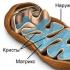
실험 연구 디자인. 심리학 연구 디자인
실험 심리학 그것은 기초입니다 실용적인 응용 프로그램 연구 중에 대조군 그룹이 적용될 때, 샘플이 실험실 조건에있는 이른바 진정한 실험의 계획. 이러한 종류의 실험 방식은 계획 4, 5 및 6으로 지정됩니다.
예비 및 최종 테스트 및 제어 그룹을 계획하십시오 (계획 4). Scheme 4는 심리적 실험실 연구의 고전적인 "디자인"입니다. 그러나 필드에 적용 가능합니다. 그 특징은 대조군의 존재 하에서뿐만 아니라 추가적인 계획 3, 즉 실험 및 제어 샘플의 동등성 (균질성)에 이미 있습니다. Scheme 4에 따라 지어진 실험의 정확성의 중요한 요소는 두 가지 상황이기도합니다. 샘플이 위치한 연구 조건의 균질성이 있으며 실험의 내부 유효성에 영향을 미치는 요인의 완전한 제어입니다.
예비 및 최종 테스트 및 대조군과의 실험 계획을 선택하는 것은 연구의 실험 과목 및 조건에 따라 이루어집니다. 적어도 두 개의 균질 그룹을 형성 할 수 있으면 다음 실험 방식이 적용됩니다.
예. 실험 계획 4를 구현할 수있는 가능성의 실제 동화를 위해, 우리는 가설의 확인 기전이 긍정적 인 동기 부여가 인간의 농도에 영향을 미치는 가설의 확인 메커니즘이있는 실험실 형성 실험의 형태로 실제 연구의 예를 제공합니다. 주의.
가설: 과목의 동기 부여는 교육 및인지 활동에 직면하여 사람들의 관심의 집중력과 지속 가능성을 증가시키는 데 중요한 요소입니다.
실험적 절차:
- 1. 실험 및 제어 샘플의 형성. 실험 참가자는 사전 테스트 지표 또는 변수에 따라 신중하게 균등 한 쌍으로 나뉘며 서로 상관 관계가 있습니다. 그런 다음 Draw 방법에 의한 각 나라 "무작위로"(무작위 화)의 구성원이 실험 또는 제어 그룹에 포함됩니다.
- 2. 두 그룹 모두 "링이있는 샘플 수정"(O 및 0 3) 테스트를 해결하도록 초대됩니다.
- 3. 실험 샘플의 활동이 자극됩니다. 테스트에 실험 자극 단위 (X)가 주어진다고 가정 해 봅시다 : "관심의 집중력과 지속 가능성 시험에 붕괴 된 학생들은 이번 학기에서 시험을 받는다." "기계"에서 시험을 받는다.
- 4. 두 그룹 모두 테스트 "Sluts가있는 표지판 수정"(0 2 및 OD)
실험 결과를 분석하기위한 알고리즘
- 5. 경험적 데이터는 분포 1의 정상적으로 "정상적으로"검사됩니다. 이 작업을 수행하면 적어도 두 가지 상황을 알 수 있습니다. 첫째, 피험자의 안정성과 농도를 결정하는 데 사용되는 테스트로서 측정 된 속성에 대해 차별 (차별화)을 차별합니다. 이 경우 정규 분포는 표지판의 지표가 적용된 테스트의 개발 상황과 최적의 관계에 해당 함을 보여줍니다. 이 기술은 의도 된 영역에 의해 최적으로 측정됩니다. 이 조건에서 사용하기에 적합합니다. 둘째, 경험적 데이터의 분포의 정상은 파라 메트릭 통계의 방법을 올바르게 적용 할 권리를 부여합니다. 통계는 데이터 배포를 평가하는 데 사용할 수 있습니다 같이. 과 e h. 또는 와이
- 6. 그것은 중간 날개에 의해 계산됩니다 m x. 예비 및 최종 테스트 결과의 표준 5 L. 편차.
- 7. 시험 지표의 평균값 비교 실험 및 제어 그룹 (O, 0 3; 오, od.
- 8. 평균 가치의 비교가 있지만 학생의 ^ -criterid, 즉. 평균 값의 차이의 통계적 중요성을 결정합니다.
- 9. 실험의 효과의 지표로서 관계의 증거가 수행됩니다.
- 10. 실험적인 유효성은 비 신뢰성 요인의 제어 정도를 결정함으로써 검사된다.
주제를 집중시키는 과정에서 동기 부여 변수의 효과에 대한 심리적 실험을 설명하기 위해 표에있는 데이터를 참조하십시오. 5.1.
실험 결과 테이블, 포인트
표 5.1
끝 테이블. 5.1
|
테스트 |
노출 측정 엑스. |
노출 후 측정 엑스. |
|||
|
실험 |
제어 그룹 |
실험 |
제어 그룹 0 3 |
실험 그룹 0 2. |
제어 그룹 0 4 |
실험 및 제어 샘플의 기본 측정 데이터 비교 - 오! 및 실험 및 제어 샘플의 동등성을 결정하기 위해 O3 - 생산됩니다. 이 표시기의 신원은 그룹의 동질성 (동등성)을 나타냅니다. 신뢰 구간에서 평균의 차이의 통계적 중요성의 수준을 계산하여 결정됩니다. 아르 자형 셰이크에 대한 T- 기준.
우리의 경우 실험 및 대조군 그룹의 1 차 조사의 경험적 데이터 사이의 쉐이드 니륨의 가치 / -Criterion은 0.56이었다. 이는 샘플이 자신감 간격이 크게 다르지 않음을 나타냅니다 /?
실험 샘플의 1 차 및 재 측정 데이터의 비교 - OJ 및 0 2는 실험 샘플에 대한 독립 변수의 영향 이후에 종속 변수의 변화 정도를 결정하기 위해 만들어졌습니다. 이 절차는 하나의 테스트 스케일 또는 표준화 된 변수가 측정 된 경우, Sodeteit의 / -criteria를 사용하여 수행됩니다.
고려중인 경우, 예비 (1 차) 및 최종 설문 조사는 관심의 농도를 측정하는 상이한 시험을 사용하여 수행되었다. 따라서 표준화가없는 평균 지표의 비교가 실용적이지 못합니다. 실험 그룹의 기본 연구 지표 사이의 상관 계수를 계산하십시오. 낮은 가치는 데이터가 변경되었음을 간접적으로 증명할 수 있습니다. (r xy \u003d 0D6).
실험 효과는 실험 및 제어 샘플의 반복 측정 데이터를 비교하여 결정됩니다 - 0 2 및 0 4. 독립 변수의 영향을받은 후 종속 변수를 변경하는 중요성을 확인하기 위해 생성됩니다. (엑스) 실험 샘플에서. 이 연구의 심리적 의미는 영향을 평가하는 것입니다. 엑스. 과목에. 이 경우이 실험 및 제어 그룹의 최종 측정 단계에서 비교가 이루어집니다. 영향 분석 엑스. 그것은 / -criteria의 / -criteria와 함께 수행됩니다. 그 값은 2.85이며, 더 많은 표 형식 / -Criteria 1입니다. 이것은 실험 및 제어 그룹의 평균 테스트 값간에 통계적으로 유의 한 차이가 있음을 보여줍니다.
