La norma di Frobenius non è una norma degli operatori. Norme di matrice
»Lezione 12. Il rango della matrice. Calcolo del rango della matrice. Norma matrice
Lezione numero 12. Il rango della matrice. Calcolo del rango della matrice. Norma delle matrici.
Se tutti i minori della matriceUNordineKsono uguali a zero, allora anche tutti i minori di ordine k + 1, se esistono, sono uguali a zero.
Per il rango della matrice UN
è il più grande degli ordini dei minori della matrice UN
diverso da zero.
Il rango massimo può essere uguale al numero minimo del numero di righe o colonne della matrice, ad es. se la matrice è 4x5, il rango massimo sarà 4.
Il rango minimo di una matrice è, a meno che non si tratti di una matrice zero, dove il rango è sempre zero.
Il rango di una matrice quadrata non degenere di ordine n è uguale a n, poiché il suo determinante è un minore di ordine n e la matrice non degenere è diversa da zero.
Quando una matrice viene trasposta, il suo rango non cambia.
Sia il rango della matrice. Quindi viene chiamato qualsiasi minore di ordine diverso da zero base minore.
Esempio. Data la matrice A. 
Il determinante della matrice è zero.
Minore del secondo ordine ![]() ... Pertanto, r (A) = 2 e il minore di base.
... Pertanto, r (A) = 2 e il minore di base.
Il minore di base è anche il minore ![]() .
.
Minore ![]() da = 0, quindi non sarà di base.
da = 0, quindi non sarà di base.
Esercizio: verificare autonomamente quali altri minori di secondo ordine saranno basic e quali no.
Trovare il rango di una matrice calcolando tutti i suoi minori richiede troppo lavoro di calcolo. (Il lettore può verificare che ci sono 36 minori di secondo ordine in una matrice quadrata di quarto ordine.) Pertanto, viene utilizzato un algoritmo diverso per trovare il rango. Per descriverlo sono necessarie alcune informazioni aggiuntive.
Chiamiamo le seguenti azioni sulle matrici trasformazioni elementari di matrici:
1) permutazione di righe o colonne;
2) moltiplicare una riga o una colonna per un numero diverso da zero;
3) aggiungendo a una delle righe un'altra riga moltiplicata per un numero o sommando a una delle colonne di un'altra colonna moltiplicata per un numero.
Le trasformazioni elementari non cambiano il rango della matrice.
Algoritmo per il calcolo del rango di una matriceè simile all'algoritmo per il calcolo del determinante e consiste nel fatto che, utilizzando trasformazioni elementari, la matrice viene ridotta a una forma semplice, per la quale non è difficile trovare il rango. Poiché il rango non cambia ad ogni trasformazione, calcolando il rango della matrice trasformata, troviamo quindi il rango della matrice originale.
Sia richiesto di calcolare il rango della matrice delle dimensioni mXn.

Come risultato dei calcoli, la matrice A1 ha la forma 

Se tutte le righe che iniziano dalla terza sono zero, allora ![]() da minorenne
da minorenne ![]() ... Altrimenti, riordinando righe e colonne con numeri maggiori di due, otteniamo che il terzo elemento della terza riga sia diverso da zero. Inoltre, aggiungendo la terza riga, moltiplicata per i numeri corrispondenti, alle righe con numeri grandi, otteniamo degli zeri nella terza colonna, a partire dal quarto elemento, e così via.
... Altrimenti, riordinando righe e colonne con numeri maggiori di due, otteniamo che il terzo elemento della terza riga sia diverso da zero. Inoltre, aggiungendo la terza riga, moltiplicata per i numeri corrispondenti, alle righe con numeri grandi, otteniamo degli zeri nella terza colonna, a partire dal quarto elemento, e così via.
Ad un certo punto, arriviamo a una matrice in cui tutte le righe, a partire dalla (r + 1) th, sono uguali a zero (o sono assenti per), e il minore nelle prime righe e nelle prime colonne è il determinante di a matrice triangolare con elementi diversi da zero sulla diagonale ... Il rango di tale matrice è. Pertanto, Rang (A) = r.
