1 qator ko'rinishidagi konstanta Const2, - doimiy raqam ko'rinishida - CONCAT ("Bo'lim No.", DepartamentID) guruhida ishtirok etuvchi maydonlar yordamida ifoda ConstAndGroupField, CONCAT ("Bo'lim" No.", DepartamentID , ", Position No.", PositionID) ConstAndGroupFields, DepartmentID, - guruhlashda ishtirok etuvchi maydonlar ro'yxatidan maydon - PositionID, - guruhlashda ishtirok etuvchi maydon, bu yerda COUNT ni takrorlash shart emas ( *) EmplCount, - har bir guruhdagi qatorlar soni - qolgan maydonlar faqat jamlangan funksiyalar bilan ishlatilishi mumkin: COUNT, SUM, MIN, MAX,… SUM (Ish haqi) Ish haqi miqdori, MIN (ID) MiniID. , PositionID - DepartamentID, PositionID maydonlari bo'yicha guruhlash Shuni ham ta'kidlash joizki, guruhlash faqat maydonlar bo'yicha emas, balki ifodalar bo'yicha ham amalga oshirilishi mumkin. Masalan, ma'lumotlarni xodimlar bo'yicha, tug'ilgan yili bo'yicha guruhlaymiz: SELECT CONCAT ("Tug'ilgan yili -", YEAR (Tug'ilgan kun)) Tug'ilgan yili, COUNT (*) Xodimlar soni YIL BO'YICHA (tug'ilgan kun) Keling, murakkabroq ifodali misolni ko'rib chiqaylik. Masalan, tug'ilgan yili bo'yicha xodimlarning gradatsiyasini olaylik: QAChON YIL (Tug'ilgan kun)> = 2000 KEYIN "2000 YILDAN" QAChON YIL (Tug'ilgan kun)> = 1990 KEYIN "1999-1990" QAChON YIL (Tug'ilgan kun)> = 1980 KEYIN "1989-1980 YIL" (Tug'ilgan kun) 1970 KEYIN "1979-1970" QACHON Tug'ilgan kun NULL EMAS KEYIN "1970-yildan oldin" BOSHQA "belgilanmagan" END RangeName, COUNT (*) Xodimlar soni GURUH BO'YICHA YIL (Tug'ilgan kun)> YIL BO'YICHA = "2000 2000" (Tug'ilgan kun)> = 1990 KEYIN "1999-1990" QACHON YIL (Tug'ilgan kun)> = 1980 KEYIN "1989-1980" QACHON YIL (Tug'ilgan kun)> = 1970 KEYIN "1979-1970" QAChON "1979-1970" Tug'ilgan kun 79 BO'LMAYDI ELSE "belgilanmagan" END
Bular. bu holda guruhlash har bir xodim uchun oldindan hisoblab chiqilgan CASE ifodasiga muvofiq amalga oshiriladi: ID NI TANlang, ISHLAB CHIQISH QAChON YIL (Tug'ilgan kun)> = 2000 KEYIN "2000 dan" QAChON YIL (Tug'ilgan kun)> = 1990 KEYIN "1999-1990" QACHON YIL (Tug'ilgan kun)> = 1980 KEYIN "1989-1980 YIL" > = 1970 KEYIN "1979-1970" QACHON TUG'G'ILGAN KUNI BO'LGAN EMAS KEYIN "1970-yildan oldin" BOSHQA "belgilanmagan" Xodimlardan
Va, albatta, siz iboralarni GROUP BY blokidagi maydonlar bilan birlashtira olasiz: SELECT DepartamentID, CONCAT ("Tug'ilgan yili -", YEAR (Tug'ilgan kun)) Tug'ilgan yili, COUNT (*) Xodimlar soni YIL BO'YICHA GURUH (Tug'ilgan kun), DepartamentID - tartib SELECT ORDERda ulardan foydalanish tartibiga to'g'ri kelmasligi mumkin. BY DepartmentID bloki, YearOfBirthday - nihoyat, natijaga saralashni qo'llashimiz mumkin Keling, asl vazifamizga qaytaylik. Biz allaqachon bilganimizdek, direktorga hisobot juda yoqdi va u kompaniyadagi o'zgarishlarni kuzatib borishimiz uchun bizdan buni har hafta qilishimizni so'radi. Excelda har safar bo'limning raqamli qiymatini uning nomi bilan to'xtatmaslik uchun biz allaqachon mavjud bo'lgan bilimlardan foydalanamiz va so'rovimizni yaxshilaymiz: ISHLAB CHIQARISH Bo‘limi ID QAChON 1 SO‘NG “Ma’muriyat” QAChON 2 SO‘NG 3 KEYIN “Buxgalteriya” BOSHQA “Boshqa” TUGARISh ma’lumot, COUNT (*) Ishchilar soni, SUM (Ish haqi) Ish haqi miqdori, AVG ) MaoshAvg - qo'shimcha ravishda biz direktorning istaklarini bajaramiz Xodimlar GURUHIDAN BO'LIM BO'YICHA BUYURTMA BO'YICHA Ma'lumot bo'yicha - ko'proq qulaylik uchun Ma'lumot ustuniga saralashni qo'shing Lekin hech narsa, vaqt o'tishi bilan biz hamma narsani chiroyli qilishni o'rganamiz, shunda bizning tanlovimiz ma'lumotlar bazasida yangi ma'lumotlar paydo bo'lishiga bog'liq emas, balki dinamik bo'ladi. Men qanday so'rovlar bilan chiqishga harakat qilayotganimizni ko'rsatish uchun biroz