따라서, 계획 4에 따른 실험의 결과로서, 설치 심리적 특성 (주목의 농도의 관점에서)의 설치 심리적 특성상의 다른 그룹과는 다른 제 1 그룹이 아닌 것으로 나타났다. 독립 변수에 영향을 미칩니다 엑스 관심 집중의 지표의 가치는 동일한 조건하에있는 두 번째 그룹의 동일한 지표와 통계적으로 상당히 다르지만 영향을 미치지 않습니다. 엑스.
실험의 타당성에 대한 연구를 고려하십시오.
배경: 실험적 영향과 평행 한 이벤트가 실험적 영향과 평행 한 이벤트가 관찰되어 있기 때문에 모니터링됩니다.
자연 개발 : 테스트 및 노출 기간 간의 작은 기간 동안 제어되고 실험 및 제어 그룹 모두에서 일어난다.
테스트 효과 및 도구 오류 : 실험 및 제어 그룹에서 동등하게 나타나기 때문에 통제됩니다. 우리의 경우 샘플 변위가 관찰됩니다.
통계 회귀 : 통제. 첫째, 무작위 화가 실험 그룹에서 극단적 인 결과를 초래하면 회귀의 효과가 동일하게 될 것입니다. 둘째로, NA의 무작위 화가 샘플에서 극단적 인 결과가 발생하면이 질문은 그 자체로 제거됩니다.
테스트 선택 : 차이점에 대한 설명은 무작위 화가 샘플의 동등성을 보장하는 범위로 제외됩니다. 이 정도는 우리가 채택한 선택 통계에 의해 결정됩니다.
열리는: 두 샘플에서 테스트 사이의 기간은 상대적으로 작뿐만 아니라 피사체의 PA 경험의 존재에 대한 필요성이 부족합니다. 노출 시간 (시험 간의 기간)을 가진 실험에서 샘플과 실험 결과의 효과를 대체 할 수 있습니다. 이 상황의 출력은 테스트 실험 그룹이 실험적 영향을받지 못한 경우에도 샘플 모두의 예비 및 최종 테스트 결과를 처리 할 때의 결과를 처리 할 때 설명합니다. 효과 엑스 분명히, 그것은 느슨하게 될 것이지만 샘플 변위는 일어나지 않을 것입니다. 두 번째 출력은 최종 테스트 전에 무작위 화 된 그룹의 동등성을 달성해야하기 때문에 실험 계획의 변화를 수반합니다.

선택 요소의 상호 작용으로 자연스러운 개발 : 컨트롤 등가 그룹의 형성에 의해 제어됩니다.
반응 효과 : 사전 테스트는 인식에 대한 실험적 영향을 실제로 구성합니다. 따라서 노출의 효과가 "변화"합니다. 이 상황에서는 실험 결과가 전체 인구로 확장 될 수 있음을 절대적으로 주장 할 수는 없습니다. 반응 효과의 제어는 반복적 인 설문 조사가 전체 집단의 특징 인 정도까지 가능합니다.
선택 요소와 실험적 영향의 상호 작용: 실험에 참여하는 자발적인 동의 상황에서 유효성 ( "변위")의 위협은 본 계약이 사람들에게 특정 성격 창고를 제공한다는 사실을 고려하여 발생합니다. 임의의 순서로 동등한 샘플의 형성은 결합을 감소시킨다.
실험 시험 된 반응: 실험의 상황은 피험자가 "특별한"조건에 빠지기 때문에이 작업의 의미를 이해하려고합니다. 여기에서, 시위, 게임, 캐비티, 추측을위한 설치 등의 징후. 실험에 대한 반응은 예를 들어 시험의 내용, 무작위 화의 과정, 개인 그룹으로의 참가자의 분리, 다른 건물의 피험자의 내용, 익숙하지 않은 사람들의 존재, 특별한 사용 엑스. 기타
이 어려움의 출력은 연구의 "마스킹"이며, 즉. 실험 절차의 전설의 전설 또는 일반적인 사건 과정에서의 포괄적 인 시스템의 시스템을 묘사하고 명확하게 준수하십시오. 이를 위해 정기적 인 테스트 활동의 지식에 따라 가장 합리적인 테스트와 실험적 영향이 가장 큽니다. 그룹의 개별 구성원조차도 연구에서 전체적으로 집단의 실험에 참여하는 것이 바람직합니다. 풀 타임 리더, 교사, 자산, 관찰자 \u200b\u200b등의 힘을 수행하기 위해 테스트 및 실험적 영향을 실시하는 것이 적절합니다.
결론적으로 D. Campbell이 지적했듯이 실험의 효과를 결정하는 최적의 방법은 여전히 \u200b\u200b" 상식"및"비상화 성격의 고려 사항 ".
4 개의 그룹 (5)의 R. 솔로몬을 계획하십시오 (계획 5). 특정 연구 조건을 통해 4 개의 동등한 샘플의 형성을 허용하면서 실험은 컴파일러의 이름으로 명명 된 Scheme 5에 따라 작성됩니다.

솔로몬의 계획은 예비 측정을받지 않은 그룹의 두 가지 추가 (계획 4)를 끌어들이면서 실험의 외부 유효성을 위협하는 요인을 보상하려는 시도입니다.
추가 그룹의 데이터 비교는 테스트의 영향과 실험 자체의 영향을 중화시키고 결과를 더 잘 설정할 수있게합니다. 실험적 영향의 효과의 식별은 다음과 같은 불평등의 통계적 증거에 의해 재현됩니다. 0 2\u003e OJ; 0 2\u003e 0 4; 0 5\u003e b. 세 가지 비율이 모두 수행되면 실험 출력의 적법성 많은 증가합니다.
계획 5의 적용은 시험 결과의 해석을 용이하게하는 테스트 및 실험적 영향의 상호 작용을 중화 할 가능성을 결정합니다. B C O의 비교, 0 3은 자연 발달 및 배경의 결합 된 효과를 확인할 수 있습니다. 평균 0 2와 0 5, 0 4 및 0의 비교는 사전 테스트의 주요 효과를 추정 할 수있게합니다. medium () 2 및 0 4, 0 5 및 0 g의 비교)은 실험적 영향의 주요 효과를 추정 할 수 있습니다.
사전 테스트의 효과와 상호 작용의 효과가 작고 소홀히 할 수있는 경우, 유일한 변수로서 사전 테스트 결과를 사용하여 공분식 분석 0 4 및 0 2를 수행하는 것이 바람직합니다.