Nell'algoritmo proposto per trovare il rango di una matrice, tutti i calcoli devono essere eseguiti senza arrotondamenti. Un cambiamento arbitrariamente piccolo in almeno uno degli elementi delle matrici intermedie può portare al fatto che la risposta ottenuta differirà dal rango della matrice originale di diverse unità.
Se gli elementi nella matrice originale erano interi, è conveniente eseguire calcoli senza utilizzare le frazioni. Pertanto, in ogni fase, è consigliabile moltiplicare le stringhe per numeri in modo che le frazioni non compaiano nei calcoli.
Nel lavoro pratico di laboratorio, considera un esempio di ricerca del rango di una matrice.
ALGORITMO DI POSIZIONE STANDARD DI MATRICE
.
Ci sono solo tre norme matrice.
La prima norma della matrice= il massimo dei numeri ottenuti sommando tutti gli elementi di ogni colonna, presi modulo.
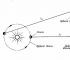
Esempio: sia data una matrice 3x2 A (Fig. 10). La prima colonna contiene elementi: 8, 3, 8. Tutti gli elementi sono positivi. Troviamo la loro somma: 8 + 3 + 8 = 19. La seconda colonna contiene elementi: 8, -2, -8. Due elementi sono negativi, quindi, quando si sommano questi numeri, è necessario sostituire il modulo di questi numeri (cioè senza i segni "meno"). Troviamo la loro somma: 8 + 2 + 8 = 18. Il massimo di questi due numeri è 19. Quindi la prima norma della matrice è 19.

Figura 10.
Seconda norma della matriceè la radice quadrata della somma dei quadrati di tutti gli elementi della matrice. E questo significa che quadratiamo tutti gli elementi della matrice, quindi aggiungiamo i valori risultanti ed estraiamo la radice quadrata dal risultato.
Nel nostro caso, la norma 2 della matrice è uguale alla radice quadrata di 269. Nel diagramma ho estratto approssimativamente la radice quadrata di 269 e di conseguenza ho ottenuto circa 16,401. Sebbene sia più corretto non estrarre la radice. 
Terza norma della matriceè il massimo dei numeri ottenuti sommando tutti gli elementi di ogni riga, presi modulo.
Nel nostro esempio: la prima riga contiene elementi: 8, 8. Tutti gli elementi sono positivi. Troviamo la loro somma: 8 + 8 = 16. La seconda riga contiene elementi: 3, -2. Uno degli elementi è negativo, quindi, quando si sommano questi numeri, è necessario sostituire il modulo di questo numero. Troviamo la loro somma: 3 + 2 = 5. La terza riga contiene gli elementi 8 e -8. Uno degli elementi è negativo, quindi, quando si sommano questi numeri, è necessario sostituire il modulo di questo numero. Troviamo la loro somma: 8 + 8 = 16. Il massimo di questi tre numeri è 16. Quindi la terza norma della matrice è 16. 
Compilato da: Saliy N.A.
YouTube collegiale
1 / 1
Norma vettoriale. Parte 4.
Sottotitoli
Definizione
Sia K il campo di terra (di solito K = R o K = C ) ed è lo spazio lineare di tutte le matrici con m righe e n colonne, costituito da elementi K. Sullo spazio delle matrici si dà una norma se ogni matrice è associata a un numero reale non negativo ‖ A ‖ (\ stile di visualizzazione \ | A \ |), chiamata la sua norma, così che
Nel caso di matrici quadrate (es. m = n), le matrici possono essere moltiplicate senza lasciare lo spazio, e quindi le norme in questi spazi di solito soddisfano anche la proprietà submoltiplicatività :
La submoltiplicatività può essere eseguita anche per le norme delle matrici non quadrate, ma definite per più dimensioni richieste contemporaneamente. Vale a dire, se A è una matrice ℓ × m, e B è la matrice m × n, poi A B- matrice ℓ × n .
