Die Frobenius-Norm ist keine Operatornorm. Matrixnormen
»Lektion 12. Der Rang der Matrix. Berechnung des Rangs der Matrix. Matrixnorm
Lektion Nummer 12. Der Rang der Matrix. Berechnung des Rangs der Matrix. Matrizennorm.
Wenn alle Minderjährigen der MatrixEINAuftragkgleich Null sind, dann sind alle Minor der Ordnung k + 1, falls solche existieren, ebenfalls gleich Null.
Nach dem Rang der Matrix EIN
ist die größte der Ordnungen der Minderjährigen der Matrix EIN
ungleich null.
Der maximale Rang kann gleich der minimalen Anzahl der Zeilen oder Spalten der Matrix sein, d.h. Wenn die Matrix 4x5 ist, beträgt der maximale Rang 4.
Der Mindestrang einer Matrix ist 1, es sei denn, Sie haben es mit einer Null-Matrix zu tun, bei der der Rang immer Null ist.
Der Rang einer nicht entarteten quadratischen Matrix der Ordnung n ist gleich n, da ihre Determinante eine untergeordnete der Ordnung n ist und die nicht entartete Matrix ungleich Null ist.
Wenn eine Matrix transponiert wird, ändert sich ihr Rang nicht.
Der Rang der Matrix sei. Dann wird jeder Minor der Ordnung ungleich null aufgerufen Basis Moll.
Beispiel. Gegebene Matrix A. 
Die Determinante der Matrix ist Null.
Minderjähriger zweiter Ordnung ![]() ... Daher ist r (A) = 2 und das grundlegende Moll.
... Daher ist r (A) = 2 und das grundlegende Moll.
Die Basis-Moll ist auch die Moll ![]() .
.
Unerheblich ![]() schon seit = 0, also wird es nicht einfach sein.
schon seit = 0, also wird es nicht einfach sein.
Übung: unabhängig prüfen, welche anderen Minderjährigen zweiter Ordnung Basic sind und welche nicht.
Den Rang einer Matrix durch Berechnung aller Nebenwerte zu ermitteln, erfordert zu viel Rechenarbeit. (Der Leser kann überprüfen, dass es in einer quadratischen Matrix vierter Ordnung 36 Minor zweiter Ordnung gibt.) Daher wird ein anderer Algorithmus verwendet, um den Rang zu finden. Zur Beschreibung sind eine Reihe zusätzlicher Informationen erforderlich.
Nennen wir die folgenden Aktionen auf Matrizen elementare Transformationen von Matrizen:
1) Permutation von Zeilen oder Spalten;
2) Multiplizieren einer Zeile oder Spalte mit einer anderen Zahl als Null;
3) Hinzufügen einer weiteren Zeile multipliziert mit einer Zahl zu einer der Zeilen oder Addieren zu einer der Spalten einer anderen Spalte multipliziert mit einer Zahl.
Elementare Transformationen ändern den Rang der Matrix nicht.
Algorithmus zur Berechnung des Rangs einer Matrixähnelt dem Algorithmus zur Berechnung der Determinante und besteht darin, dass die Matrix mit elementaren Transformationen auf eine einfache Form reduziert wird, für die es nicht schwer ist, den Rang zu finden. Da sich der Rang nicht bei jeder Transformation änderte, finden wir dadurch durch Berechnung des Rangs der transformierten Matrix den Rang der ursprünglichen Matrix.
Es sei erforderlich, den Rang der Größenmatrix zu berechnen mxn.

Als Ergebnis von Berechnungen hat die Matrix A1 die Form 

Wenn alle Zeilen ab der dritten Null sind, dann ![]() seit Minor
seit Minor ![]() ... Andernfalls erreichen wir durch Neuanordnen von Zeilen und Spalten mit Zahlen größer als zwei, dass das dritte Element der dritten Zeile ungleich Null ist. Wenn wir außerdem die dritte Zeile multipliziert mit den entsprechenden Zahlen zu den Zeilen mit großen Zahlen addieren, erhalten wir Nullen in der dritten Spalte, beginnend mit dem vierten Element und so weiter.
... Andernfalls erreichen wir durch Neuanordnen von Zeilen und Spalten mit Zahlen größer als zwei, dass das dritte Element der dritten Zeile ungleich Null ist. Wenn wir außerdem die dritte Zeile multipliziert mit den entsprechenden Zahlen zu den Zeilen mit großen Zahlen addieren, erhalten wir Nullen in der dritten Spalte, beginnend mit dem vierten Element und so weiter.