노출 후에 만 \u200b\u200b제어 그룹과 테스트를 계획하십시오 (계획 6).매우 자주, 연구자들은 독립적 인 변수의 영향 이후 연구가 수행되기 때문에 피험자의 심리적 매개 변수의 예비 측정을 수행 할 수없는 조건에서 심리적 변수를 연구 할 필요가있는 상황에 직면 해 있습니다. 이벤트가 이미 발생했을 때 그 결과를 식별 할 필요가 있습니다. 이 상황에서는 실험의 최적의 계획은 노출 후에 만 \u200b\u200b대조군과 테스트를하는 계획입니다. 최적의 선택적 동등성을 제공하는 무작위 화 또는 다른 절차를 사용하여 균일 한 실험 및 테스트 그룹이 형성됩니다. 테스트 변수는 실험적 영향을받은 후에 만 \u200b\u200b수행됩니다.

예.1993 년 방사선학의 순서로 방사선 노출의 방사선 노출의 영향이 수행되었습니다. 실험은 계획 6에 따라 지어졌습니다. 사고의 결과의 51 청산인의 심리 검사 체르노빌 원자력 발전소 배터리로 심리적 테스트 (개인 설문지, 산 (웰빙 활동, 분위기), 루캐 테스트 등), EAF ON R. Fall (R. voll) 및 자동화 된 상황 진단 게임 (ASID) "테스트". Control Sample은 체르노빌의 방사선 학적 사건에 참여하지 않은 47 개의 전문가입니다. 시험 실험 및 통제 그룹의 평균 연령은 33 년으로 달했다. 다음 샘플은 경험, 활동의 성질 및 사회화의 구조에 의해 최적으로 상관 관계가 있으므로 형성된 그룹은 동등한 것으로 인식되었다.
우리는 실험 및 유효성에 의해 건설 될 계획의 이론적 분석을 생산할 것입니다.
배경다음과 같은 조절 샘플이 연구에서 사용되었으므로 제어됩니다.
자연 개발: 피험자의 사회화 과정에 실험 자들을 개입하지 않았기 때문에 실험적 영향의 한 요소로 모니터링되었습니다.
테스트 효과: NA는 주제를 사전 검사했기 때문에 통제됩니다.
기악 오류: 신뢰성의 예비 검증이 수행 되었기 때문에 통제 되었기 때문에 방법 론적 수단 실험 후에 규제 지표를 명확히하고, 제어 및 실험 그룹에 동일한 유형의 "테스트 배터리"의 사용을 분명히합니다.
통계 회귀 : 그는 무작위 순서로 형성된 전체 샘플에서 실험 물질을 테스트하여 통제되었습니다. 그러나 NA가 실험 단체의 구성에 대한 예비 데이터 였기 때문에 NA가 예비 자료 였기 때문에 유효성의 위협이있었습니다. 외관과 극좌표 변수의 확률.
주제 선택 ", 자연 무작위 화 때문에 완전히 통제되지 않았습니다. 특별한 피험자의 선택이 수행되지 않았습니다. 사고를 제거하는 참가자들로부터의 무작위 순서로 체르노빌 NPPS와 화학자 전문가들은 그룹을 형성했다.
테스트 과목 실험 중에는 그렇지 않았습니다.
선택 요소의 자연 개발과의 상호 작용 ", 특별한 NA 선택이 수행되었습니다. 이 변수가 모니터되었습니다.
그룹 및 실험적 영향 조성의 상호 작용 ", 특별한 피험자의 선택이 수행되지 않았습니다. 연구 그룹 (실험적 또는 대조군)이 포함 된 것에 대해 알리지 않았습니다.
실험을위한 반응 피사체 ", 이 실험에서 통제 할 수없는 요소.
실험적 영향의 상호 간섭 (부과) : 피험자가 그러한 실험에 참여했는지 여부와 결과에 어떻게 반영되었는지 여부가 알려지지 않았기 때문에 통제되지 않았습니다. 심리적 테스트...에 실험자를 관찰함으로써 일반적으로 실험에 대한 태도는 부정적이었습니다. 이 상황은이 실험의 외부 타당성에 긍정적 인 영향을 미치지 않을 것입니다.
실험 결과
- 1. 정상 분포의 이론적 곡선에 가까운 종 모양의 외관을 가진 경험적 자료의 분포에 대한 연구.
- 2. ^ - 학생의 기준을 통해 평균 OJ\u003e 0 2의 비교가 이루어졌습니다. adid "test"및 eaf, 실험 및 대조군 그룹은 감정적 인 상태 (위의 유출 제)의 역학,인지 활동의 효과, 추진력, 간에서의 기능뿐만 아니라, , 만성 내인성 중독으로 인해 신장 등.
- 3. ^ -criteria fischer의 도움으로 "진동"의 효과 (독립 변수의 분산) 엑스. 종속 변수 0 2의 분산에.
본 연구의 출력으로서, 실험 참가자들과 그들의 지도자들의 참가자들에게 관련된 권고가 이루어졌으며, 심리적 검사의 진단 배터리가 수행되었고 극한 방사선 조건에서 사람들에게 영향을 미치는 정신적 생리적 요인이 밝혀졌다.
따라서 실험적인 "디자인"6은 심리적 변수의 예비 측정을 할 수 없을 때 심리적 연구의 최적 연구 계획입니다.
위에서부터 심리학의 실험 방법의 기초는 내부 타당성에 영향을 미치는 거의 모든 주요 요인이 수행되는 소위 전형적인 계획이라는 것을 추적합니다. 계획된 실험 결과의 정확성은 계획되었지만 Schemes 4-6은 대다수의 연구원의 의심을 일으키지 않습니다. 다른 모든 심리 연구에서와 마찬가지로 주요 문제는 과목의 실험 및 통제 샘플, 연구 조직, 적절한 측정제의 수색 및 사용법입니다.
- 이 기관의 R 심볼은 그룹의 균질성이 랜덤 화에 의해 얻어지는 것을 의미한다.이 심볼은 제어 및 실험 재량의 균일 성이 다른 방식으로 제공 될 수 있기 때문에 (예를 들어, 쌍 선택, 사전 테스트 등) .). 상관 계수 (0.16)의 값은 측정치와 약한 통계적으로 통신을 밝힙니다. I.E. 데이터가 몇 가지 변화가 있음을 가정 할 수 있습니다. 노출 후의 요인은 노출 전에 지표와 일치하지 않습니다. EAF - 가을 방식 (Elektroakupunktur Nach Voll, EAV) - 피부의 전기 저항을 측정하여 대안 (비 전통적) 의학에서 전자 주목할만한 표현 진단 방법. 이 방법은 1958 년 독일 Dr. Reynold Follem에서 본질적으로 개발되었으며, 침술과 마르 갈바 노 미터의 적용의 조합입니다.
- 군사 인력의 심리적 지위 평가 - 역동적 인 상황 게임 "Test"/ I. V. Zakharov, O. Govorukha의 Zakharov, O. S. Govorukha, O. Zakharov, ii. [및 기타] / / 군사 의료 저널을 소유합니다. 1994. 제 7 항. 42-44.