Norme per gli operatori
Un'importante classe di norme matriciali sono norme dell'operatore, indicato anche come subordinati o indotto ... La norma dell'operatore è costruita in modo univoco secondo due norme definite in e, partendo dal fatto che qualsiasi matrice m × nè rappresentato da un operatore lineare da K n (\ stile di visualizzazione K ^ (n)) v K m (\ stile di visualizzazione K ^ (m))... Nello specifico,
‖ A ‖ = sup (‖ A x ‖: x ∈ K n, ‖ x ‖ = 1) = sup (‖ A x ‖ ‖ x ‖: x ∈ K n, x ≠ 0). (\ displaystyle (\ begin (allineato) \ | A \ | & = \ sup \ (\ | Ax \ |: x \ in K ^ (n), \ \ | x \ | = 1 \) \\ & = \ sup \ left \ ((\ frac (\ | Ax \ |) (\ | x \ |)): x \ in K ^ (n), \ x \ neq 0 \ right \). \ end (allineato)))A condizione di una specificazione coerente delle norme sugli spazi vettoriali, tale norma è submoltiplicativa (vedi).
Esempi di norme per gli operatori
Proprietà della norma spettrale:
- La norma spettrale di un operatore è uguale al numero singolare massimo di questo operatore.
- La norma spettrale di un operatore normale è uguale al valore assoluto dell'autovalore modulo massimo di questo operatore.
- La norma spettrale non cambia quando la matrice viene moltiplicata per una matrice ortogonale (unitaria).
Norme Matrix per non operatori
Esistono norme di matrice che non sono norme di operatori. Il concetto di norme non operatorie delle matrici è stato introdotto da Yu. I. Lyubich e studiato da G.R.Belitskii.
Un esempio di norma non operatore
Ad esempio, si considerino due diverse norme di operatori ‖ A ‖ 1 (\ stile di visualizzazione \ | A \ | _ (1)) e ‖ A ‖ 2 (\ stile di visualizzazione \ | A \ | _ (2)), come le norme di riga e colonna. Formare una nuova norma ‖ A ‖ = m a x (‖ A ‖ 1, ‖ A ‖ 2) (\ displaystyle \ | A \ | = max (\ | A \ | _ (1), \ | A \ | _ (2)))... La nuova norma ha la proprietà dell'anello ‖ A B ‖ ≤ ‖ A ‖ ‖ B ‖ (\ displaystyle \ | AB \ | \ leq \ | A \ | \ | B \ |), conserva l'unità ‖ I ‖ = 1 (\ stile di visualizzazione \ | I \ | = 1) e non è un operatore.
Esempi di norme
Vettore p (\ stile di visualizzazione p)-norma
Può essere considerato m × n (\ stile di visualizzazione m \ volte n) matrice come vettore di dimensione m n (\ stile di visualizzazione mn) e usa le norme vettoriali standard:
‖ A ‖ p = ‖ vec (A) ‖ p = (∑ i = 1 m ∑ j = 1 n | aij | p) 1 / p (\ displaystyle \ | A \ | _ (p) = \ | \ mathrm ( vec) (A) \ | _ (p) = \ left (\ sum _ (i = 1) ^ (m) \ sum _ (j = 1) ^ (n) | a_ (ij) | ^ (p) \ a destra) ^ (1 / p))Norma di Frobenius
Norma di Frobenius, o norma euclideaè un caso speciale della norma p per P = 2 : ‖ A ‖ F = ∑ i = 1 m ∑ j = 1 naij 2 (\ displaystyle \ | A \ | _ (F) = (\ sqrt (\ sum _ (i = 1) ^ (m) \ sum _ (j = 1) ^ (n) a_ (ij) ^ (2)))).