oldinga yuguraman: SELECT ISNULL (dep.Name, "Other") DepName, COUNT (DISTINCT emp.PozitionID) PositionCount, COUNT (*) EmplCount, SUM (emp.Slary) MaoshAmount, AVG (emp.Slary) SaaryAvg - plyus istaklarini bajaring direktor FROM Xodimlar emp CHAP QO'SHILMA Bo'limlar dep ON emp.DepartmentID = dep.ID GROUP BY emp.DepartmentID, dep.Name BUYURT BY DepName Umuman olganda, tashvishlanmang - hamma oddiy boshladi. Hozircha siz faqat GROUP BY bandining mohiyatini tushunishingiz kerak. Nihoyat, GROUP BY yordamida qanday qilib xulosa hisobotlarini tuzish mumkinligini ko'rib chiqamiz. Masalan, bo'limlar kontekstida pivot jadvalini ko'rsatamiz, shunda xodimlarning lavozim bo'yicha olgan umumiy ish haqi hisoblab chiqiladi: Bo'lim ID, SO'M (ILODA ISHLAB CHIQISH ISHLATISH = 1 KEYIN ish haqi tugaydi) [Buxgalterlar], SUM (Lavozim ID = 2 BO'LSA KEYIN ish haqi tugaydi) [Direktorlar], SUM (Lavozim ID = 3 KEYIN ish haqi tugaydi) [Dasturchilar], sum ( HOZIR QACHON LavozimID = 4 KEYIN ish haqi tugaydi) [Yuqori dasturchilar], SUM (ish haqi) [Boʻlim jami] Xodimlar GURUHIDAN Departament identifikatoriga koʻra Siz, albatta, IIF yordamida qayta yozishingiz mumkin: Departament identifikatori, SUM (IIF (Lavozim identifikatori = 1, ish haqi, NULL)) [Buxgalter], SUM (IIF (Lavozim ID = 2, ish haqi, NULL)) [Direktorlar], SUM (IIF (Lavozim ID = 3, ish haqi, NULL)) [Dasturchilar], SUM (IIF (Lavozim identifikatori = 4, ish haqi, NULL)) [Katta dasturchilar], SUM (ish haqi) [Bo'lim jami] Xodimlar GURUHIDAN Bo'lim identifikatori Ammo IIF holatida biz NULLni aniq ko'rsatishimiz kerak, agar shart bajarilmasa qaytariladi. Shunga o'xshash holatlarda men yana bir marta NULL yozishdan ko'ra CASE dan ELSE blokisiz foydalanishni afzal ko'raman. Lekin bu, albatta, ta'm masalasidir, bu haqda bahslashmaydi. Va esda tutingki, NULL qiymatlari yig'ish funktsiyalarida hisobga olinmaydi. Birlashtirish uchun kengaytirilgan so'rov orqali olingan ma'lumotlarni mustaqil tahlil qiling: Bo'lim identifikatorini tanlang, Lavozim ID = 1 bo'lsa, ish haqi tugaydi [Buxgalter], Lavozim ID = 2 bo'lsa, ish haqi tugaydi [Direktorlar], Lavozim ID = 3 bo'lsa, ish haqi tugaydi [Dasturchilar], Lavozim ID = 4 BO'LSA. ], Ish haqi [Bo'lim jami] Xodimlardan
Va shuni ham eslaylikki, agar NULL o'rniga biz nollarni ko'rmoqchi bo'lsak, u holda agregat funktsiyasi tomonidan qaytarilgan qiymatni qayta ishlashimiz mumkin. Masalan: Departament identifikatori, ISNULL (SUM (IIF (lavozim identifikatori = 1, ish haqi, NULL)), 0) [Buxgalter], ISNULL (SUM (IIF (Lavozim ID = 2, ish haqi, NULL)), 0) [Direktorlar], ISNULL (SUM) (IIF (PositionID = 3, Maosh, NULL)), 0) [Dasturchilar], ISNULL (SUM (IIF (LavozimID = 4, Maosh, NULL)), 0) [Katta dasturchilar], ISNULL (SUM (ish haqi), 0 ) [Bo'lim jami] Xodimlar GURUHIDAN Bo'lim identifikatori
GROUP BY, agregat funktsiyalariga qaramay, ma'lumotlar bazasidan yig'ma ma'lumotlarni olish uchun ishlatiladigan asosiy vositalardan biridir, chunki odatda ma'lumotlar ushbu shaklda ishlatiladi, chunki bizdan odatda batafsil ma'lumotlar (varaqlar) emas, balki umumlashtirilgan hisobotlarni taqdim etishimiz talab qilinadi. Va, albatta, hamma narsa asosiy dizaynni bilish atrofida aylanadi, chunki biror narsani umumlashtirishdan (jamlashdan) oldin, avval uni "SELECT ... WHERE ..." yordamida to'g'ri tanlashingiz kerak. Amaliyot bu erda muhim o'rin tutadi, shuning uchun siz SQL tilini o'rganishni emas, balki tushunishni maqsad qilib qo'ysangiz - o'ylashingiz mumkin bo'lgan eng xil variantlardan o'tib, amaliyot, amaliyot va amaliyot. Dastlabki bosqichda, agar siz olingan jamlangan ma'lumotlarning to'g'riligiga ishonchingiz komil bo'lmasa, yig'ish davom etayotgan barcha qiymatlarni o'z ichiga olgan batafsil namunani tuzing. Va ushbu batafsil ma'lumotlardan foydalanib, hisob-kitoblarning to'g'riligini qo'lda tekshiring. Bunday holda, Excel-dan foydalanish juda foydali bo'lishi mumkin. Aytaylik, siz shu darajaga yetdingizAytaylik, siz buxgalter S. S. Sidorovsiz, u SELECT so'rovlarini yozishni o'rganishga qaror qildi.Aytaylik, siz ushbu qo'llanmani shu paytgacha o'qib chiqdingiz va yuqoridagi barcha asosiy konstruktsiyalardan ishonch bilan foydalaning, ya'ni. Siz .. qila olasiz; siz ... mumkin:
Ha, lekin ular hali bir nechta jadvallardan so'rovlar tuza olmasligingizni hisobga olishmadi, faqat bittadan, ya'ni. siz shunga o'xshash narsani qanday qilishni bilmayapsiz: SELECT emp *, - Xodimlar jadvalining barcha maydonlarini qaytaring.Name BoʻlimName, - Boʻlimlar jadvalining pos.Name PositionName nomi maydonini ushbu maydonlarga qoʻshing - shuningdek, Lavozimlar jadvalidan “Ism” maydonini FROM Employees emp LEFT JOIN qoʻshing. Bo'limlar dep ON emp.DepartmentID = dep.ID CHAP JOIN Lavozimlar pos ON emp.PositionID = pos.ID Xo'sh, qanday qilib hozirgi bilimlaringizdan foydalanishingiz va yanada samarali natijalarga erishishingiz mumkin ?! Biz kollektiv aqlning kuchidan foydalanamiz - biz siz uchun ishlaydigan dasturchilarga boramiz, ya'ni. Andreev A.A.ga, Petrov P.P. yoki Nikolayev N.N., va ulardan kimdir siz uchun ko'rinish yozishni so'rang (KO'RING yoki shunchaki "Ko'rish", shuning uchun ular sizni tezroq tushunishlari uchun), bu "Xodimlar" jadvalidagi asosiy maydonlarga qo'shimcha ravishda, maydonlarni ham qaytaradi. "Bo'lim nomi" va "Lavozim nomi" sizga hozir Ivanov II yuklagan haftalik hisobot uchun etishmayotgan. Chunki siz hamma narsani to'g'ri tushuntirdingiz, keyin IT mutaxassislari ulardan nimani xohlashlarini darhol tushunishdi va ayniqsa siz uchun ViewEmployeesInfo nomli ko'rinishni yaratdilar. Biz keyingi buyruqni ko'rmasligingizni bildiramiz, chunki IT mutaxassislari buni amalga oshiradilar: CREATE VIEWEmployeesInfo AS SELECT emp. Xodimlar emp LEFT JOIN Bo'limlar dep ON emp.DepartmentID = dep.ID LEFT JOIN Positions pos ON emp.PositionID = pos.ID Bular. Bularning barchasi siz uchun qo'rqinchli va tushunarsiz bo'lsa-da, matn ekrandan tashqarida qoladi va IT mutaxassislari sizga faqat yuqoridagi barcha ma'lumotlarni (ya'ni siz so'ragan narsa) qaytaradigan "ViewEmployeesInfo" ko'rinishi nomini beradi. Endi siz oddiy jadvaldagi kabi ushbu ko'rinish bilan ishlashingiz mumkin: ViewEmployeesInfo-dan *-ni tanlang Bo‘lim nomi, COUNT (alohida lavozim identifikatori) Lavozim soni, COUNT (*) Ishchilar soni, so‘m (ish haqi) Ish haqi miqdori, AVG (ish haqi) O‘rtacha ish haqiO‘rtacha. Bular. siz uchun bu holatda, go'yo hech narsa o'zgarmagandek, bitta jadval bilan xuddi shu tarzda ishlashni davom ettirasiz (lekin ViewEmployeesInfo ko'rinishida aytish to'g'riroq bo'lar edi), bu sizga barcha kerakli ma'lumotlarni qaytaradi. IT-mutaxassislarining yordami tufayli DepartamentName va PositionName qazib olish tafsilotlari siz uchun qora qutida qoladi. Bular. ko'rinish sizga oddiy jadval kabi ko'rinadi, uni Xodimlar jadvalining kengaytirilgan versiyasi deb hisoblang. Misol uchun, keling, hamma narsa men aytganimdek ekanligiga ishonch hosil qilish uchun bayonot tuzamiz (butun namuna bir nuqtai nazardan kelib chiqadi): ID, ism, maoshni ViewEmployeesInfo dan TANLASH QAYERDA ish haqi NOL BO'LMAYDI VA oylik> 0 ismga ko'ra BUYURT Ba'zi hollarda ko'rinishlardan foydalanish asosiy SELECT so'rovlarini qanday yozishni biladigan foydalanuvchilarning chegaralarini sezilarli darajada kengaytirish imkonini beradi. Bunday holda, ko'rinish foydalanuvchiga kerak bo'lgan barcha ma'lumotlarga ega bo'lgan tekis