- 연구 V. II. ignatkin.
의료 사망 인증서는 민사 지위 행위 기록 기록의 국가 등록의 국가 등록을위한 인간의 사망을 인증하는 중요한 의학 문서이며 사망 원인의 통계의 기초입니다.
연방법에 따라 "시민권의 행위"15.11.97. 143-FZ 사람의 죽음의 등록은 "의료진 사망 증명서"의 설립 된 형태의 문서를 기반으로 한 것입니다. 죽은 자녀가 태어난 어린이의 등록이 아니면 생명의 첫 주에 사망했지만, "주요 죽음의 의학적 인증서"문서를 바탕으로 만들어졌습니다. 이 문서는 의료 기관이나 사적인 의사가 발행합니다.
1998 년에는 사망 의료증 (회계 형식 106 / U-98)과 주목 사망 의료 증명서 (회계 형식 106 / U-98)의 이전 개정판이 1998 년에 수행되었다. 이러한 형태 (설립 된 샘플)는 러시아 보건부의 주문의 순서에 의해 승인되었다 07.08.98. № 241.
국제 실천에서 사망 증명서는 약 10 년 만에 개정됩니다. 수정의 목적은 국내 및 외국 건강의 업적을 고려하여 변경된 조건에 양식을 적응시키는 것입니다.
지난 10 년 동안 특정 경험이 적용 가능한 사망과 주목 사망 인증서로 축적되었습니다.
우리 연구의 목적은 사망률 통계의 신뢰성과 국제적 비교 가능성을 증가시키기위한 제안을 개발하는 것이 었습니다.
연구 작업 :
- 사망률에 대한 통계 데이터를 수집하고 처리하는 기존 시스템을 검사하고 의료 인증서의 표준의 적용을위한 기존 시스템을 검사하십시오.
- 임시 사망의 의료 증명서와 공사 사망의 의료 증명서 및 전문가 평가에 기초하여 연구 된 영토에서 얻은 사망률 통계 자료의 정확성을 결정하기위한 전문가 평가를 분석합니다.
- 사망 회계 문서를 개선하기위한 제안을 개발하십시오.
- 사망 원인의 신뢰성을 달성하는 방법 론적 기반의 교육 전문가를위한 시스템을 개발하십시오.
- MKB-10 (Rutendon "을 사용하기위한 방법 론적 소프트웨어 패키지를 개발하고 구현하십시오.
- 초기 사망 원인을 자동화하고 인코딩하는 복잡한 "사망률 모니터링"프로그램을 개발하십시오.
재료, 방법 및 데이터베이스.
우리는 Tula, 블라디미르, 쿠르 간, 튜멘 지역, Stavropol 및 Krasnoyarsk Territories 및 Buryatia 공화국에서 2000 년부터 2000 년부터 2000 년부터 2000 년부터 120715 년 의료 증명서와 1093 개의 의료 증명서를 분석했습니다.
이 연구는 견고하고 선택적인 방법, 전문가 평가 및 "불임 및 사망률 모니터링"프로그램의 패키지를 사용했습니다.
사용 된 자료, 데이터베이스 및 메소드가 작업을 해결할 수 있습니다.
연구의 결과로 러시아의 회계, 가공 및보고 정보 시스템은 주로 누가 권고 사항을 준수하도록 설립되었습니다. 동시에, 주 사망률 통계에서 국제 정의에서 벗어난 편차가 있습니다.
증거 자체에 대한 충전 인증서의 질을 분석하고, 증거 자체의 단점, 작성, 코딩 및 사망의 초기 원인을 선택하는 오류가 발생했습니다.
의학적 인증서에서, 중복 된 품목 (P.14, 15 및 18)이 밝혀졌으며, 이는 부상과 중독에서 증거를 완성 할 때 오류와 발산을 이끌어 냈습니다. 뿌리와 제 18 항의 제 8 항에서는 과도한 서브 린티어의 "죽음의 원인"증언, 즉 I.E. 정보가 세 줄 모두에게 충분한 경우에만 정확합니다. 하나 또는 두 줄에 정보가있는 경우 인증서를 완료하는 규칙은 위반됩니다. 세 번째 줄은 첫 번째와 두 번째로 공백으로 채워집니다.
사망자 등록의 단일, 단일,하지만 설치. 예를 들어, Tula 지역에서는 Stavropol Perritory 에서이 위반이 0.4 %로 금액이었습니다.
전문가 검토 의료진 증명서를 채우면 모든 인증서의 모든 점이 주로 채워진 것으로 나타났습니다. 동시에 제 12 항, "교육"은 사례의 36.1 %만으로 36.1 %만으로 채워진다 "- 50 %의 경우 50 %의 경우, 다른 경우 정보는 알려지지 않았습니다. 동시에이 정보는 매우 중요합니다. 죽은 자의 사회적 지위를 설명하고 사망 분석에 널리 사용됩니다.
오류는 제 18 항의 "죽음의 원인"을 작성할 때, 다른 영토에서 23.6에서 47.4 %까지, 사망의 초기 원인을 5.9 ~ 15.4 %에서 5.9 ~ 15.4 %로 선택하고 : 27.9에서 52까지, 아홉%.
따라서 문제는 일반적으로 사망률에 관한 정보의 정확성이 주제에 관한 것입니다. 러시아 연방 그것은 약 50 %입니다.
이러한 오류는 연구중인 지역의 총 사망 원인의 실제 구조를 왜곡시키고 의료 인구 통계 학적 프로세스에 대한 잘못된 아이디어를 제공합니다.
심각한 단점과 사망의 이유의 왜곡은 사망과 주목 사망의 의료 증명서를 작성하는 전문가를 훈련시키는 균일 한 방법이 부족하기 때문입니다.
사망 의료 증명서를 작성하고 발행하는 절차에 대한 지침의 부족은 그 품질을 크게 감소시킵니다.
연구의 업무를 1999 년부터 2006 년부터 2006 년까지 다음 작품이 수행되었다.
- iCD-10의 사용에 대한 106 개의 세미나가 개최되었으며, 6977 명의 청취자의 적용 범위에 대한 의학적 인증서 및 인코딩을 채우는 규칙;
- mKB-10 "Rutendon"을 사용하기위한 프로그램의 방법 론적 패키지는 87 개 물체 (러시아 연방의 주제, 동유럽 국가에서 61 명)에서 87 개 물체 (30 개)에서 개발되고 구현되었습니다.
- 초기 사망 원인을 자동화하고 러시아 연방 (Tula, Vladimirskaya, Bryanskaya, Kirovskaya, Sverdlovskaya, Kurdlovskaya, Kurdlovskaya, Saratovskaya, Tyumen, Belgorod, Saratovskaya) Yaroslavl 지역, Krasnoyarsk 및 Stavropol Territory, Buryatia, Dagestan, Tyva, Udmurtia 및 Chuvashia, Yamalo-Nenets 및 Khanty-Mansiysk 자치 지구짐마자 이러한 프로그램의 복합체를 건강 관리로 도입하면 사망 원인의 정확성이 18 % 증가 할 수 있습니다.