La norma di Frobenius è facile da calcolare (rispetto, ad esempio, alla norma spettrale). Possiede le seguenti proprietà:
‖ A x ‖ 2 2 = ∑ i = 1 m | ∑ j = 1 n a io j x j | 2 ≤ ∑ i = 1 m (∑ j = 1 n | a i j | 2 ∑ j = 1 n | x j | 2) = ∑ j = 1 n | x j | 2 ‖ A ‖ F 2 = ‖ A ‖ F 2 ‖ x ‖ 2 2. (\ displaystyle \ | Ax \ | _ (2) ^ (2) = \ sum _ (i = 1) ^ (m) \ left | \ sum _ (j = 1) ^ (n) a_ (ij) x_ ( j) \ destra | ^ (2) \ leq \ somma _ (i = 1) ^ (m) \ sinistra (\ somma _ (j = 1) ^ (n) | a_ (ij) | ^ (2) \ somma _ (j = 1) ^ (n) | x_ (j) | ^ (2) \ destra) = \ somma _ (j = 1) ^ (n) | x_ (j) | ^ (2) \ | A \ | _ (F) ^ (2) = \ | A \ | _ (F) ^ (2) \ | x \ | _ (2) ^ (2).)- submoltiplicatività: ‖ A B ‖ F ≤ ‖ A ‖ F ‖ B ‖ F (\ displaystyle \ | AB \ | _ (F) \ leq \ | A \ | _ (F) \ | B \ | _ (F)), perché ‖ A B ‖ F 2 = ∑ i, j | k a io k b k j | 2 ≤ ∑ i, j (∑ k | a i k | | b k j |) 2 ≤ ∑ i, j (∑ k | a i k | 2 ∑ k | b k j | 2) = ∑ i, k | a io k | 2 ∑ k, j | b k j | 2 = ‖ A ‖ F 2 ‖ B ‖ F 2 (\ displaystyle \ | AB \ | _ (F) ^ (2) = \ sum _ (i, j) \ left | \ sum _ (k) a_ (ik) b_ (kj) \ destra | ^ (2) \ leq \ sum _ (i, j) \ sinistra (\ sum _ (k) | a_ (ik) || b_ (kj) | \ destra) ^ (2) \ leq \ sum _ (i, j) \ left (\ sum _ (k) | a_ (ik) | ^ (2) \ sum _ (k) | b_ (kj) | ^ (2) \ right) = \ sum _ (i, k) | a_ (ik) | ^ (2) \ sum _ (k, j) | b_ (kj) | ^ (2) = \ | A \ | _ (F) ^ (2) \ | B \ | _ (F) ^ (2)).
- ‖ A ‖ F 2 = tr A ∗ A = tr AA ∗ (\ displaystyle \ | A \ | _ (F) ^ (2) = \ mathop (\ rm (tr)) A ^ (*) A = \ mathop (\ rm (tr)) AA ^ (*)), dove t r A (\ displaystyle \ mathop (\ rm (tr)) A)- traccia matrice A (\ stile di visualizzazione A), A ∗ (\ stile di visualizzazione A ^ (*))è una matrice coniugata hermitiana.
- ‖ A ‖ F 2 = ρ 1 2 + ρ 2 2 + ⋯ + ρ n 2 (\ displaystyle \ | A \ | _ (F) ^ (2) = \ rho _ (1) ^ (2) + \ rho _ (2) ^ (2) + \ punti + \ rho _ (n) ^ (2)), dove 1, ρ 2,…, ρ n (\ displaystyle \ rho _ (1), \ rho _ (2), \ punti, \ rho _ (n))- valori singolari della matrice A (\ stile di visualizzazione A).
- ‖ A ‖ F (\ stile di visualizzazione \ | A \ | _ (F)) non cambia con la moltiplicazione tra matrici A (\ stile di visualizzazione A) sinistra o destra in matrici ortogonali (unitarie).
Modulo massimo
La norma modulo massimo è un altro caso speciale della norma p per P = ∞ .
‖ A ‖ max = max (| a i j |). (\ displaystyle \ | A \ | _ (\ text (max)) = \ max \ (| a_ (ij) | \).)La norma di Schatten
Consistenza delle norme matriciali e vettoriali
Norma matrice ‖ ⋅ ‖ a b (\ displaystyle \ | \ cdot \ | _ (ab)) Su K m × n (\ stile di visualizzazione K ^ (m \ volte n)) chiamato concordato con le norme ‖ ⋅ ‖ a (\ displaystyle \ | \ cdot \ | _ (a)) Su K n (\ stile di visualizzazione K ^ (n)) e ‖ ⋅ ‖ b (\ displaystyle \ | \ cdot \ | _ (b)) Su K m (\ stile di visualizzazione K ^ (m)), Se:
‖ A x ‖ b ≤ ‖ A ‖ a b ‖ x ‖ a (\ displaystyle \ | Ax \ | _ (b) \ leq \ | A \ | _ (ab) \ | x \ | _ (a))per ogni A ∈ K m × n, x ∈ K n (\ stile di visualizzazione A \ in K ^ (m \ volte n), x \ in K ^ (n))... La norma dell'operatore per costruzione è coerente con la norma del vettore originale.