Irgendwann kommen wir zu einer Matrix, in der alle Zeilen, beginnend mit dem (r + 1)-ten, gleich Null sind (oder für fehlen), und der Minor in den ersten Zeilen und ersten Spalten die Determinante von a . ist Dreiecksmatrix mit Elementen ungleich Null auf der Diagonale ... Der Rang einer solchen Matrix ist. Daher ist Rang (A) = r.
Bei dem vorgeschlagenen Algorithmus zum Ermitteln des Rangs einer Matrix sollten alle Berechnungen ohne Rundung durchgeführt werden. Eine beliebig kleine Änderung mindestens eines der Elemente der Zwischenmatrizen kann dazu führen, dass die erhaltene Antwort um mehrere Einheiten vom Rang der ursprünglichen Matrix abweicht.
Wenn die Elemente in der ursprünglichen Matrix ganze Zahlen waren, ist es praktisch, Berechnungen ohne Brüche durchzuführen. Daher ist es ratsam, in jeder Phase die Strings mit Zahlen zu multiplizieren, damit bei den Berechnungen keine Brüche auftauchen.
Betrachten Sie in der praktischen Laborarbeit ein Beispiel für die Ermittlung des Rangs einer Matrix.
LAGE-ALGORITHMUS MATRIX-STANDARDS
.
Es gibt nur drei Matrixnormen.
Die erste Norm der Matrix= das Maximum der Zahlen, die durch Addition aller Elemente jeder Spalte erhalten werden, modulo genommen.
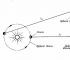
Beispiel: Gegeben sei eine 3x2-Matrix A (Abb. 10). Die erste Spalte enthält Elemente: 8, 3, 8. Alle Elemente sind positiv. Finden wir ihre Summe: 8 + 3 + 8 = 19. Die zweite Spalte enthält Elemente: 8, -2, -8. Zwei Elemente sind negativ, daher muss beim Addieren dieser Zahlen der Modul dieser Zahlen ersetzt werden (dh ohne die "Minus"-Zeichen). Finden wir ihre Summe: 8 + 2 + 8 = 18. Das Maximum dieser beiden Zahlen ist 19. Die erste Norm der Matrix ist also 19.

Abbildung 10.
Zweite Norm der Matrix ist die Quadratwurzel der Summe der Quadrate aller Elemente der Matrix. Und das bedeutet, dass wir alle Elemente der Matrix quadrieren, dann die resultierenden Werte addieren und die Quadratwurzel aus dem Ergebnis ziehen.
In unserem Fall ist die 2-Norm der Matrix gleich der Quadratwurzel von 269. Im Diagramm habe ich grob die Quadratwurzel von 269 extrahiert und als Ergebnis etwa 16.401 erhalten. Obwohl es richtiger ist, die Wurzel nicht zu extrahieren. 
Dritte Norm der Matrix ist das Maximum der Zahlen, die durch Addieren aller Elemente jeder Reihe erhalten werden, modulo genommen.
In unserem Beispiel: Die erste Zeile enthält Elemente: 8, 8. Alle Elemente sind positiv. Finden wir ihre Summe: 8 + 8 = 16. Die zweite Zeile enthält Elemente: 3, -2. Eines der Elemente ist negativ, daher müssen Sie beim Addieren dieser Zahlen den Modul dieser Zahl ersetzen. Finden wir ihre Summe: 3 + 2 = 5. Die dritte Zeile enthält die Elemente 8 und -8. Eines der Elemente ist negativ, daher müssen Sie beim Addieren dieser Zahlen den Modul dieser Zahl ersetzen. Finden wir ihre Summe: 8 + 8 = 16. Das Maximum dieser drei Zahlen ist 16. Die dritte Norm der Matrix ist also 16. 
Zusammengestellt von: Saliy N.A.
College-YouTube
1 / 1
✪ Vektornorm. Teil 4.
Untertitel
Definition
Sei K das Grundfeld (normalerweise K = R oder K = C ) und ist der lineare Raum aller Matrizen mit m Zeilen und n Spalten, bestehend aus Elementen K. Auf dem Raum der Matrizen ist eine Norm gegeben, wenn jeder Matrix eine nicht negative reelle Zahl zugeordnet ist ‖ A ‖ (\ displaystyle \ | A \ |), nannte seine Norm, damit
Bei quadratischen Matrizen (d.h. m = n) können Matrizen multipliziert werden, ohne den Raum zu verlassen, und daher erfüllen die Normen in diesen Räumen normalerweise auch die Eigenschaft Submultiplikativität :
Submultiplikativität kann auch für die Normen von nicht quadratischen Matrizen durchgeführt werden, jedoch für mehrere erforderliche Größen gleichzeitig definiert werden. Ist A nämlich eine Matrix ℓ × m, und B ist die Matrix m × n, dann A B- Matrix ℓ × n .