우리는 새로운 증언을위한 지침을 동시에 발전시켜 사망 사망 및 주목 사망의 의학 증명서 개정에 대한 러시아 연방의 보건 사회 개발의 결정을 고려합니다.
동시에, 우리는 새로운 증거와 지침에 대한 토론을 위해 제시된 프로젝트가 정교함을 필요로한다고 믿습니다. 그들은 복잡하고 현재의 문서의 단점을 고치지 않았습니다.
우리는 다음과 같은 변경을하기 위해 새로운 의학적 인증 초안을 제공합니다.
- "라이브 __d, __ 개월, __days"를 제거하십시오. 왜냐하면 출생일과 사망 날짜가 기록 된 경우 회계 통계 문서를 복잡하게하지 마십시오.
- 마감일, 기부 및 문장의 기록을 제거 하고이 설명을 지시서로 전송하십시오.
- 죽은 임신 기간을 (37-41 주)로 대체하십시오. 왜냐하면 ICD-10에 따라, 데드 임신은 3 주 동안 3 주에서 42 주 (259-293 일) 미만으로 고려됩니다.
- 어머니의 날짜를 어머니의 연령대로 바꾸십시오 (가득 차있는);
- 항목 13 및 15를 제외하십시오 그는 단락 19를 복제합니다.
- 19 "죽음의 원인"단락에서 제거하십시오.
- 19 "죽음의 원인" 영어 편지 문자열 a), b), c), d) 러시아 문자 a), b), c), d);
- 19 "죽음의 원인"을 포함하여 ICD-10에서 권장되는 "병리학 적 과정의 시작과 사망 사이의 대략적인 기간"추가 그래프;
- 이전 크기가 이전까지 단락 20을 줄이고, 사망하는 해 동안 현재 임신과 임신에 대한 정보를 제한합니다. 왜냐하면 러시아는 20 항의 모든 정보를 얻을 수있는 모성 사망에 의해 모니터링됩니다.
지침 "19.11.84 ㎡1300의 USSR 보건부의 USSR 보건부의 순서에 따라 승인 된 의료 인증서 작성 및 발행 절차가 재발행이 아니 었음에도 불구하고 1998 년 러시아 보건부의 목회 241 호의 목회에 의한 승인 된 1998 년 106 / U-98.
의료 사망 인증을 작성하고 발행하는 절차에 대한 지시 사항의 개발 및 광범위한 구현은 관련성이 있습니다. 왜냐하면 그것은 오류의 10 %를 줄이고 러시아 인구 인구의 사망 원인의 신뢰성을 높이는 데 기여할 것입니다.
초안 지시는 1998 년 러시아의 보건부의 CNIIMI의 CNIIMI에서 개발 된 사망 증명서를 작성하고 발행하는 절차에 기초하여 제작되었으며, 일반적으로 ICD- 10.
그러나 사망 원인의 신뢰성을 높이기 위해서는 누가 권고 사항에 따라, 우리는 초안 교육에 대한 지침을 제안하도록 제안합니다.
- 의사가없는 경우 평균 의료진 (Feldeshu, Empstetric)이 의사가없는 사망 인증서를 작성하고 "의료 조직의 의료 기관이없는"의료 요원의 의학적 조직이없는 "기록을 대체 할 수있게하십시오. 직원에 의사가있는 경우에는 육체적으로는 아닙니다. 휴가, 병원 등입니다.
- 정의를 "조기", "댄디"를 옮기고 인증서에서 37 ~ 41 주 임신 마감일을 수정하여 지침서로 전송합니다.
- 사고, 중독 및 부상, HIV 감염 및 산부인 감염 및 산부 침해성의 예외를 제외하고 "사고와 관련된 임신이 발생한 경우"사고, 중독 및 부상의 결과를 포함하여 "입장료 포함" 모성 사망의 이러한 이유로 죽음은 포함되지 않습니다.
- 실시 예 5, 7, 10 및 13의 수정 코드 수정
연구 중에, 문서 충전의 정확성을 결정하고, 자녀의 기본 질병 (주)을 코딩하고, 사망하고, 사망 한 어머니의 주요 질환을 코딩하고 선택하고, 아이에게 악영향을 미칩니다. 전문가 평가는 별도로 활기차고 강판 된 어린이를 수행했습니다. 사망 원인을 작성하고 소유의 원인을 작성할 때 훨씬 더 많은 오류가 확인되었습니다.
"죽음의 원인"제 18 항의 오차는 5 그룹으로 그룹화되었다 (각각 툴라 지역 및 stavropol 지역) :
- 주목 사망 의료증을 작성할 때 "(18.9 ~ 40.5 %),
- 어린이의 주요 질환 (10.8-20.3 %)을 선택할 때,
- 어린이에게 악영향을 미친 어머니의 주요 질환을 선택할 때 (62,2-60.8 %),
- 아이의 주요 질환 (73-77 %)의 코더의 선택에서,
- 어머니의 주요 질환의 코드 (67.5-91.9 %)의 코드 선택
따라서 연구의 결과로, Tula 지역의 주목 사망의 의료 증명서를 수집하고 가공하는 기존 시스템과 Stavropol Territory는 사망 원인의 통계적 지표의 정확성을 보장하지 못했습니다.
주 산성 사망률 통계의 신뢰성의 증가에 영향을 미치는 중요한 요소 중 하나는 회계 시스템의 구조 조정이며 국제 규칙과의 라인에 가져 오는 것입니다.
러시아의 보건부가 제안한 주요 사망 의료진의 진료소는 새로운 주목 기간으로의 전환을 지정했으며, 개별 품목은 누구와 해당 ICD-10이 권장하는 삶의 징후에 추가되었습니다.
새로운 주목 기간으로의 전환은 우리가 500g에서 999g의 체중을 가진 과일의 2 %로 태어 났지만 선진국의 지표가있는 지표의 비교 가능성을 보장 할 것입니다. ...에
동시에 우리는 주요 사망의 의료 증명서로 편집을하기로 제안합니다.
- 출생 후 처음 0-6 일 (169 시간) 동안 사망 한 공유 및 실물에서 가득 찬 기록을 제거 하고이 항목을 지침으로 전송하십시오.
- "과일"이라는 단어의 모든 간증에서 제외되며, 이전의 임신과 관련된 포인트가 남아서 주목 사망의 의료 증명서는 채워지지 않습니다.
- 제 6 항의 제외, 시체의 검사를 기준으로 "죽음의 의사"라는 단어는 나중에 획득 될 수 있습니다. "라는 지침에는 주목할 모든 사례를 설명해야합니다. 죽음을 열어야하며 추가 연구가 필요하다면 예비적인 증거를 규정했습니다.