jadvaldir (OLAPni tushunadiganlar uchun buni faktlar va o'lchamlar bilan OLAP kubining yaqinlashuvi bilan solishtirish mumkin). Vikipediyadan qirqish. Garchi SQL oxirgi foydalanuvchi uchun vosita sifatida yaratilgan bo'lsa-da, u oxir-oqibat juda murakkab bo'lib, dasturchining asbobiga aylandi. Ko'rib turganingizdek, aziz foydalanuvchilar, SQL tili dastlab siz uchun vosita sifatida yaratilgan. Shunday qilib, hamma narsa sizning qo'lingizda va xohishingizda, qo'llaringizni qo'yib yubormang. HAVING - guruhlangan ma'lumotlarga tanlash shartini qo'yishAslida, agar siz guruhlash nima ekanligini tushunsangiz, HAVING bilan hech qanday murakkab narsa yo'q. HAVING WHERE ga biroz o'xshaydi, faqat batafsil ma'lumotlarga WHERE sharti qo'llanilsa, HAVING sharti allaqachon guruhlangan ma'lumotlarga qo'llaniladi. Shu sababli, HAVING bloki sharoitida biz guruhlash tarkibiga kiritilgan maydonlar bilan ifodalangan yoki agregat funktsiyalarga kiritilgan ifodalardan foydalanishimiz mumkin.Keling, bir misolni ko'rib chiqaylik: TANLASH bo'limi ID, so'm (ish haqi) SO'M (ish haqi) BO'LGAN bo'lim GURUHIDAN SO'M (ish haqi)> 3000
Bular. Ushbu so'rov bizga guruhlangan ma'lumotlarni faqat barcha xodimlarning umumiy ish haqi 3000 dan oshadigan bo'limlar uchun qaytardi, ya'ni. "SUM (ish haqi)> 3000".
Bular. Bu erda, birinchi navbatda, guruhlash amalga oshiriladi va barcha bo'limlar uchun ma'lumotlar hisoblanadi: Bo'lim identifikatorini, so'mni (ish haqi) Xodimlar GURUHIDAN bo'lim identifikatori bo'yicha maosh miqdorini tanlang - 1. barcha bo'limlar uchun guruhlangan ma'lumotlarni oling Va allaqachon HAVING blokida ko'rsatilgan shart ushbu ma'lumotlarga nisbatan qo'llaniladi: TANLASH bo'limi ID, SUM (ish haqi) Xodimlar GURUHIDAN bo'lim ID - 1. barcha bo'limlar uchun guruhlangan ma'lumotlarni olish SUM (ish haqi)> 3000 - 2. guruhlangan ma'lumotlarni filtrlash sharti HAVING holatida siz AND, OR va NOT operatorlari yordamida ham murakkab shartlarni yaratishingiz mumkin: Bo'lim ID, SO'M (ish haqi) SO'MGA BO'LGAN bo'lim ID BO'YICHA GURUHIDAN (ish haqi) Ish haqi miqdori> 3000 VA SON (*)<2 -- и число людей меньше 2-х
Bu erda ko'rib turganingizdek, yig'ish funktsiyasi ("COUNT (*)" ga qarang) faqat HAVING blokida ko'rsatilishi mumkin. Shunga ko'ra, biz faqat HAVING shartiga mos keladigan bo'lim raqamini ko'rsatishimiz mumkin: SUM (Ish haqi)> 3000 VA SON (*) BO'LGAN bo'lim ID BO'LIMLARI BO'YICHA Xodimlar GURUHIDAN TANLASH<2 -- и число людей меньше 2-х GROUP BY tarkibiga kiritilgan maydonda HAVING shartidan foydalanishga misol: Bo'lim ID, SO'M (ish haqi) Xodimlar GURUHIDAN bo'lim ID NI TANLASH - 1. bo'lim ID ga ega bo'lgan guruhlash = 3 - 2. guruhlash natijasini filtrlash Bu faqat bir misol, chunki bu holda, WHERE sharti orqali tekshirish mantiqiyroq bo'ladi: TANLASH bo'limi ID, SO'M (ish haqi) Xodimlardan ish haqi miqdori QAYERDA Bo'limID = 3 - 1. batafsil ma'lumotlarni filtrlash Bo'lim identifikatori bo'yicha GURUHLASH - 2. faqat tanlangan yozuvlar bo'yicha guruhlash Bular. birinchi navbatda, xodimlarni 3-bo'lim bo'yicha filtrlang va shundan keyingina hisob-kitob qiling. Eslatma. Aslida, ikkita so'rov boshqacha ko'rinishga ega bo'lsa ham, DBMS optimallashtiruvchisi ularni bir xil tarzda bajarishi mumkin. O'ylaymanki, HAVING shartlari haqidagi hikoya shu erda tugaydi. Keling, xulosa qilaylikKeling, ikkinchi va uchinchi qismlarda olingan ma'lumotlarni umumlashtiramiz va biz o'rgangan har bir tuzilmaning o'ziga xos joylashuvini ko'rib chiqamiz va ularni amalga oshirish tartibini ko'rsatamiz:
Albatta, siz ikkinchi qismda o'rgangan DISTINCT va TOP bandlarini guruhlangan ma'lumotlarga ham qo'llashingiz mumkin. Bu holda ushbu takliflar yakuniy natijaga taalluqlidir: TOP 1 - 6. Oxirgi so'm (ish haqi) qo'llaniladi Ish haqi miqdori bo'lim ID BO'YICHA GURUHIDAN SO'M (ish haqi) BO'YICHA> 3000 BUYURTMA BO'LIMIDAN - 5. natijani saralash Ushbu natijalar qanday olinganligini o'zingiz tahlil qiling. XulosaUshbu qismda men qo'ygan asosiy maqsad siz uchun agregat funktsiyalar va guruhlarning mohiyatini ochib berishdir.Agar asosiy dizayn bizga kerakli batafsil ma'lumotlarni olishga imkon bergan bo'lsa, unda ushbu batafsil ma'lumotlarga agregat funktsiyalar va guruhlarni qo'llash bizga ular bo'yicha umumlashtirilgan ma'lumotlarni olish imkoniyatini berdi. Shunday qilib, siz ko'rib turganingizdek, bu erda hamma narsa muhim, tk. biri ikkinchisiga asoslanadi - asosiy tuzilmani bilmasdan, biz, masalan, jami hisoblashimiz kerak bo'lgan ma'lumotlarni to'g'ri tanlay olmaymiz. Bu erda men ataylab faqat asosiy narsalarni ko'rsatishga harakat qilaman, shunda boshlang'ichning e'tiborini eng muhim tuzilmalarga qaratish va ularni keraksiz ma'lumotlar bilan ortiqcha yuklamaslik kerak. Asosiy tuzilmalarni yaxshi tushunish (bu haqda keyingi qismlarda gapirishni davom ettiraman) sizga RDB dan ma'lumotlarni olishning deyarli har qanday muammosini hal qilish imkoniyatini beradi. SELECT bayonotining asosiy konstruktsiyalari deyarli barcha ma'lumotlar bazasida bir xil shaklda qo'llaniladi (farqlar asosan tafsilotlarda, masalan, funktsiyalarni bajarishda - satrlar, vaqt va boshqalar bilan ishlash uchun). Keyinchalik, bazani yaxshi bilish sizga SQL tilining turli kengaytmalarini osongina o'rganish imkoniyatini beradi, masalan:
Agar siz SQL-da birinchi qadamlaringizni qo'yayotgan bo'lsangiz, unda birinchi navbatda asosiy konstruktsiyalarni o'rganishga e'tibor qarating Bazaga ega bo'lgan holda, qolgan hamma narsani o'zingiz tushunishingiz osonroq bo'ladi va bundan tashqari. Avvalo, siz SQL tilining imkoniyatlarini chuqur tushunishingiz kerak, ya'ni. odatda ma'lumotlarda qanday operatsiyani bajarishga imkon beradi. Yangi boshlanuvchilarga ma'lumotni hajmli shaklda etkazish men faqat eng muhim (temir) tuzilmalarni ko'rsatishimning sabablaridan biridir. SQL tilini o'rganish va tushunishda omad tilaymiz. To'rtinchi qism - Buyruq CASE sizga tanlash imkonini beradi bitta dan bir nechta buyruqlar ketma-ketligi... Bu konstruksiya SQL standartida 1992 yildan beri mavjud, garchi u Oracle SQL da Oracle8igacha va PL/SQL da Oracle9i Release 1 ga qadar qoʻllab-quvvatlanmagan. Ushbu versiyadan boshlab CASE buyruqlarining quyidagi turlari qoʻllab-quvvatlanadi:
NULL yoki noma'lummi?IF bayonoti haqidagi maqolada siz mantiqiy ifodaning natijasi TRUE, FALSE yoki NULL bo'lishi mumkinligini bilib olgan bo'lishingiz mumkin. PL/SQLda bu to'g'ri, lekin relyatsion nazariyaning kengroq kontekstida mantiqiy ifodadan NULLni qaytarish haqida gapirish noto'g'ri hisoblanadi. Munosabatlar nazariyasi NULL bilan taqqoslash shunday ekanligini aytadi: 2 < NULL mantiqiy natijani beradi UNKNOWN va UNKNOWN NULL emas. Biroq, PL/SQL-ning NULL-dan noma'lum uchun foydalanishi haqida juda ko'p tashvishlanmasligingiz kerak. Biroq, 3-qiymatli mantiqdagi uchinchi qiymat noma'lum ekanligini bilishingiz kerak. Va umid qilamanki, siz hech qachon (men qilgandek!) 