Esempi di norme matrice concordate, ma non subordinate:
Equivalenza delle norme
Tutte le norme nello spazio K m × n (\ stile di visualizzazione K ^ (m \ volte n)) sono equivalenti, cioè per due norme qualsiasi . ‖ Α (\ stile di visualizzazione \ |. \ | _ (\ Alfa)) e . ‖ Β (\ stile di visualizzazione \ |. \ | _ (\ Beta)) e per qualsiasi matrice A ∈ K m × n (\ stile di visualizzazione A \ in K ^ (m \ volte n)) la doppia disuguaglianza è vera.
Matrice norma chiameremo il numero reale assegnato a questa matrice || A || tale che, come numero reale, è associato a ciascuna matrice dallo spazio n-dimensionale e soddisfa 4 assiomi:
1. || A || ³0 e || A || = 0 solo se A è una matrice zero;
2. || αA || = | α | · || A ||, dove a R;
3. || A + B || £ || A || + || B ||;
4. || A · B || £ || A || · || B ||. (proprietà moltiplicativa)
La norma delle matrici può essere inserita in vari modi. La matrice A può essere vista come n 2 - vettore dimensionale.
Questa norma è detta norma euclidea della matrice.
Se per qualsiasi matrice quadrata A e qualsiasi vettore x, la cui dimensione è uguale all'ordine della matrice, la disuguaglianza || Ax || £ || A || · || x ||
allora si dice che la norma della matrice A è coerente con la norma del vettore. Nota che a sinistra dell'ultima condizione c'è la norma del vettore (Ax è un vettore).
Varie norme di matrice sono coordinate con la norma di vettore data. Scegliamo il più piccolo tra loro. Questo sarà
Questa norma matrice è subordinata a una data norma vettoriale. L'esistenza di un massimo in questa espressione segue dalla continuità della norma, poiché esiste sempre un vettore x -> || x || = 1 e || Ax || = || A ||.
Dimostriamo che la norma N (A) non è soggetta ad alcuna norma vettoriale. Le norme della matrice, fatte salve le norme vettoriali precedentemente introdotte, sono espresse come segue:
1. || A || ¥ = | a ij | (norma-massimo)
2. || A || 1 = | a ij | (somma normale)
3. || A || 2 =, (norma spettrale)
dove s 1 è il più grande valore proprio della matrice simmetrica A ¢ A, che è il prodotto delle matrici trasposte e originarie. T k la matrice A ¢ A è simmetrica, quindi tutti i suoi autovalori sono reali e positivi. Il numero di l -proprietà è il valore, e il vettore diverso da zero x è l'autovettore della matrice A (se sono legati dalla relazione Ax = lx). Se la matrice A stessa è simmetrica, A ¢ = A, quindi A ¢ A = A 2 e quindi s 1 =, dove è l'autovalore modulo più grande della matrice A. Quindi, in questo caso abbiamo =.
Gli autovalori della matrice non superano nessuna delle sue norme concordate. Normalizzando la relazione che definisce gli autovalori, si ottiene || λx || = || Ax ||, | λ | · || x || = || Ax || £ || A || · || x ||, | λ | £ || A ||
Poiché è vero || A || 2 £ || A || e, dove la norma euclidea è facile da calcolare, nelle stime, invece della norma spettrale, si può usare la norma euclidea della matrice.