우리는 적절한 것으로 간주합니다. 동시에 주목 사망의 의학적 사망의 시민 지위의 행위와 주목에있는 어린이의 사망 등록의 시민 지위의 행위 작품을 작성하고 제출하는 절차에 관해 적절하게 적절하다고 생각합니다. 기간"
참신한 제안 된 프로젝트는 출생 후 7 일 동안 태아의 자궁 내부 생활 22 주간의 새로운 주 산과 전환하는 것입니다.
새로운 주목 기간으로의 전환은 어린이와 태아의 개념에 대한 새로운 정의로의 전환을 수반합니다. 그리고 이것은 이전에 500에서 999g까지 체중을 가진 과일을 가진 과일은 아동으로 간주 될 것이며 출생과 사산 후 7 일 동안 사망 한 사람들을 포함하여 고속 등록의 대상이됩니다.
perinatal 사망률의 통계의 정확성을 높이기 위해서는 태아의 자궁 내 생명의 22 주 정도의 주목 기간을 계산하면 "어린이"와 "태아"의 개념에 대한 다음 정의를 포함 시키려면 출생 후 7 일 동안.
어린이는 완전한 망명이나 출생시 신체의 체중을 가진 어머니의 신체에서 500g 이상으로 체중으로 추출한 후 인간 개념의 산물입니다. 22 주 이상 임신 한 기간, 신체 길이 25cm 이상 1 층이나 복수 출산에 관계없이 발 뒤꿈치에 패턴을 팁.
과일은 499 g 이하의 출생시 체중 체중을 가진 어머니의 몸에서 완전한 망명지 또는 추출한 인간의 개념의 산물이며, 신체 길이는 25cm 미만인 경우 체중이 499 g 이하인 것입니다. 한 구외의 출생이나 여러 출생에 관계없이 패턴의 끝에서 발 뒤꿈치까지.
"어린이"또는 "태아"를 결정하는 선도적 인 기준은 신체의 질량이지만 신체가 출생시 알려지지 않은 몸을 갖는 경우 임신 기간을 결정하기위한 해당 기준을 사용하거나 신체 길이를 발 뒤꿈치에 패턴 끝.
우리는 초안 교육을 변경하도록 제안합니다.
- "Perinatal Death의 의료 인증서 (F.106 / 2U-98)는 출생 후 0-6 일 (169 시간) 동안 사망 한 어린이, 소유의 병아리 (169 시간)에 가득 차 있습니다.
- 이전 임신과 관련된 사례를 제외하고 "과일"이라는 단어의 지시에 제외됩니다.
- 다음 인스톨린 된 문서 디자이너 추가 :
- "과일"은 출생과 주목 사망 의료 증명서를 발급하지 않습니다. "과일"은 등록 대상이 아닙니다.
- 죽은 자식 "아이"는 주목 사망 의료 증명서를 발급하고 출생 증명서가 기록되지 않습니다.
- 삶의 첫 주에 태어난 "어린이"에서 동시에 태어났다. 동시에, 동시에, 동시에, 동시에, 동시에, 동시에, 동시에, 탄생의 의료 증명서와 주산 사망 의료증이 발행된다.
- q00-Q99에 선천적 인 이상도의 수정;
- 실시 예 4 및 5의 텍스트 및 수정 코드를 개선하십시오.
따라서 사망률 통계 문서의 향상은 10 %의 신뢰성을 증가시킬 수있는 요인 중 하나이며 인구 통계 학적 지표의 국제 비교를 허용하는 사람이 권장하는 주 산동 기간으로의 전이 중 하나입니다. 새로운 주목 기간으로 전환 한 후, "어린이"와 "과일"의 개념을 결정하는 것이 중요합니다.
조회수 : 99840.
|
이 리뷰는 미국 교수 D. Morgan의 체계적인 책에 대해 알려줍니다. 고품질 및 양적 방법의 통합, 연구 설계 옵션의 통합에 대해 자세히 설명합니다.
Strekalova N. D. 북부 경제 경제의 기업 지배 구조 및 혁신적인 개발 : 기업 법, 경영 및 벤처 투자 Syktyvkar 연구 센터의 게시판 주립 대학교...에 2014. 4. P. 184-197.
이 기사는 사례 방법의 본질을 연구 전략, 방법론의 기본 사항 및 관리에 대한 설계 연구의 기초를 보여줍니다. 경영학 석사의 과학적 연구를 수행하는 경우에 사용하는 경우의 강점과 약점이 고려됩니다. 제공된다 비교 특성 연구 및 훈련 사례. 연구 조직의 경험이 강조되고, 문제, 기회 및 관리 마스터의 연구 역량을 형성하는 경우의 사용법을 사용하기위한 전망이 논의됩니다. 결론적으로 주어진다 실용적인 권고 사례 방법을 기반으로 한 경영학 석사의 과학 연구 조직에서. 이 기사는 교육 및 연구 사례의 비교 분석, 방법론 및 설계 설계에 대한 설명으로 사례 단계의 강점과 약점을 연구 방법으로 확인합니다.
이 연구에서는 유럽 문제의 문제의 문제에 대한 방법 론적 해결책 " 엔.\u003d 1 "비교 연구를 수행하는 데 겉으로보기에는 불가능한 EU의 고유성 문제. 그러나 유럽 연구에 비교 정치 과학의 침투와 새로운 지역주의 하에서 EU의 연구는 비교 방법을 사용하여 기사 수의 서지를 이끌어 냈습니다. 4 명의 과학적 저널의 분석은 이러한 추세가 영어를 구사하지만 러시아 잡지가 아닌 특징 인 것을 보여줍니다.
Savinskaya O. B. 이 책에서 : 사회학 및 사회 : 사회적 불평등 및 사회 정의 (Ekaterinburg, 2016 년 10 월 19 일 21 일). v 모든 러시아 사회 의회의 재료. 미디엄.: 러시아 학회 사회 학자, 2016. P. 8467-8475.
이 작품은 사회적 연구를 철저히 연구하기 위해 데이터를 수집하고 분석하는 고품질 및 양적 방법의 조합을 가정하는 새로운 방법 론적 접근 방법 (혼합 방법 연구)의 새로운 방법 론적 접근 방식의 방법 론적 반영입니다. 현상. 이 보고서는 믹싱 방법 (MMR)의 믹싱 방법 개발, 멀티 흐름 연구 연구 설계의 용어 및 현재 분류의 러시아어 번역에 대한 논의에 대한 주요 단계에 대해 설명합니다. 업적 및 해결되지 않은 문제는 기사의 마지막 부분에서 지정됩니다.
첫 번째 단계에서 디자인은주의 깊게 해결됩니다 (영어로부터). 디자인.- 창의적인 아이디어) 미래의 연구.
우선 연구 프로그램이 개발되었습니다.
프로그램 연구, 공식화 된 가설, 연구 개체, 단위 및 관측의 용어, 선택적 집계, 수집, 저장, 처리 및 데이터 분석의 형성을위한 통계 방법 설명 , 파일럿 연구의 방법론, 사용 된 통계 도구 목록 인 파일럿 연구를위한 방법.