3-qiymatli mantiqni aloqadorlik nazariyasi sohasidagi mutaxassislar bilan muhokama qilayotganda noto'g'ri atama tuzog'iga tushmaysiz. CASE buyruqlaridan tashqari, PL / SQL ham CASE ifodalarini qo'llab-quvvatlaydi. Bu ifoda CASE buyrug'iga juda o'xshaydi, u baholash uchun bir yoki bir nechta ifodalarni tanlash imkonini beradi. CASE ifodasining natijasi bitta qiymat, CASE buyrug'ining natijasi esa PL / SQL buyruqlari ketma-ketligining bajarilishidir. Oddiy CASE buyruqlariOddiy CASE buyrug'i ifodani baholash natijasiga ko'ra bajarish uchun PL / SQL buyruqlarining bir nechta ketma-ketliklaridan birini tanlash imkonini beradi. U quyidagicha yozilgan: CASE ifodasi QAChON natija_1 KEYIN buyrug'i_1 QAChON natija_2 KEYIN buyruq_2 ... BOSHQA command_alse TO'XTIRISH CASE; Bu yerda ELSE filiali ixtiyoriy. Bunday buyruqni bajarayotganda, PL / SQL avval ifodani baholaydi va keyin natijani natija bilan solishtiradi_1. Agar ular mos kelsa, buyruqlar_1 bajariladi. Aks holda, natija_2 qiymati tekshiriladi va hokazo. Mana oddiy CASE buyrug'iga misol bo'lib, unda bonus o'zgaruvchilar_turi qiymatiga qarab hisoblanadi: CASE xodimi_turi QAChON "S" KEYIN ish haqi_bonus (xodim_identifikatori); QAChON "H" KEYIN SOATlik_bonus (xodimning_identifikatori); QAChON "C" KEYIN topshirilgan_bonus (xodim_identifikatori); BOSHQA yaroqsiz_xodim_turini KO'TARTIRISH; END CASE; Ushbu misolda aniq ELSE bandi mavjud, ammo umuman olganda bu shart emas. ELSE bandisiz PL/SQL kompilyatori quyidagi kodni bilvosita almashtiradi: BOSHQA ISHLAB CHIQISH_NOT_FOUND; Boshqacha qilib aytganda, agar siz ELSE kalit so'zini o'tkazib yuborsangiz va WHEN bandlaridagi natijalarning hech biri CASE buyrug'idagi ifoda natijasiga mos kelmasa, PL / SQL CASE_NOT_FOUND istisnosini keltirib chiqaradi. Bu buyruq va IF o'rtasidagi farq. IF buyrug'ida ELSE kalit so'zi bo'lmasa, shart bajarilmasa, hech narsa sodir bo'lmaydi, CASE buyrug'ida esa shunga o'xshash holat xatolikka olib keladi. Oddiy CASE buyrug'i yordamida bobning boshida tasvirlangan bonuslarni hisoblash mantiqini qanday amalga oshirishni ko'rish qiziqarli bo'ladi. Bir qarashda, bu imkonsiz bo'lib tuyuladi, ammo biznesga ijodiy kirishish bilan biz quyidagi yechimga kelamiz: Ish haqi> = 10000 VA ish haqi bo'lganda<=20000 THEN give_bonus(employee_id, 1500); WHEN salary >20.000 VA ish haqi<= 40000 THEN give_bonus(employee_id, 1000); WHEN salary >40000 KEYIN bonusni bering (xodimning identifikatori, 500); BOShQA berish_bonus (xodimning identifikatori, 0); END CASE; Bu erda muhim narsa shundaki, ifoda va natija elementlari skalyar qiymatlar yoki natijalari skalar qiymatlar bo'lgan ifodalar bo'lishi mumkin. Xuddi shu mantiqni amalga oshiruvchi IF ... THEN ... ELSIF buyrug'iga qaytsak, CASE buyrug'ida ELSE bo'limi aniqlanganligini, IF – THEN – ELSIF buyrug'ida esa ELSE kalit so'zi yo'qligini ko'rasiz. ELSE qo'shish sababi oddiy: agar bonus shartlaridan hech biri bajarilmasa, IF buyrug'i hech narsa qilmaydi va bonus nolga teng. Bunday holda, CASE buyrug'i xatolikni keltirib chiqaradi, shuning uchun nol mukofot bilan vaziyatni aniq dasturlash kerak. CASE_NOT_FOUND xatolarining oldini olish uchun tekshirilayotgan ifodaning har qanday qiymati uchun shartlardan kamida bittasi bajarilishiga ishonch hosil qiling. Yuqoridagi CASE TRUE buyrug'i ba'zilar uchun hiyla kabi ko'rinishi mumkin, lekin u haqiqatan ham CASE qidiruv buyrug'ini amalga oshiradi, bu haqda keyingi bo'limda gaplashamiz. CASE qidiruv buyrug'iCASE qidiruv buyrug'i mantiqiy ifodalar ro'yxatini tekshiradi; TRUE ga teng ifoda topilgach, u bilan bog'langan buyruqlar ketma-ketligini bajaradi. Aslini olganda, CASE qidirish buyrug'i oldingi bo'limda ko'rsatilgan CASE TRUE buyrug'iga o'xshaydi. CASE qidiruv buyrug'i quyidagi belgilarga ega: CASE WHEN ibora_1 KEYIN buyruq_1 QAChON ifoda_2 KEYIN buyruq_2 ... BOSHQA command_alse TOʻXTIRISH CASE; Bu bonuslarni hisoblash mantig'ini amalga oshirish uchun juda mos keladi: QACHON ish haqi> = 10000 VA ish haqi<=20000 THEN give_bonus(employee_id, 1500); WHEN salary >20.000 VA ish haqi<= 40000 THEN give_bonus(employee_id, 1000); WHEN salary >40000 KEYIN bonusni bering (xodimning identifikatori, 500); BOSHQA bonuslarni berish (xodimning identifikatori, 0); END CASE; CASE qidiruv buyrug'i oddiy buyruq kabi quyidagi qoidalarga bo'ysunadi:
QAChON shartlari yozilish tartibida tekshirilishi faktidan foydalanadigan bonusni hisoblash mantiqining yana bir amalga oshirilishini ko'rib chiqing. Individual iboralar soddaroq, ammo butun buyruqning ma'nosi aniqroq bo'ldi, deb ayta olamizmi? HOLDA QACHON ish haqi> 40000 KEYIN bonus bering (xodimning identifikatori, 500); QACHON ish haqi> 20000 KEYIN bonuslarni bering (xodimning identifikatori, 1000); QACHON ish haqi> = 10000 KEYIN bonusni bering (xodimning identifikatori, 1500); BOSHQA bonuslarni berish (xodimning identifikatori, 0); END CASE; Agar ma'lum bir xodimning maoshi 20 000 bo'lsa, unda birinchi ikkita shart YOLG'ON, uchinchisi esa RO'G'RI, shuning uchun xodim 1500 dollar bonus oladi. Agar ish haqi 21 000 bo'lsa, ikkinchi shartning natijasi TO'G'ri bo'ladi va bonus 1000 dollar bo'ladi. CASE buyrug'ining bajarilishi ikkinchi WHEN filialida tugaydi va uchinchi shart hatto tekshirilmaydi. CASE buyruqlarini yozishda ushbu yondashuvdan foydalanish kerakmi yoki yo'qmi - bu bahsli masala. Qanday bo'lmasin, shuni yodda tutingki, bunday buyruqni yozish mumkin va natija iboralar tartibiga bog'liq bo'lgan dasturlarni tuzatish va tahrirlashda alohida e'tibor talab etiladi. Bir hil WHEN shoxlarini tartibga solishga bog'liq bo'lgan mantiq ularni qayta tartibga solishda yuzaga keladigan xatolarning potentsial manbai hisoblanadi. Misol sifatida, quyidagi CASE qidirish buyrug'ini ko'rib chiqing, unda 20 000 ish haqi bilan WHEN bandidagi shart testi TRUE deb baholanadi: QACHON ish haqi 10000 dan 20000 gacha bo'lgan taqdirda, keyin bonuslarni berish (xodimning identifikatori, 1500); QACHON maosh 20000 dan 40000 gacha bo'lsa, keyin bonuslarni bering (xodimning identifikatori, 1000); ... Tasavvur qiling-a, ushbu dasturning boshqaruvchisi QAChON bandlarini ish haqining kamayish tartibida buyurtma qilish uchun beparvolik bilan qayta tartibga soladi. Bu imkoniyatni rad qilmang! Dasturchilar ko'pincha ichki tartib tushunchasiga asoslanib, chiroyli ishlaydigan kodni "takomillashtirishga" moyildirlar. Qayta tartibga solingan WHEN bandlari bilan CASE buyrug'i quyidagicha ko'rinadi: QACHON ish haqi 20000 dan 40000 gacha bo'lsa, keyin bonuslarni bering (xodimning identifikatori, 1000); QACHON maosh 10000 dan 20000 gacha bo'lsa, keyin bonuslarni bering (xodimning identifikatori, 1500); ... Bir qarashda hammasi to'g'ri, shunday emasmi? Afsuski, ikkita WHEN filialining bir-birining ustiga chiqishi tufayli dasturda makkor xato paydo bo'ladi. Endi 20 000 maoshga ega bo'lgan xodim talab qilinadigan 1500 o'rniga 1000 bonus oladi. Ba'zi hollarda WHEN filiallari o'rtasida bir-biriga o'xshash bo'lishi ma'qul bo'lishi mumkin, ammo iloji boricha undan qochish kerak. Har doim esda tutingki, filial tartibi muhim va allaqachon ishlayotgan kodni o'zgartirish istagini saqlang - "buzilmagan narsani tuzatmang". WHEN shartlari tartibda sinovdan o'tganligi sababli, ro'yxatning yuqori qismida eng ehtimoliy shartlarga ega bo'lgan filiallarni joylashtirish orqali kod samaradorligini biroz oshirishingiz mumkin. Bunga qo'shimcha ravishda, agar sizda "qimmat" ifodalarga ega bo'lgan filialingiz bo'lsa (masalan, muhim protsessor vaqti va xotirasini talab qiladigan), sinovdan o'tish ehtimolini kamaytirish uchun ularni oxiriga qo'yishingiz mumkin. Tafsilotlar uchun ichki o'rnatilgan IF buyruqlari bo'limiga qarang. CASE qidiruv buyruqlari bajariladigan buyruqlar mantiqiy ifodalar to‘plami bilan aniqlanganda qo‘llaniladi. Oddiy CASE buyrug'i bitta ifoda natijasiga ko'ra qaror qabul qilinganda qo'llaniladi.