30. Condizionalità dei sistemi di equazioni. Fattore di condizionalità .
Condizionalità- l'influenza della decisione sui dati iniziali. Ax = b: vettore B soluzione di corrispondenza X... lascia stare B cambierà dell'importo. Allora il vettore b + la nuova soluzione corrisponderà x + : A (x + ) = b +... Poiché il sistema è lineare, allora Ascia + LA = b +, poi UN = ; = ; = ; b = Ax; = allora; *, dove è l'errore relativo della perturbazione della soluzione, - fattore di condizionecond (A) (quante volte l'errore di soluzione può aumentare), è la perturbazione relativa del vettore B. cond (A) = ; cond (A) * Proprietà del coefficiente: dipende dalla scelta della norma della matrice; cond ( = cond (A); la moltiplicazione di una matrice per un numero non influisce sul fattore di condizione. Maggiore è il coefficiente, più l'errore nei dati iniziali influisce sulla soluzione dello SLAE. Il numero della condizione non può essere inferiore a 1.
31. Il metodo sweep per la risoluzione di sistemi di equazioni algebriche lineari.
Spesso è necessario risolvere sistemi le cui matrici, essendo debolmente riempite, es. contenente molti elementi diversi da zero. Le matrici di tali sistemi hanno solitamente una certa struttura, tra cui ci sono sistemi con matrici di una struttura a strisce, ad es. in essi, gli elementi diversi da zero si trovano sulla diagonale principale e su più diagonali laterali. Per la risoluzione di sistemi con matrici a strisce, il metodo gaussiano può essere trasformato in metodi più efficienti. Consideriamo il caso più semplice di sistemi a bande, a cui, come vedremo in seguito, la soluzione di problemi di discretizzazione per problemi al contorno per equazioni differenziali con i metodi delle differenze finite, degli elementi finiti, ecc. adiacenti ad essa:
Tre matrici diagonali hanno solo (3n-2) elementi diversi da zero.
Rinominiamo i coefficienti della matrice:
Quindi, nella notazione dei componenti, il sistema può essere rappresentato come:
A io * x i-1 + b io * x io + c io * x io + 1 = d i , io = 1, 2, ..., n; (7)
a1 = 0, cn = 0. (otto)
La struttura del sistema assume una relazione solo tra incognite vicine:
x io = x io * x io +1 + h io (9)
x i -1 = x i -1 * x i + h i -1 e sostituire in (7):
A i (x i-1 * x i + h i-1) + b i * x i + c i * x i + 1 = d i
(a io * x i-1 + b i) x io = –c io * x io + 1 + d io –a io * h i-1
Confrontando l'espressione risultante con la rappresentazione (7), otteniamo:
Le formule (10) rappresentano le relazioni di ricorrenza per il calcolo dei coefficienti di scansione. Richiedono l'impostazione dei valori iniziali. In accordo con la prima condizione (8) per i = 1 si ha a 1 = 0, e quindi
Inoltre, i restanti coefficienti di scansione vengono calcolati e memorizzati secondo le formule (10) per i = 2,3, ..., n, e per i = n, tenendo conto della seconda condizione (8), otteniamo xn = 0 . Pertanto, secondo la formula (9) x n = h n.
Successivamente, secondo la formula (9), le incognite x n -1, x n -2, ..., x 1 vengono trovate in sequenza. Questa fase del calcolo è chiamata corsa inversa, mentre il calcolo dei fattori di scansione è chiamato scansione in avanti.
Per la corretta applicazione del metodo sweep, è necessario che nel processo di calcolo non ci siano situazioni con divisione per zero e con una grande dimensione dei sistemi non ci sia un rapido aumento degli errori di arrotondamento. Chiameremo la corsa corretta se il denominatore dei coefficienti di sweep (10) non si annulla, e sostenibile se ½x i ½<1 при всех i=1,2,…, n. Достаточные условия корректности и устойчивости прогонки, которые во многих приложениях выполняются, определяются теоремой.
Teorema. Lascia che i coefficienti a i e ci dell'equazione (7) per i = 2,3, ..., n-1 differiscano da zero e sia
½b i ½> ½a i ½ + ½c i ½ per i = 1, 2, ..., n. (undici)
Allora lo sweep definito dalle formule (10), (9) è corretto e stabile.