Betreibernormen
Eine wichtige Klasse von Matrixnormen sind Betreibernormen, auch bezeichnet als Untergeordnete oder induziert ... Die Operatornorm ist eindeutig nach zwei in und definierten Normen konstruiert, ausgehend davon, dass jede Matrix m × n wird durch einen linearen Operator aus . dargestellt K n (\ Anzeigestil K ^ (n)) v K m (\ Anzeigestil K ^ (m))... Speziell,
‖ A ‖ = sup (‖ A x ‖: x K n, ‖ x ‖ = 1) = sup (‖ A x ‖ ‖ x ‖: x ∈ K n, x ≠ 0). (\ displaystyle (\ begin (aligned) \ | A \ | & = \ sup \ (\ | Ax \ |: x \ in K ^ (n), \ \ | x \ | = 1 \) \\ & = \ sup \ left \ ((\ frac (\ | Ax \ |) (\ | x \ |)): x \ in K ^ (n), \ x \ neq 0 \ right \). \ end (aligned)))Unter der Bedingung einer konsistenten Spezifikation von Normen auf Vektorräumen ist eine solche Norm submultiplikativ (siehe).
Beispiele für Betreibernormen
Spektrale Normeigenschaften:
- Die Spektralnorm eines Operators ist gleich der maximalen Singularzahl dieses Operators.
- Die Spektralnorm eines Normaloperators ist gleich dem Betrag des maximalen Modulo-Eigenwertes dieses Operators.
- Die Spektralnorm ändert sich nicht, wenn die Matrix mit einer orthogonalen (einheitlichen) Matrix multipliziert wird.
Nicht-Betreiber-Matrix-Normen
Es gibt Matrixnormen, die keine Operatornormen sind. Das Konzept der Nicht-Operator-Normen von Matrizen wurde von Yu I. Lyubich eingeführt und von G. R. Belitskii untersucht.
Ein Beispiel für eine Nichtoperatornorm
Betrachten Sie zum Beispiel zwei verschiedene Operatornormen ‖ A ‖ 1 (\ displaystyle \ | A \ | _ (1)) und ‖ A ‖ 2 (\ displaystyle \ | A \ | _ (2)), wie Zeilen- und Spaltennormen. Bildung einer neuen Norm ‖ A ‖ = m a x (‖ A ‖ 1, ‖ A ‖ 2) (\ displaystyle \ | A \ | = max (\ | A \ | _ (1), \ | A \ | _ (2)))... Die neue Norm hat die Ringeigenschaft ‖ A B ‖ ≤ ‖ A ‖ ‖ B ‖ (\ displaystyle \ | AB \ | \ leq \ | A \ | \ | B \ |), bewahrt die Einheit ‖ I ‖ = 1 (\ displaystyle \ | I \ | = 1) und ist kein Betreiber.
Beispiele für Normen
Vektor p (\ Anzeigestil p)-Norm
Es kann in Betracht genommen werden m × n (\ displaystyle m \ mal n) Matrix als Vektor der Größe m n (\ Anzeigestil mn) und verwenden Sie Standardvektornormen:
‖ A ‖ p = ‖ vec (A) ‖ p = (∑ i = 1 m ∑ j = 1 n | aij | p) 1 / p (\ displaystyle \ | A \ | _ (p) = \ | \ mathrm ( vec) (A) \ | _ (p) = \ links (\ sum _ (i = 1) ^ (m) \ sum _ (j = 1) ^ (n) | a_ (ij) | ^ (p) \ rechts) ^ (1 / p))Frobenius-Norm
Frobenius-Norm, oder Euklidische Norm ist ein Spezialfall der p-Norm für P = 2 : ‖ A ‖ F = ∑ i = 1 m ∑ j = 1 naij 2 (\ displaystyle \ | A \ | _ (F) = (\ sqrt (\ sum _ (i = 1) ^ (m) \ sum _ (j = 1) ^ (n) a_ (ij) ^ (2)))).