이름 주제 그것은 일반적으로 한 문장으로 공식화되어 연구의 목적을 준수해야합니다.
공부의 목적- 이것은 특정 기금으로 활동 및 방법의 결과와 방법의 정신적 기대입니다. 원칙적으로 의료 및 사회 연구의 목적은 이론적 (인지)뿐만 아니라 실용적인 (적용) 캐릭터가 아닙니다.
목표를 구현하기 위해 결정됩니다 연구 작업, 콘텐츠 내용을 밝혀냅니다.
프로그램의 가장 중요한 구성 요소는입니다 가설 (예상 결과). 가설은 특정 통계 지표를 사용하여 공식화합니다. 가설에 대한 주요 요구 사항은 연구 과정에서 그들을 확인하는 능력입니다. 연구 결과는 확장 된 가설을 확인하고 조정하거나 반박 할 수 있습니다.
재료를 수집하기 전에, 물체와 관찰 유닛이 결정됩니다. 아래에 의료 및 사회 연구의 대상 상대적으로 균질 한 개별 개체 또는 현상 - 관찰 단위로 구성된 통계적 응집체를 이해하십시오.
관측 단위- 통계적 집합체의 기본 요소는 연구 될 모든 징후로 부여됩니다.
연구 준비의 다음 중요한 작동은 작업 계획의 개발 및 승인입니다. 연구 프로그램이 전략적 의도의 일종 인 경우 연구원의 아이디어를 구현하는 것, 그 일 계획 (프로그램에 대한 응용 프로그램으로서) 연구를 수행하는 메커니즘입니다. 작업 계획에는 다음이 포함됩니다 : 즉시 수행자의 작업의 선택, 훈련 및 조직의 순서; 규제 및 방법 론적 문서의 개발; 연구 (인력, 금융, 물류, 정보 자원 등)에 대한 필요한 양의 규정 및 유형의 결정; 연구의 정의 및 연구의 개별 단계에 대한 책임. 규칙으로서 그것은 형태로 보입니다 네트워크 그래픽.
의료 및 사회 연구의 첫 단계에서는 관찰 단위로 선택되는 방법을 결정합니다. 볼륨에 따라 고체 및 샘플 연구가 구별됩니다. 지속적인 연구를 통해 일반 인구의 샘플 만 (샘플)의 샘플만으로 연구됩니다.
일반 배려하나 또는 특징 그룹이 결합 된 질적으로 균질 한 관찰 단위를 많이 부여하십시오.
선택적 집계 (샘플)- 일반 인구 관찰 단위의 모든 부분 집합.
일반 인구의 특성을 완전히 반영하는 선택적 집합체의 형성은 통계적 연구의 가장 중요한 임무입니다. 선택적 데이터에 대한 일반적인 집계에 대한 모든 판단은 대표 샘플에만 유효합니다. 특성이 일반 인구의 지표에 해당하는 샘플의 경우
샘플링의 실제 공급이 보장됩니다 무작위 선택으로, 그. 선택되는 일반 인구의 모든 물체가 동일한 샘플에서의 관찰 단위의 선택이 동일합니다. 지정된 원칙 또는 임의의 숫자 테이블을 구현하는 특수 설계된 알고리즘은 선택이 사용되거나 많은 컴퓨터 프로그램 패키지에서 사용할 수있는 난수 생성기를 보장하는 데 사용됩니다. 이러한 방법의 본질은 정렬 된 일반 인구의 전체 방식에서 선택 해야하는 객체의 무작위로 숫자를 지정하는 것입니다. 예를 들어, 일반적인 집계 "영역의 인구"는 나이, 거주지, 알파벳 (성, 이름, 무언가) 등으로 간소화 될 수 있습니다.
의학 및 사회 연구의 조직 및 실시 예와의 무작위 선택과 함께 샘플 세트를 형성하는 다음 방법이 또한 사용됩니다.
기계 (체계적) 선택;
형식적 인 (Stratified) 선택;
일련 선택;
다단 (스크리닝) 선택;
코호트 방법;
메소드 "복사기".
기계 (체계적) 선택주문한 일반 인구의 관찰 단위의 선택에 대한 기계적 접근 방식을 사용하여 샘플을 형성 할 수 있습니다. 동시에 선택적 및 일반 집합의 양의 비율을 결정할 필요가 있으며 선택의 비율을 설정해야합니다. 예를 들어, 입원 환자의 구조를 연구하기 위해 병원에서 떠난 모든 환자의 20 %가 형성됩니다. 이 경우, 숫자로 주문한 모든 "입원 환자의 의료 맵"(F. 003 / Y) 중 각 5 번째 카드를 선택해야합니다.
형식적 인 (Stratified) 선택적절한 것은 전형적인 그룹 (지층)에 대한 일반 인구를 부러 뜨립니다. 의학 및 사회 연구를 실시 할 때, 연령, 사회, 전문 단체, 개인 정착촌뿐만 아니라 도시 및 농촌 인구가 알고 있습니다. 동시에, 각 그룹의 관찰 단위의 수는 샘플에서 그룹 번호 수에 비례하여 샘플에서 선택됩니다. 예를 들어, 인구의 위험 인자와 인구의 종양 학적 이환율의 인과 관계를 연구 할 때, 그들은 나이, 성별, 직업, 사회적 지위에 의한 하위 그룹에 대해 연구 된 그룹에 의해 사전 나누어 져야합니다. 각 하위 그룹에서 필요한 관찰 수를 선택하십시오 단위.
일련의 선택샘플은 개별 관찰 단위로부터 형성되지 않지만 에피소드 또는 그룹 전체 (시정촌, 건강 관리 기관, 학교, 유치원 등). 시리즈 선택은 무작위 또는 기계 샘플링을 사용하여 수행됩니다. 각 시리즈 내부에는 모든 관찰 장치가 연구됩니다. 이 방법은 예를 들어, 어린이 인구의 예방 접종 효과를 평가하는 것으로 사용할 수 있습니다.
다단 (스크리닝) 선택샘플의 단계적 형성을 보장합니다. 스테이지의 수에 의해 단일 단계, 2 단계, 3 단계 선택 등이 있습니다. 예를 들어, 시정촌 영토에 사는 여성의 생식 건강을 연구 할 때, 첫 번째 단계에서는 근무 여성이 기본적인 스크리닝 테스트로 선택됩니다. 두 번째 단계에서 3 단계에서 아이들과 함께하는 여성에 대한 전문 설문 조사는 선천성 기형을 가진 어린이를 가진 여성에 대한 심층적 인 전문 설문 조사입니다. 이 경우 샘플에서 특정 로그인에 대한 대상 선택은 자치 단체의 영역에서 공부 된 서명의 항공사를 포함합니다.