Ichki CASE buyruqlariCASE buyruqlari, IF buyruqlari kabi, ichkariga joylashtirilishi mumkin. Masalan, ichki o'rnatilgan CASE buyrug'i bonus mantig'ining quyidagi (aniqcha chalkash) amalga oshirilishida paydo bo'ladi: HOLDA QACHON ish haqi> = 10000 KEYIN QAChON ish haqi<= 20000 THEN give_bonus(employee_id, 1500); WHEN salary >40000 KEYIN bonusni bering (xodimning identifikatori, 500); QACHON ish haqi> 20000 KEYIN_bonus bering (xodimning identifikatori, 1000); END CASE; QACHON ish haqi< 10000 THEN give_bonus(employee_id,0); END CASE; CASE buyrug'ida istalgan buyruqdan foydalanish mumkin, shuning uchun ichki CASE buyrug'i IF buyrug'i bilan osongina almashtiriladi. Xuddi shunday, har qanday buyruq IF ko'rsatmasi, shu jumladan CASE ichiga joylashtirilishi mumkin. CASE ifodalariCASE ifodalari CASE buyruqlari bilan bir xil vazifani bajaradi, lekin bajariladigan buyruqlar uchun emas, balki ifodalar uchun. Oddiy CASE ifodasi belgilangan skalyar qiymat asosida baholash uchun bir nechta ifodalardan birini tanlaydi. CASE qidiruv ifodasi roʻyxatdagi iboralarni ulardan biri TRUE ga baholanmaguncha ketma-ket baholaydi va keyin bogʻlangan ifoda natijasini qaytaradi. CASE iboralarining ushbu ikki ta'mi uchun sintaksis: Simple_Case_expression: = CASE ifodasi QAChON natija_1 KEYIN natija_iborasi_1 QAChON natija_2 KEYIN natija_ifodasi_2 ... BOSHQA natija_ifodasi_boshqa END; Qidiruv_holat_ifodasi: = HOZIR QAChON ifoda_1 KEYIN natija_ifodasi_1 QAChON ifoda_2 KEYIN natija_ifodasi_2 ... BOSHQA natija_ifoda_boshqa END; CASE ifodasi bitta qiymatni qaytaradi - baholash uchun tanlangan ifoda natijasi. Har bir WHEN bandi bitta natija ifodasi bilan bog'lanishi kerak (lekin buyruq emas). CASE ifodasi oxirida nuqtali vergul yoki END CASE mavjud emas. CASE ifodasi END kalit so‘zi bilan tugaydi. Quyida mantiqiy o'zgaruvchining qiymatini ko'rsatish uchun DBMS_OUTPUT paketining PUT_LINE protsedurasi bilan birgalikda ishlatiladigan oddiy CASE ifodasiga misol keltirilgan. boolean_true E'lon qilish BOOLEAN: = TRUE; boolean_false BOOLEAN: = FALSE; boolean_null BOOLEAN; FUNCTION boolean_to_varchar2 (BOUL TILIDA bayroq) QAYTISH VARCHAR2 IS BAŞLADI RETURN CASE bayrog'i QAChON TRUE SO'NG “Rost” QAChON FALSE SO'NG “False” BOShQA “NULL” END; OXIRI; BEGIN DBMS_OUTPUT.PUT_LINE (mantiqiy_to_varchar2 (mantiqiy_true)); DBMS_OUTPUT.PUT_LINE (mantiqiy_to_varchar2 (mantiqiy_noto'g'ri)); DBMS_OUTPUT.PUT_LINE (boolean_to_varchar2 (mantiqiy_null)); OXIRI; Bonuslarni hisoblash mantiqini amalga oshirish uchun siz ma'lum ish haqi uchun bonus qiymatini qaytaradigan CASE qidiruv ifodasidan foydalanishingiz mumkin: Ish haqi RAQAMNI E'lon qiling: = 20000; xodim_identifikatori NUMBER: = 36325; PROCEDURE give_bonus (emp_id IN NUMBER, bonus_amt IN NUMBER) IS BEGIN DBMS_OUTPUT.PUT_LINE (emp_id); DBMS_OUTPUT.PUT_LINE (bonus_amt); OXIRI; BEGIN berish_bonus (xodimning identifikatori, QAChON ish haqi> = 10000 VA ish haqi<= 20000 THEN 1500 WHEN salary >20.000 VA ish haqi<= 40000 THEN 1000 WHEN salary >40 000 KEYIN 500 BOSHQA 0 END); OXIRI; CASE ifodasi har qanday boshqa turdagi ifodalardan foydalanish mumkin bo'lgan joyda ishlatilishi mumkin. Quyidagi misolda mukofotni hisoblash, uni 10 ga ko'paytirish va natijani DBMS_OUTPUT tomonidan ko'rsatilgan o'zgaruvchiga belgilash uchun CASE ifodasi qo'llaniladi: Ish haqi RAQAMNI E'lon qiling: = 20000; xodim_identifikatori NUMBER: = 36325; bonus_summasi NUMBER; BEGIN bonus_miqdori: = QAChON ish haqi> = 10000 VA ish haqi<= 20000 THEN 1500 WHEN salary >20.000 VA ish haqi<= 40000 THEN 1000 WHEN salary >40000 KEYIN 500 BOSHQA 0 END * 10; DBMS_OUTPUT.PUT_LINE (bonus_summasi); OXIRI; CASE buyrug'idan farqli o'laroq, agar WHEN bandi bajarilmasa, CASE ifodasi xatoga yo'l qo'ymaydi, shunchaki NULLni qaytaradi. Ommabop
Saytda yangi
|

