Die Frobenius-Norm ist leicht zu berechnen (im Vergleich z. B. mit der Spektralnorm). Besitzt die folgenden Eigenschaften:
‖ A x ‖ 2 2 = ∑ i = 1 m | ∑ j = 1 n a i j x j | 2 ≤ ∑ i = 1 m (∑ j = 1 n | a i j | 2 ∑ j = 1 n | x j | 2) = ∑ j = 1 n | x j | 2 ‖ A ‖ F 2 = ‖ A ‖ F 2 ‖ x ‖ 2 2. (\ displaystyle \ | Ax \ | _ (2) ^ (2) = \ sum _ (i = 1) ^ (m) \ left | \ sum _ (j = 1) ^ (n) a_ (ij) x_ ( j) \ right | ^ (2) \ leq \ sum _ (i = 1) ^ (m) \ left (\ sum _ (j = 1) ^ (n) | a_ (ij) | ^ (2) \ sum _ (j = 1) ^ (n) | x_ (j) | ^ (2) \ rechts) = \ Summe _ (j = 1) ^ (n) | x_ (j) | ^ (2) \ | A \ | _ (F) ^ (2) = \ | A \ | _ (F) ^ (2) \ | x \ | _ (2) ^ (2).)- Submultiplikativität: ‖ A B ‖ F ≤ ‖ A ‖ F ‖ B ‖ F (\ displaystyle \ | AB \ | _ (F) \ leq \ | A \ | _ (F) \ | B \ | _ (F)), als ‖ A B ‖ F 2 = ∑ i, j | k a i k b k j | 2 ≤ i, j (∑ k | a i k | | b k j |) 2 ≤ i, j (∑ k | a i k | 2 ∑ k | b k j | 2) = ∑ i, k | a i k | 2 k, j | b k j | 2 = ‖ A ‖ F 2 ‖ B ‖ F 2 (\ displaystyle \ | AB \ | _ (F) ^ (2) = \ sum _ (i, j) \ left | \ sum _ (k) a_ (ik) b_ (kj) \ right | ^ (2) \ leq \ sum _ (i, j) \ left (\ sum _ (k) | a_ (ik) || b_ (kj) | \ right) ^ (2) \ leq \ sum _ (i, j) \ left (\ sum _ (k) | a_ (ik) | ^ (2) \ sum _ (k) | b_ (kj) | ^ (2) \ right) = \ sum _ (i, k) | a_ (ik) | ^ (2) \ sum _ (k, j) | b_ (kj) | ^ (2) = \ | A \ | _ (F) ^ (2) \ | B \ | _ (F) ^ (2)).
- ‖ A ‖ F 2 = tr A ∗ A = tr AA ∗ (\ displaystyle \ | A \ | _ (F) ^ (2) = \ mathop (\ rm (tr)) A ^ (*) A = \ mathop (\ rm (tr)) AA ^ (*)), wo t r A (\ displaystyle \ mathop (\ rm (tr)) A)- Matrixspur A (\ Anzeigestil A), A ∗ (\ Anzeigestil A ^ (*)) ist eine hermitesch konjugierte Matrix.
- ‖ A ‖ F 2 = ρ 1 2 + ρ 2 2 + ⋯ + ρ n 2 (\ displaystyle \ | A \ | _ (F) ^ (2) = \ rho _ (1) ^ (2) + \ rho _ (2) ^ (2) + \ Punkte + \ Rho _ (n) ^ (2)), wo ρ 1, ρ 2,…, ρ n (\ displaystyle \ rho _ (1), \ rho _ (2), \ Punkte, \ rho _ (n))- Singulärwerte der Matrix A (\ Anzeigestil A).
- ‖ A ‖ F (\ displaystyle \ | A \ | _ (F))ändert sich nicht bei der Matrixmultiplikation A (\ Anzeigestil A) links oder rechts in orthogonale (unitäre) Matrizen.
Modul maximal
Die Modulmaximalnorm ist ein weiterer Spezialfall der p-Norm für P = ∞ .
‖ A ‖ max = max (| a i j |). (\ displaystyle \ | A \ | _ (\ text (max)) = \ max \ (| a_ (ij) | \).)Schattens Norm
Konsistenz von Matrix- und Vektornormen
Matrixnorm ‖ ⋅ ‖ a b (\ displaystyle \ | \ cdot \ | _ (ab)) An K m × n (\ displaystyle K ^ (m \ mal n)) namens einverstanden mit Normen ‖ ⋅ ‖ a (\ displaystyle \ | \ cdot \ | _ (a)) An K n (\ Anzeigestil K ^ (n)) und ‖ ⋅ ‖ b (\ displaystyle \ | \ cdot \ | _ (b)) An K m (\ Anzeigestil K ^ (m)), wenn:
‖ A x ‖ b ≤ ‖ A ‖ a b ‖ x ‖ a (\ displaystyle \ | Ax \ | _ (b) \ leq \ | A \ | _ (ab) \ | x \ | _ (a))für jeden A ∈ K m × n, x ∈ K n (\ displaystyle A \ in K ^ (m \ mal n), x \ in K ^ (n))... Die Operatornorm ist durch Konstruktion konsistent mit der ursprünglichen Vektornorm.