코호트 방법동일한 시간 간격으로 특정 인구 통계 학적 이벤트의 발병에 의해 유나이티드의 균질 그룹 그룹에 관한 통계적 집합체를 연구하는 데 사용됩니다. 예를 들어, 불임 문제와 관련된 문제를 공부할 때, 일자일 (세대에 대한 다산 연구) 또는 결혼 생활의 단일 연령에 기초하여 전체 (코호트), 균질 한 전체 (코호트), 균질을 형성하십시오 (연구 가족 생활 기간에 대한 불임).
몇 가지 몇 가지 방법하나 이상의 특징 ( "COP-Steam")에 가까운 물체 그룹의 연구의 각 관찰 단위에 대한 선택을 제공합니다. 예를 들어, 본체의 질량과 자녀의 성관계와 같은 인자가 유아 사망률의 수준에 영향을 미치는 것으로 알려져 있습니다. 1 세 미만의 어린이 중 1 년 동안 어린이가 1 년 이내에 자녀의 사망의 각 사건에 대해이 방법을 사용할 때, 연령 및 체중과 유사한 동일한 섹스의 "커플 복사"가 선택됩니다. 이 선택 방법은 사회적으로 중요한 질병의 개발, 사망의 특정 원인을 개발하기위한 위험 요소를 연구하는 데 적용되는 것이 좋습니다.
연구의 첫 번째 단계에서 (준비가 된 것) 및 복제도 개발되었습니다. 통계 툴킷 (카드, 설문지, 테이블 레이아웃, 컴퓨터 프로그램 수신 정보, 정보 데이터베이스의 형성, 형성 및 처리 등을 제어합니다.) 또한 정보에도 입력됩니다.
보건 시스템의 공중 보건 및 활동 연구에서는 종종 사용합니다. 사회학 연구 특별한 설문지 (설문지)를 사용합니다. 설문지 (설문지) 의료 및 사회학 연구를 위해 목표, 지향 자연은 착용되어야하며, 자료의 신뢰성, 정확성 및 대표성을 보장해야합니다. 설문지 및 인터뷰 프로그램의 개발 중에 다음 규칙을 따라야합니다. 필요한 정보를 수집, 가공 및 추출하기위한 설문지의 적합성을 준수해야합니다. 실패한 문제를 제거하고 적절한 조정을하는 설문지를 수정할 수있는 능력을 수정할 수 있습니다. 연구의 목표와 목적에 대한 설명; 다양한 추가 설명의 필요성을 제외한 문제의 명확한 문구; 대부분의 질문의 자연이 수정되었습니다.
숙련 된 선택과 다양한 종류의 질문의 조합 - 개방, 폐쇄 및 반 폐쇄 - 얻은 정보의 정확성, 완전성 및 신뢰성을 크게 증가시킵니다.
설문 조사 및 그 결과의 품질은 설문지 설계의 기본 요구 사항 인 그래픽 디자인의 기본 요구 사항에 크게 의존합니다. 설문지 구축을위한 다음과 같은 기본 규칙이 있습니다.
설문지에는 조사를 실시하지 않고 다른 방식으로 얻을 수없는 연구의 주요 목적을 해결하는 데 필요한 정보를 얻는 데 도움이되는 답변이 가장 중요한 문제 만 포함됩니다.
그들과 그들의 모든 단어의 말씀은 응답자가 이해하고 지식과 교육의 수준에 해당해야합니다.
설문지에는 꺼리는 문제가 포함되어서는 안됩니다. 모든 질문이 응답자의 긍정적 인 반응과 완전하고 진정한 정보를 제공하고자하는 욕구라고 불리는 것을 보장하기 위해 노력해야합니다.
조직 및 문제의 서열은 목표를 달성하고 연구에서 설정된 작업을 해결하기 위해 가장 필요한 정보를 얻는 데 종속되어야합니다.
특별한 설문지 (설문지)는 하나 이상의 질병 환자의 삶의 질을 평가하는 것을 포함하여 널리 사용되며, 그들의 치료의 효과. 그들은 상대적으로 짧은 기간 (보통 2-4 주)에서 발생한 환자의 수명으로 변화를 잡을 수있게합니다. 급성 심근 경색 환자를위한 기관지 천식, QLMI (심근 경색 설문지의 삶의 질)에 대한 AQLQ (천식 설문지의 천식 품질) 및 AQ-20 (20 항목 천식 설문지) 등 많은 특별한 설문지가 있습니다.
설문지의 개발 및 다양한 언어 및 경제적 형성에 대한 적응에 대한 작업 조정은 삶의 질에 대한 연구를위한 국제 비영리 단체 (프랑스)에 의해 관리됩니다.
이미 통계적 연구의 첫 번째 단계에서, 획득 된 데이터에 의해 나중에 채워질 테이블의 레이아웃을 컴파일해야합니다.
테이블과 같은 테이블에서 문법 제안, 주제와 구별, 즉. 주요한 것은 테이블에서 말한 것입니다. 그리고 마른, 즉. 주제를 특징 짓는 것은 무엇입니까? 제목 - 이것은 연구 된 현상의 주요 표시입니다. 일반적으로 테이블의 왼쪽 수평 문자열에 있습니다. 술부 - 피사체를 특징 짓는 징후는 보통 수직 그래프 그래프의 상단에 있습니다.
테이블을 그리는 경우 특정 요구 사항을 준수 할 때 :
테이블에는 본질을 반영하는 명확하고 간단한 제목이 있어야합니다.
테이블 디자인은 그래프와 선의 결과로 끝납니다.
테이블에 빈 셀이 없어야합니다 (기호가 없으면 대시를 넣습니다).
간단하고 그룹 및 조합 (복잡한) 유형의 테이블을 구별하십시오.
단순은 테이블이라고 불리우며, 하나의 기능의 최종 데이터 요약 (표 1.1).
표 1.1.간단한 테이블의 레이아웃. 건강 그룹에 의한 어린이의 배포, 결과에 대한 %
그룹 테이블은 비 상호 연결 (표 1.2)의 여러 범례가 특징 지어집니다.
표 1.2.그룹 테이블의 레이아웃입니다. 건강, 성별 및 연령의 그룹에 의한 어린이의 배포, 결과에 %

조합 테이블에서 피사체를 특징 짓는 특징은 상호 관련되어 있습니다 (표 1.3).
표 1.3.조합 테이블에 조롱. 건강, 연령 및 성별의 그룹의 어린이의 배포, 결과에 %

준비 기간에 중요한 장소가 필요합니다 파일럿 연구 이 작업은 데이터를 수집하고 처리하는 개발 된 방법의 정확성을 확인하는 통계 도구를 테스트하는 것입니다. 이러한 파일럿 연구는 가장 성공적이며, 이는 감소 된 규모의 주요 규모를 반복합니다. 모든 다가오는 작업 단계를 확인할 수 있습니다. 파일럿 중에 얻은 데이터의 예비 분석 결과에 따라 통계 계측기, 정보 수집 및 처리 방법이 조정됩니다.