Beispiele für vereinbarte, aber nicht untergeordnete Matrixnormen:
Gleichwertigkeit von Normen
Alle Normen im Weltraum K m × n (\ displaystyle K ^ (m \ mal n)) sind äquivalent, d. h. für zwei beliebige Normen . ‖ Α (\ displaystyle \ |. \ | _ (\ Alpha)) und . ‖ Β (\ displaystyle \ |. \ | _ (\ Beta)) und für jede Matrix A ∈ K m × n (\ displaystyle A \ in K ^ (m \ mal n)) die doppelte Ungleichung ist wahr.
Matrixnorm wir nennen die dieser Matrix zugewiesene reelle Zahl || A || so dass die als reelle Zahl jeder Matrix aus dem n-dimensionalen Raum zugeordnet ist und 4 Axiome erfüllt:
1. || A || ³0 und || A || = 0 nur wenn A eine Nullmatrix ist;
2. ||αA || = |α|·||A ||, wobei a R;
3. || A + B || £ || A || + || B ||;
4. || A · B || £ || A || · || B ||. (multiplikative Eigenschaft)
Die Norm der Matrizen kann auf verschiedene Weise eingegeben werden. Matrix A kann betrachtet werden als n 2 - dimensionaler Vektor.
Diese Norm wird als euklidische Norm der Matrix bezeichnet.
Wenn für eine beliebige quadratische Matrix A und einen beliebigen Vektor x, dessen Dimension gleich der Ordnung der Matrix ist, die Ungleichung || Ax || £ || A || · || x ||
dann heißt die Norm der Matrix A konsistent mit der Norm des Vektors. Beachten Sie, dass links von der letzten Bedingung die Norm des Vektors steht (Ax ist ein Vektor).
Der gegebenen Vektornorm sind verschiedene Matrixnormen zugeordnet. Wählen wir den kleinsten unter ihnen aus. Das wird sein
Diese Matrixnorm ist einer gegebenen Vektornorm untergeordnet. Die Existenz eines Maximums in diesem Ausdruck folgt aus der Stetigkeit der Norm, da es immer einen Vektor x -> || x || = 1 und || Ax || = || A || gibt.
Zeigen wir, dass die Norm N (A) keiner Vektornorm unterliegt. Die Normen der Matrix, vorbehaltlich der zuvor eingeführten Vektornormen, werden wie folgt ausgedrückt:
1. ||A || ¥ = |a ij | (Norm-Maximum)
2. ||A || 1 = |a ij | (Normsumme)
3. ||A || 2 =, (Spektralnorm)
wobei s 1 der größte Eigenwert der symmetrischen Matrix A ¢ A ist, der das Produkt der transponierten und der ursprünglichen Matrizen ist. T k die Matrix A ¢ A symmetrisch ist, dann sind alle ihre Eigenwerte reell und positiv. Die Anzahl der l -Eigenschaften ist der Wert, und der von Null verschiedene Vektor x ist der Eigenvektor der Matrix A (wenn sie durch die Beziehung Ax = lx zusammenhängen). Ist die Matrix A selbst symmetrisch, A ¢ = A, dann gilt A ¢ A = A 2 und dann s 1 =, wobei der größte Modulo-Eigenwert der Matrix A ist. In diesem Fall gilt also =.
Die Eigenwerte der Matrix überschreiten keine ihrer vereinbarten Normen. Normalisieren wir die Relation, die die Eigenwerte definiert, erhalten wir || λx || = || Ax ||, | λ | · || x || = || Ax || £ || A || · || x ||, | λ | £ || A ||
Da gilt || A || 2 £ || A || e, wo die euklidische Norm leicht zu berechnen ist, kann in den Schätzungen anstelle der spektralen Norm die euklidische Norm der Matrix verwendet werden.
30. Konditionalität von Gleichungssystemen. Konditionalitätsfaktor .
Konditionalität- den Einfluss der Entscheidung auf die Ausgangsdaten. Ax = b: Vektor B Match-Lösung x... Lassen B wird sich um den Betrag ändern. Dann ist der Vektor b + die neue Lösung wird passen x + : A (x + ) = b +... Da das System linear ist, dann Axt + A = b +, dann EIN = ; = ; = ; b = Ax; = dann; *, wo ist der relative Fehler der Lösungsstörung, - ZustandsfaktorBedingung (A) (wie oft kann der Lösungsfehler zunehmen), ist die relative Störung des Vektors B. Bedingung (A) = ; Bedingung (A) * Koeffizienteneigenschaften: hängt von der Wahl der Matrixnorm ab; Bedingung ( = Bedingung (A); Das Multiplizieren einer Matrix mit einer Zahl hat keinen Einfluss auf den Bedingungsfaktor. Je größer der Koeffizient ist, desto stärker beeinflusst der Fehler in den Anfangsdaten die Lösung des SLAE. Die Konditionsnummer darf nicht kleiner als 1 sein.
31. Die Sweep-Methode zum Lösen von Systemen linearer algebraischer Gleichungen.
Es ist oft notwendig, Systeme zu lösen, deren Matrizen schwach gefüllt sind, d.h. viele Elemente ungleich null enthalten. Die Matrizen solcher Systeme haben meist eine bestimmte Struktur, darunter auch Systeme mit Matrizen einer Streifenstruktur, d.h. in ihnen befinden sich Elemente ungleich null auf der Hauptdiagonalen und auf mehreren Seitendiagonalen. Zum Lösen von Systemen mit Streifenmatrizen kann die Gaußsche Methode in effizientere Methoden umgewandelt werden. Betrachten wir den einfachsten Fall von Bandsystemen, zu dem, wie wir später sehen werden, die Lösung von Diskretisierungsproblemen für Randwertprobleme für Differentialgleichungen durch die Methoden der finiten Differenzen, finiten Elemente usw. benachbart ist:
Drei diagonale Matrizen haben nur (3n-2) Einträge ungleich null.
Benennen wir die Koeffizienten der Matrix um:
Dann kann das System in Komponentennotation dargestellt werden als:
A i * x i-1 + b i * x i + c i * x i + 1 = d i , i = 1, 2, ..., n; (7)
a 1 = 0, c n = 0. (acht)
Die Struktur des Systems geht nur von einer Beziehung zwischen benachbarten Unbekannten aus:
x i = x i * x i +1 + h i (9)
x i -1 = x i -1 * x i + h i -1 und in (7) einsetzen:
A i (x i-1 * x i + h i-1) + b i * x i + c i * x i + 1 = d i
(a i * x i-1 + b i) x i = –c i * x i + 1 + d i –a i * h i-1
Vergleichen wir den resultierenden Ausdruck mit der Darstellung (7), erhalten wir:
Formeln (10) repräsentieren Rekursionsbeziehungen zum Berechnen der Sweep-Koeffizienten. Sie erfordern das Setzen von Anfangswerten. Gemäß der ersten Bedingung (8) für i = 1 gilt a 1 = 0, also
Weiterhin werden die restlichen Sweep-Koeffizienten berechnet und gemäß den Formeln (10) für i = 2,3, ..., n gespeichert und für i = n erhalten wir unter Berücksichtigung der zweiten Bedingung (8) xn = 0 . Daher gilt gemäß Formel (9) x n = h n.
Danach werden gemäß der Formel (9) die Unbekannten x n -1, x n -2, ..., x 1 sequentiell gefunden. Dieser Schritt der Berechnung wird als Rückwärtslauf bezeichnet, während die Berechnung der Sweep-Faktoren als Vorwärts-Sweep bezeichnet wird.
Für die erfolgreiche Anwendung des Sweep-Verfahrens ist es erforderlich, dass bei Berechnungen keine Situationen mit Division durch Null auftreten und bei einer großen Dimension der Systeme die Rundungsfehler nicht schnell zunehmen. Wir werden den Lauf nennen Korrekt wenn der Nenner der Sweep-Koeffizienten (10) nicht verschwindet, und nachhaltig wenn ½x ich ½<1 при всех i=1,2,…, n. Достаточные условия корректности и устойчивости прогонки, которые во многих приложениях выполняются, определяются теоремой.
Satz. Die Koeffizienten a i und c i der Gleichung (7) für i = 2,3, ..., n-1 seien von Null verschieden und seien
½b i ½> ½a i ½ + ½c i ½ für i = 1, 2, ..., n. (elf)
Dann ist der durch die Formeln (10), (9) definierte Sweep korrekt und stabil.